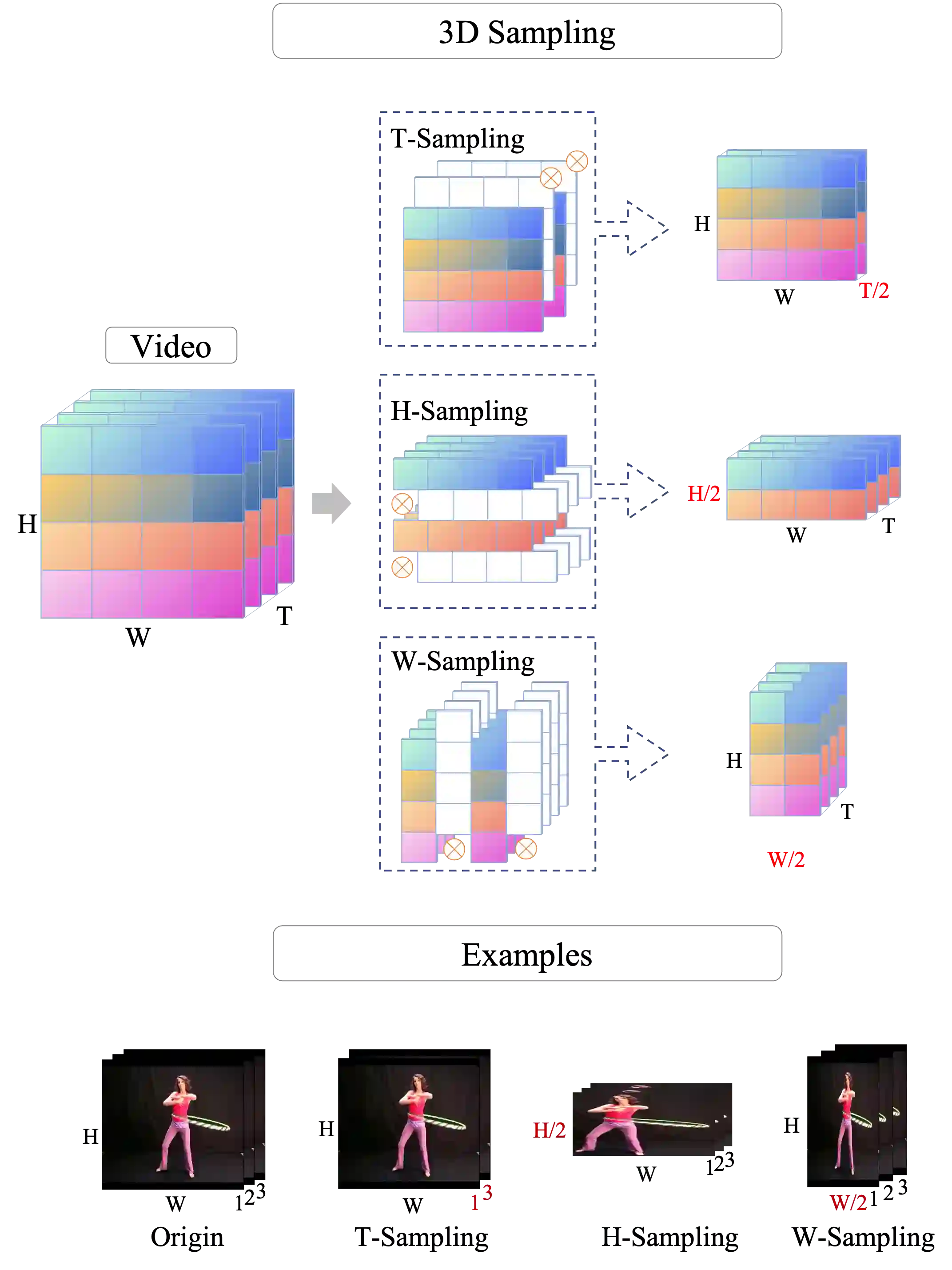
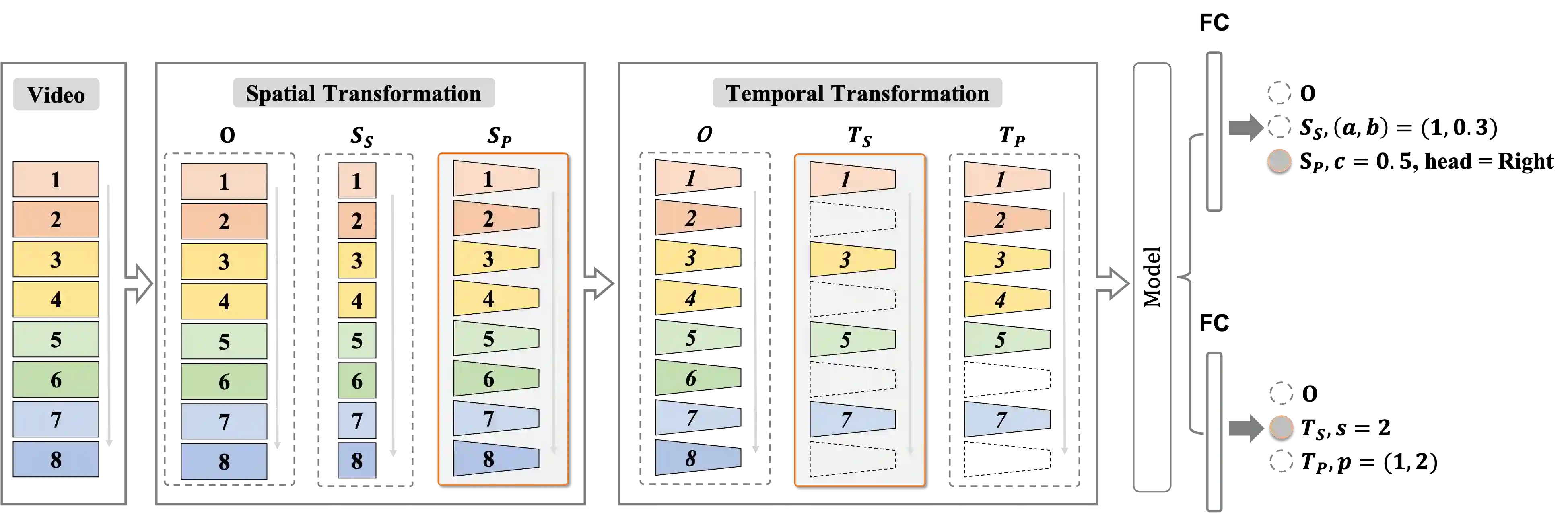
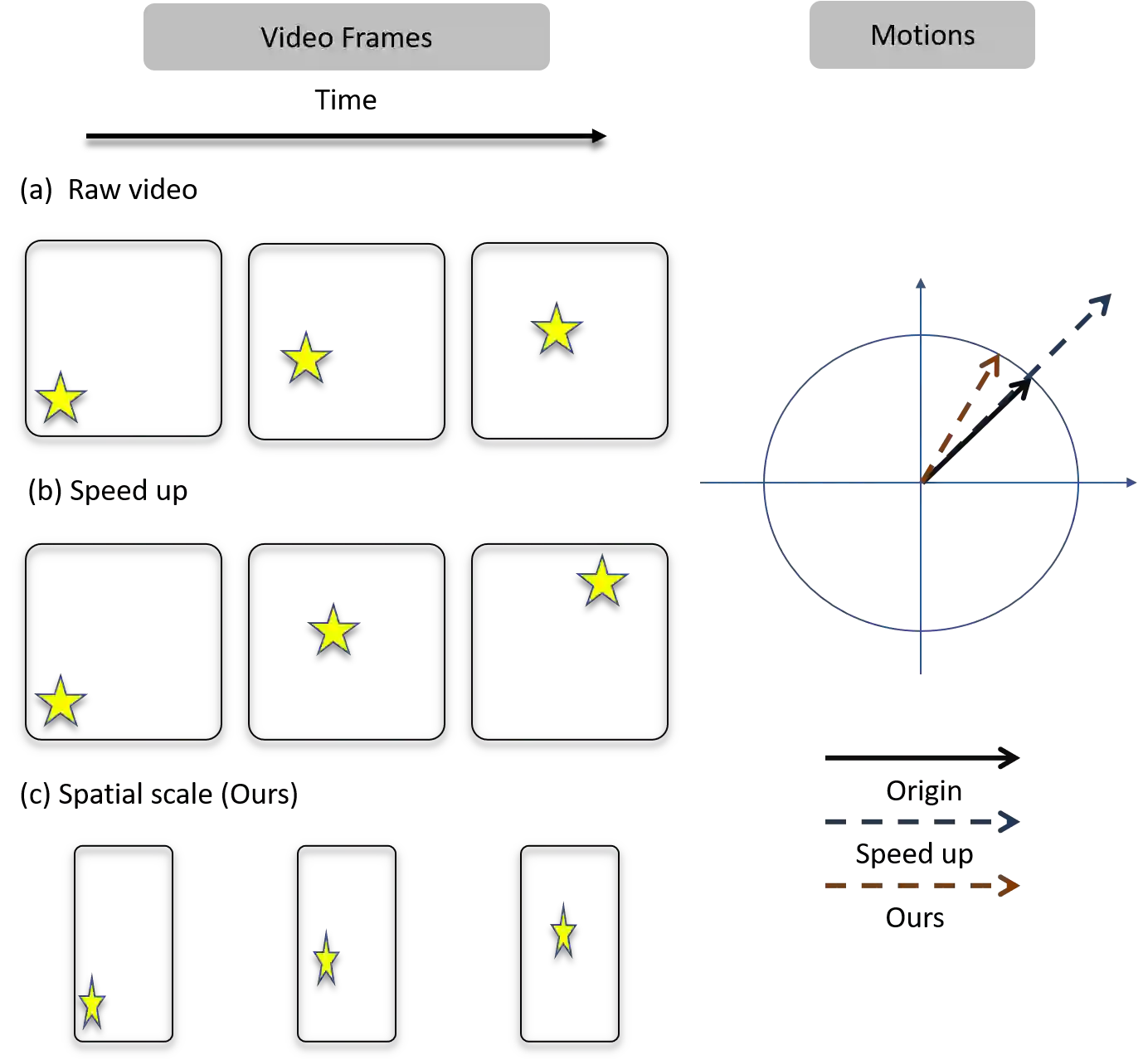
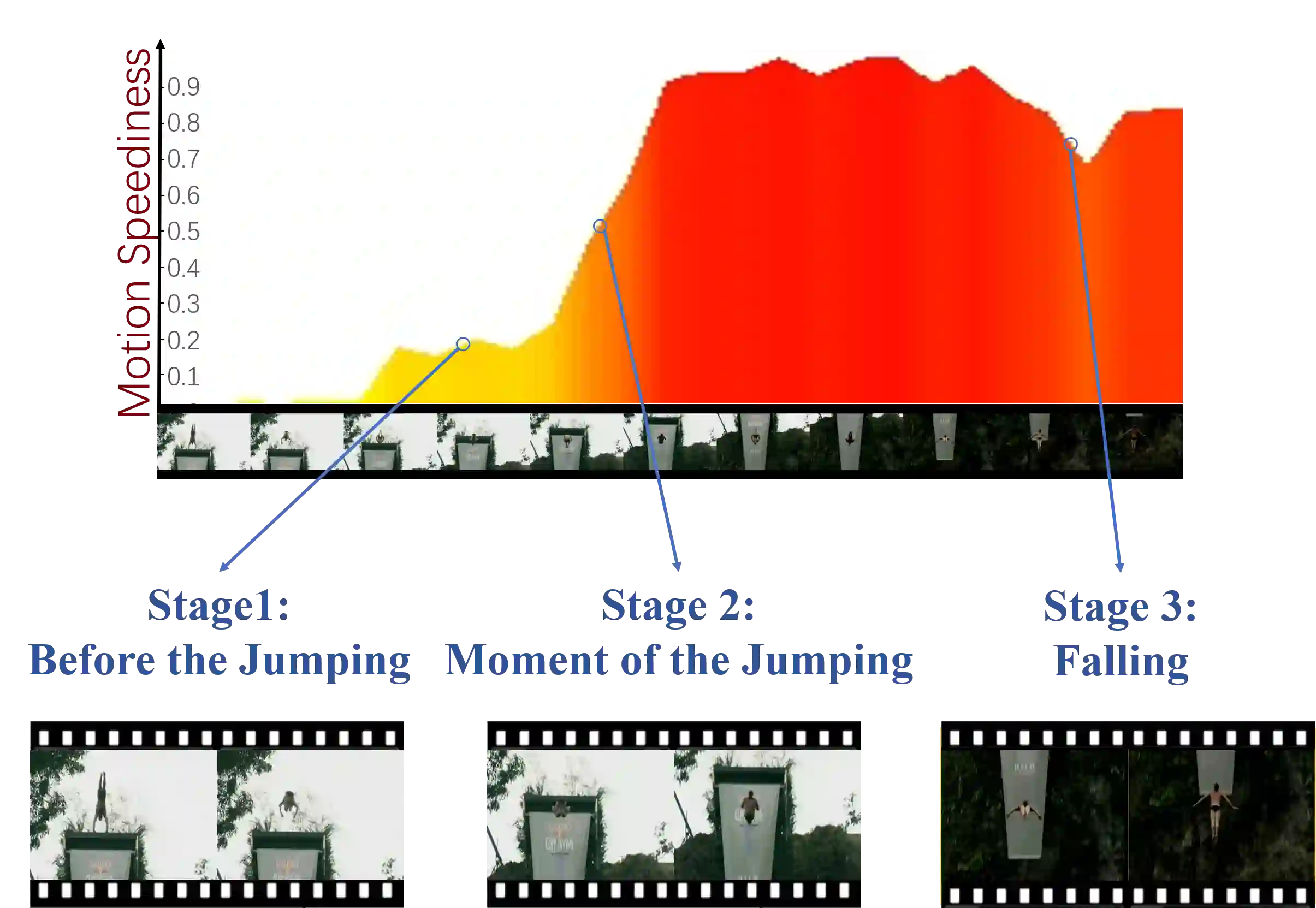
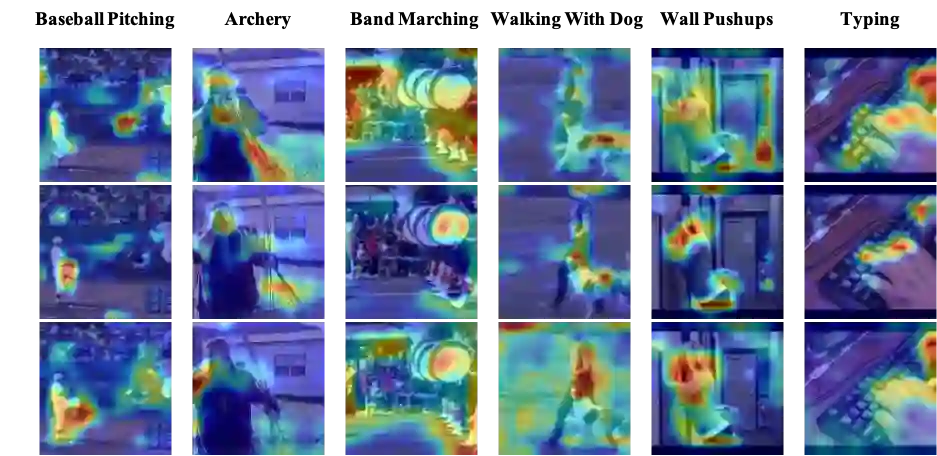
Most of the existing video self-supervised methods mainly leverage temporal signals of videos, ignoring that the semantics of moving objects and environmental information