
题目: Self-supervised learning for audio-visual speaker diarization
摘要:
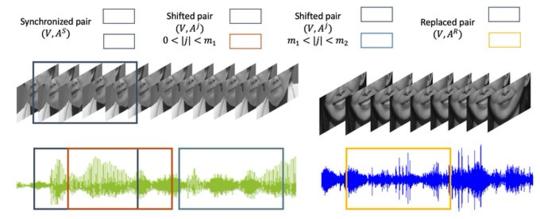
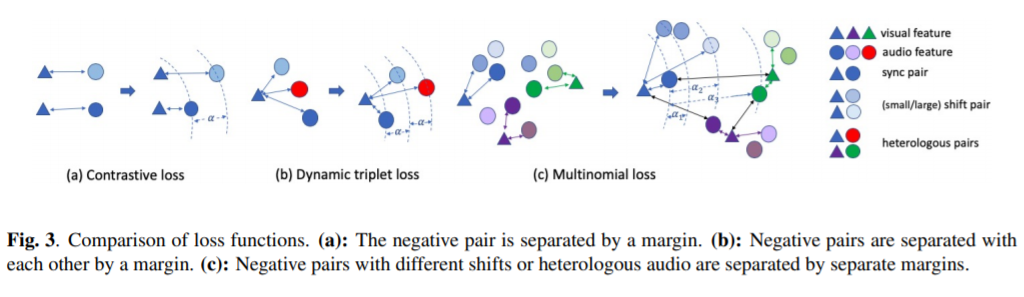
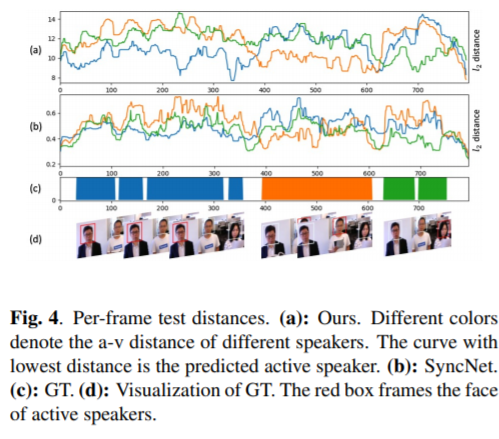
主讲人二值化是一种寻找特定主讲人语音片段的技术,在视频会议、人机交互系统等以人为中心的应用中得到了广泛的应用。在这篇论文中,我们提出一种自监督的音视频同步学习方法来解决说话人的二值化问题,而不需要大量的标注工作。我们通过引入两个新的损失函数:动态三重损失和多项式损失来改进前面的方法。我们在一个真实的人机交互系统上进行了测试,结果表明我们的最佳模型获得了显著的+8%的f1分数,并降低了二值化的错误率。最后,我们介绍了一种新的大规模的音视频语料库,以填补汉语音视频数据集的空白。
成为VIP会员查看完整内容
相关内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
39+阅读 · 2020年1月30日
专知会员服务
14+阅读 · 2019年11月11日



相关VIP内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
39+阅读 · 2020年1月30日
专知会员服务
14+阅读 · 2019年11月11日
相关资讯
相关论文