今天跟大家聊一聊ICLR 2022微软亚研院的一篇工作BEIT: BERT Pre-Training of Image Transformers(ICLR 2022)。BEIT是一种图像无监督预训练,属于最近非常火的Vision Transformer这类工作的研究方向(Vision Transformer前沿工作详细汇总可以参考历史文章从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程)。首先简单介绍一下这篇文章的整体思路:利用BERT中MLM(Masked Language Modeling)的思路,把一个图像转换成token序列,对图像token进行mask,然后预测被mask掉的图像token,实现图像领域的无监督预训练。
这个想法听起来跟BERT没有太大区别,但是想把这个思路成功应用到图像领域,并且取得效果,就不是那么容易了。接下来我们走进BEIT,看看这篇工作是如何实现将MLM预训练应用到图像领域的。我们首先介绍BEIT的原理,再对比BEIT和历史的Vision Transformer工作,如iGPT、ViT等,看看BEIT有哪些优越之处。
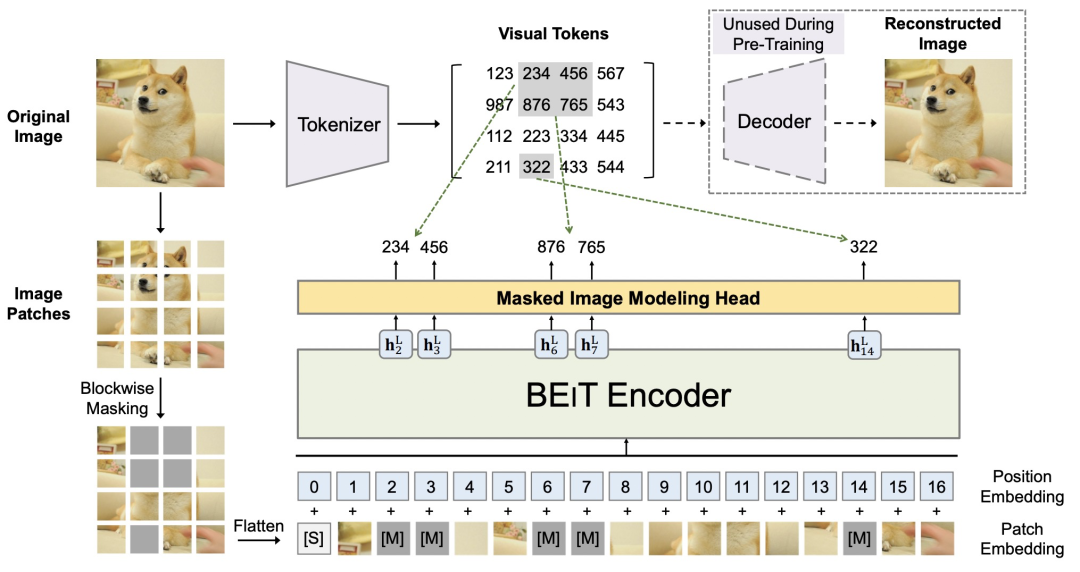
BEIT主要分为dVAE和基于Vision Transformer的MIM(Masked Image Modeling)两个部分
。其中,dVAE用来实现将图像转换为图像token,Vision Transformer部分使用ViT作为backbone对图像进行编码,并对mask掉的图像token。BEIT整体的模型结构如下图所示。下面我们对模型结构进行详细介绍。
想把MLM应用到图像领域,遇到的第一个问题就是怎样把图像数据转换成NLP中离散化的token。一种替代方法是采用回归的方式进行MLM,例如预测每个被mask掉元素的像素值。但是这种方式会使模型过于关注细节信息,而缺少对图像整体结构的学习能力。BEIT采用dVAE实现将图像离散化成图像tokenBEIT整体的模型结构如下图所示。下面我们对模型结构进行详细介绍。
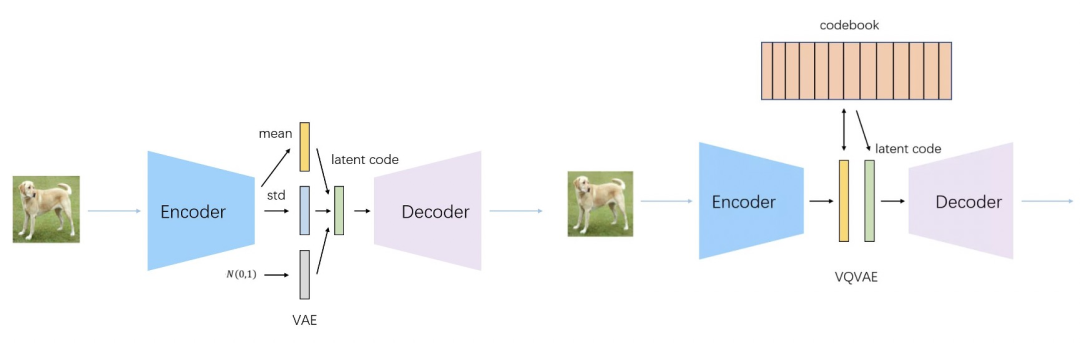