are all critical for video-related tasks. In this paper, we propose a novel self-supervised method for video representation learning, referred to as Video 3D Sampling (V3S). In order to sufficiently utilize the information (spatial and temporal) provided in videos, we pre-process a video from three dimensions (width, height, time). As a result, we can leverage the spatial information (the size of objects), temporal information (the direction and magnitude of motions) as our learning target. In our implementation, we combine the sampling of the three dimensions and propose the scale and projection transformations in space and time respectively. The experimental results show that, when applied to action recognition, video retrieval and action similarity labeling, our approach improves the state-of-the-arts with significant margins.
翻译:大多数现有的视频自我监督方法主要是利用视频的时间信号,忽视移动对象和环境信息的语义对于视频相关任务都至关重要。在本文中,我们提出了一种新的自我监督的视频代表学习方法,称为视频 3D 抽样(V3S ) 。 为了充分利用视频中提供的信息(空间和时间),我们从三个层面(宽度、高度、时间)预处理视频。因此,我们可以利用空间信息(物体大小)、时间信息(运动的方向和规模)作为我们的学习目标。我们在执行过程中,将三个层面的抽样结合起来,并分别提出空间和时间的规模和预测变化。实验结果显示,在应用到行动识别、视频检索和动作相似性标签时,我们的方法将显著的边际改进了状态。