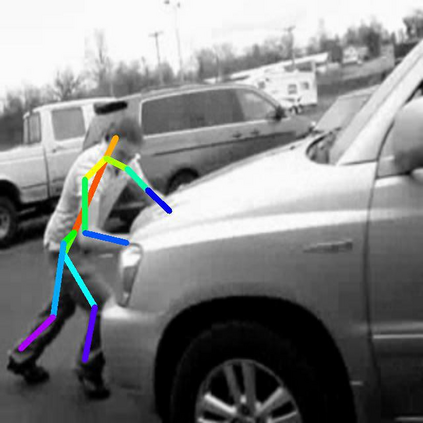
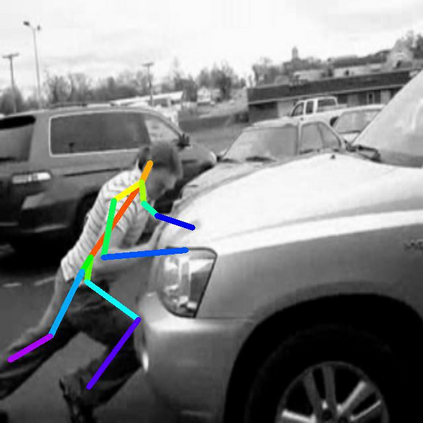
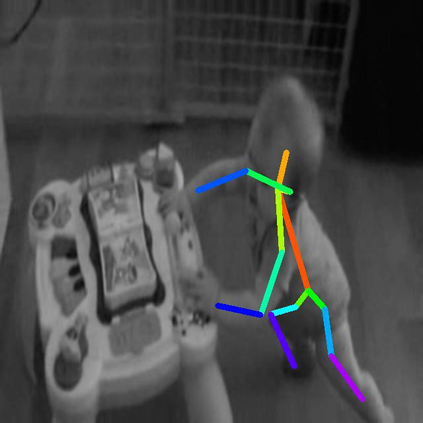
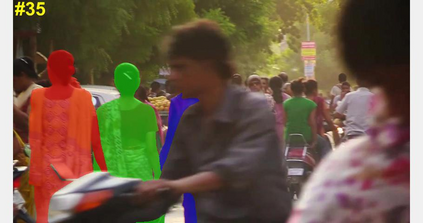In this paper, we focus on the self-supervised learning of visual correspondence using unlabeled videos in the wild. Our method simultaneously considers intra- and inter-video representation associations for reliable correspondence estimation. The intra-video learning transforms the image contents across frames within a single video via the frame pair-wise affinity. To obtain the discriminative representation for instance-level separation, we go beyond the intra-video analysis and construct the inter-video affinity to facilitate the contrastive transformation across different videos. By forcing the transformation consistency between intra- and inter-video levels, the fine-grained correspondence associations are well preserved and the instance-level feature discrimination is effectively reinforced. Our simple framework outperforms the recent self-supervised correspondence methods on a range of visual tasks including video object tracking (VOT), video object segmentation (VOS), pose keypoint tracking, etc. It is worth mentioning that our method also surpasses the fully-supervised affinity representation (e.g., ResNet) and performs competitively against the recent fully-supervised algorithms designed for the specific tasks (e.g., VOT and VOS).
翻译:在本文中,我们侧重于使用野生未贴标签的视频进行视觉通信自我监督学习。 我们的方法同时考虑视频内和视频间的代表协会,以便进行可靠的通信估计。 视频内学习通过框架双向亲和关系将图像内容在单一视频中转换成跨框架的图像内容。 为了获得歧视性代表,例如层次的分离,我们超越了视频内分析,构建了视频间亲近关系,以便利不同视频之间的对比性转变。 通过迫使视频内和视频间水平之间的转变一致性,精细的通信协会得到了很好的保存,实例性特征歧视得到了有效的加强。 我们简单的框架超越了最近为具体任务设计的、包括视频对象跟踪(VOT)、视频对象分割(VOS)等一系列视觉任务上自我监督的通信方法。 值得指出的是,我们的方法也超过了完全超强的亲近性代表(例如ResNet),并针对最近为具体任务设计的完全超标的算算法(例如VOT和VOS)。