想实现在图像上应用MLM,一个前提条件是将图像转换成离散化的图像token。BEIT采用了Zero-Shot Text-to-Image Generation(2021)这篇文章中介绍的思路,利用dVAE将图像转换成token。这里简单介绍一下dVAE的原理。普通的VAE主要用于生成任务,采用类似于AutoEncoder的框架,利用Encoder将输入数据映射到0均值1方差的高斯分布,再从高斯分布中进行采样一个向量,将采用后的结果向量通过Decoder还原输入样本。这个过程中,Decoder就在学习一个从0均值1方差的高斯分布,到目标数据集分布的一个映射,因此非常适用于生成任务。而dVAE、VQVAE等方法,希望将输入数据映射成离散化的变量,因此将Encoder-Decoder之间的高斯分布替换成了从一个字典中的均匀分布。VAE和dVAE的区别可以参考下面图中的对比。
因此,将原来图像进行patch粒度的划分后,通过dVAE,可以将patch映射到离散的图像token上,实现了图像的离散化。
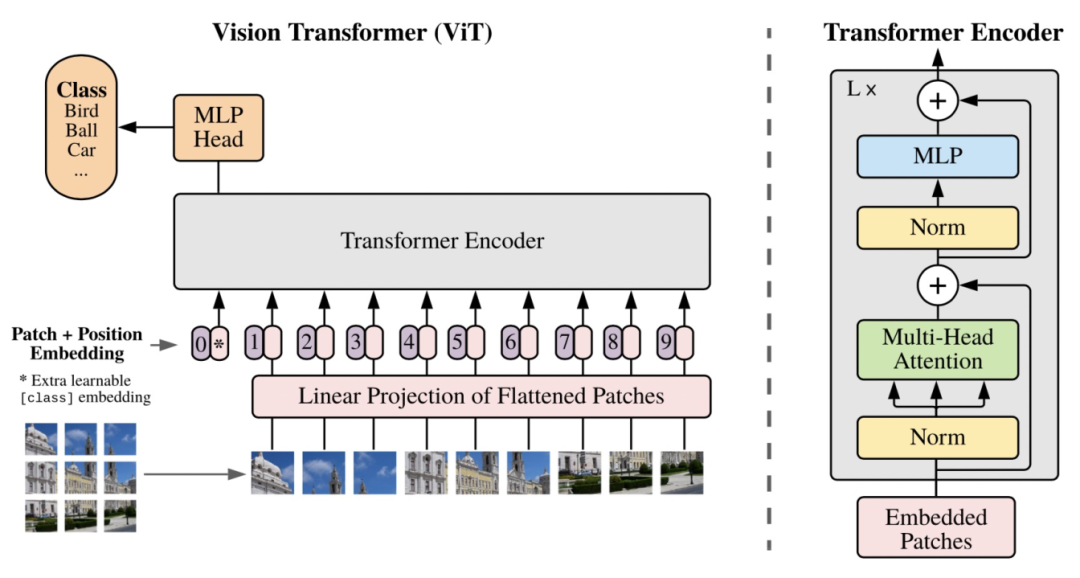
模型的主体结构采用的是ViT,VIT的具体结构我们在之前的文章介绍过,这里再复述一遍。ViT将图像划分成多个patch,假设原来图像的维度是[W, H, C](宽度*高度*channel),那么经过转换后的图像维度为[N, P*P*C],其中P代表将图像的分成了多少个块,P对应的就是图像转换成的序列的长度。接下来每个patch会使用一个NN网络映射成一个固定维度,输入到后续的Transformer Encoder中。
BEIT采用ViT的结构,输入和ViT相同,也是分割好的patch的,但是会随机mask掉部分patch,类似于MLM中的mask部分单词。BEIT的mask采用了blockwise masking的方法,每次选择一个局部区域进行mask,这和后续Bert优化中的mask span、mask词组、mask entity这种思路比较相似。在输出层,模型预测每个被mask掉patch对应的离散化token,实现图像上的无监督MLM。
下面我们来对比一些,BEIT和之前的Vision Transformer相比有什么特点。在之前的Vision Transformer工作中,大部分工作的研究重点在于如何让Transformer模型结构适用于CV领域,例如ViT、Swin Transformer等工作。而BEIT则更偏向于研究如何通过无监督学习的方法学习图像表示,类似于对比学习在做的工作。BEIT的成功之处在于直接将NLP中的无监督MLM预训练方法完全引入到CV领域中。
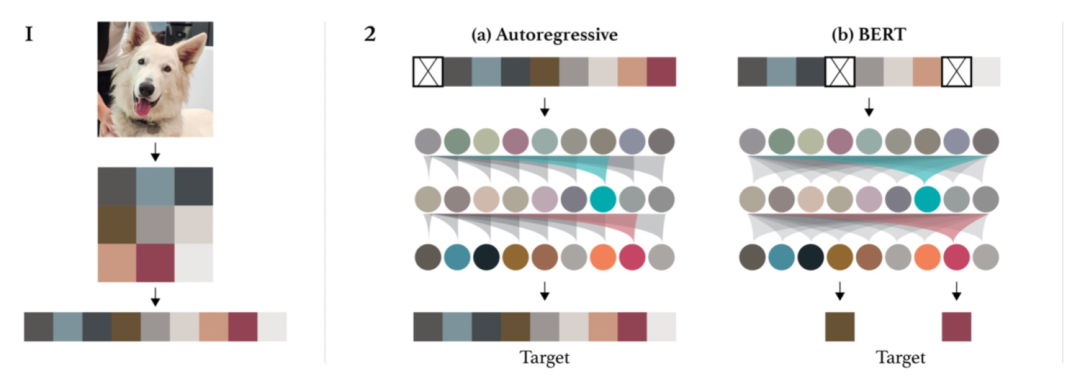
之前的工作中有MLM的尝试。在Generative Pretraining from Pixels(2020)这篇文章中提出了IGPT(如下图),也采用了MLM或者自回归来实现图像预训练。但是IGPT时期由于还没有ViT的建模方法,通过将图像分辨率降低来实现Transformer在CV的应用,丢失了很多图像信息。在ViT中也曾经尝试了MLM自监督学习的方法,但是采用的是回归建模,而并没有对图像patch进行离散化,这种基于像素级别的回归方法存在过度学习小范围细节信息而在整体结构上学习能力不足的问题。
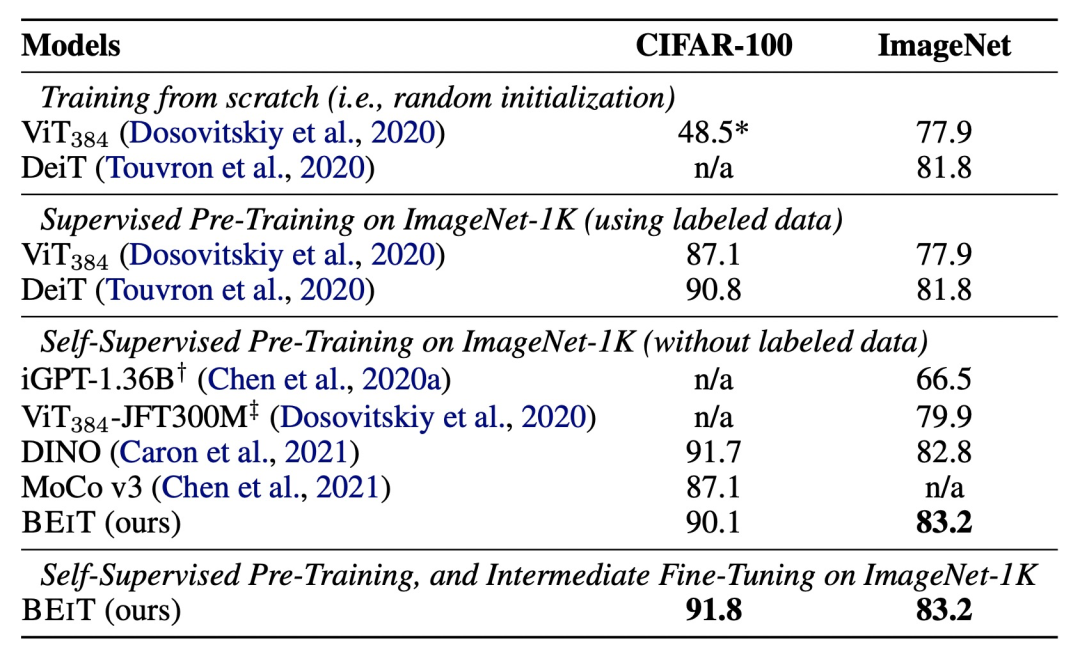
BEIT通过dVAE解决了图像离散化的问题,同时基于ViT成熟的Vision Transformer结构,最终实现了MLM在CV领域无监督学习的应用。从下面的实验结果也可以看出,采用BEIT进行预训练会显著提升图像分类效果,并且无监督预训练的效果要好于之前的iGPT、VIT等CV Transformer模型,同时也优于对比学习方法MoCo。
![]()
本文对ICLR 2022的BEIT工作进行了详细介绍,整体包括dVAE图像离散化和ViT MIM预训练两个部分。并且通过BEIT和历史工作IGPTA、ViT等工作的对比,分析了BEIT的优势。在基于对比学习的图像无监督学习方法之外,基于更细粒度的类MLM无监督学习方法也在逐渐完善。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~
![]()
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取70000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取70000+AI主题知识资源