
过去几年间,迁移学习给 NLP 领域带来了丰硕的成果,掀起了新一波的发展浪潮。 而迁移学习之所以如此有效,得益于其利用自监督任务(如语言建模或填充缺失词)在大量可用的无标注的文本数据上对模型进行预训练;接着,又在更小的标注数据集上对模型进行微调,从而让模型实现比单单在标注数据上训练更好得多的性能。 迁移学习在2018年出现的GPT、ULMFiT、ELMo以及 BERT等成果上初露锋芒,之后又在2019年大显身手,推动了领域内多种新方法的发展,其中就包括XLNet、RoBERTa、ALBERT、Reformer 和 MT-DNN 等等。 随着 NLP 领域的发展迅猛,评估其中的哪些发展成果最具有意义以及这些成果结合起来会发挥出怎样的效果,已不是易事。

论文地址:https://arxiv.org/abs/1910.10683
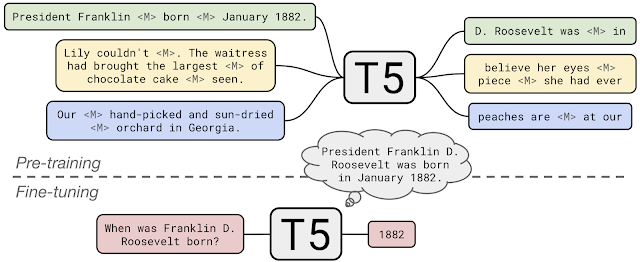
谷歌研究者在论文《使用统一的文本到文本的Transformer 来探索迁移学习的局限性》中,提出了一个大规模的实证评估,以确定哪些迁移学习技术效果最好,并大规模应用这些迁移学习技术来创建一个新模型,作者将这个新模型称之为文本到文本的迁移Transformer (Text-To-Text Transfer Transformer,T5)。与此同时,他们还引入了一个新的开源预训练数据集——Colossal Clean Crawled Corpus(C4)。 作者在C4数据集上对T5 模型进行预训练,让模型在许多 NLP 基准上都实现了最佳结果,与此同时还拥有足够的灵活性,进行微调后可应用到多个重要的下游任务上。
一、共享的文本到文本框架
创建了T5模型后,作者将所有的 NLP 任务都重新构建为统一的文本到文本格式,输入和输出都始终是文本字符串,与只能输出类标签或者输入范围的 BERT 式的模型截然不同。 该文本到文本的框架让他们可以在任何 NLP 任务上都使用相同的模型、损失函数以及超参数,包括机器翻译、文档摘要、问答和分类任务(如情感分析)等等。 T5 模型甚至可以被应用到回归任务上,具体方式是训练 T5 模型来预测一个数字的字符串表示,而不是这个数字本身。

二、大型预训练数据集(C4)
迁移学习的一个重要部分,便是用于模型预训练的未标注的数据集。为了准确地评估扩大预训练规模的效果,我们需要一个不仅高质量、多样化而且规模庞大的数据集。 现有的预训练数据集无法满足上述三点要求,例如来自维基百科的文本是高质量的,并且格式统一,但是规模相对而言较小,而从Common Crawl 网站上爬取的文本虽然规模较大并且多样化程度高,但是质量相当低。 为了满足这三点要求,作者开发了一个Colossal Clean Crawled Corpus数据集 (C4),该数据集是比维基百科大两个数量级的 Common Crawl 的清洁版本。他们的清洁处理过程涉及到删除重复数据、去除不完整的句子以及消除冒犯性或有噪音的内容。 这一过滤可以让模型在下游任务上获得更好的表现,与此同时额外规模的数据集也让模型在预训练期间不过拟合的情况下,增加其大小。 C4数据集地址: https://www.tensorflow.org/datasets/catalog/c4
三、迁移学习方法的系统研究
作者使用T5 文本到文本框架和新的预训练数据集C4,评估了在过去几年间为NLP 迁移学习引入的大量思想和方法。详尽的评估细节可前往论文查看,其中包括以下实验:
模型架构的实验中,他们发现编码—解码模型通常比“仅解码”的语言模型,性能更优; 预训练目标的实验中,他们证实了填空式的去噪目标(即训练模型来复原输入中缺失的词)的效果更好,并且其中最重要的因素是计算成本。 未标注数据集的实验中,他们展示了在域内数据集上训练模型是有益的,而在更小的数据集上对模型进行预训练则会导致不利的过拟合; 训练策略的实验中,他们发现多任务学习可以与“先预训练再微调”的方法相媲美,但是要求更细致地选择模型在每个任务上训练的频率。 模型规模的实验中,他们对比了不同大小的模型、训练时间以及集成模型的数量,以确定如何才能最好地利用固定的计算能力。
四、迁移方法+数据规模=性能最佳
为了探索NLP目前迁移学习的局限性,作者进行了最后一组实验,结合系统研究中的所有最佳方法,并利用Google Cloud TPU加速器进行了优化。 其中最大规模的模型有110亿个参数,在GLUE、Superglue、Team和CNN/Daily Mail基准测试中都能够达到SOTA。另外,在SuperGLUE 自然语言理解的基准测试中获得了接近人类水平的分数。
五、扩展到其他任务,表现也同样可喜
T5非常灵活,可以非常容易的进行修改,除了作者论文中的一些任务,在其他任务中也能取得了巨大的成功。例如在下面两个新任务中,模型表现也不错。
1、封闭数据问答
在阅读理解问题中往往可以使用文本到文本的框架。给模型提供上下文信息以及一个问题,训练其在上下文信息中找到问题的答案,例如可以向模型提供维基百科文章中关于康尼飓风的文本,并提问“康妮飓风在哪天发生?”然后训练模型,让其找到文章中的日期。事实上,作者使用这种方法在斯坦福问答数据集(SQuAD)中取得了最先进的结果。 在作者的Colab demo和后续论文中,其训练了T5在一个更加困难的封闭的环境中回答琐碎的问题,而且不需要接触任何外部知识。 换句话说,T在回答问题时只能用其在无监督预训练期间训练出的参数和知识。
在预训练期间,T5学习如何从C4文档中填充文本的丢失跨度。对模型进行了微调,在无需输入任何信息或者上下文的情况下,将其应用于已经封闭式问答。 T5非常擅长这项任务,其110亿参数模型分别在TriviaQA、Web问题(WebQuestions)和自然问题(Natural Questions)对50.1%、37.4%和34.5%的答案进行了精确生成。 为了客观看待此类问题,T5团队在酒吧琐事挑战(pub trivia challenge)与训练好的模型并肩作战,但不幸的是惨败而归。如下动图所示
2、完形填空 第二个任务是完形填空。像GPT-2这种大型语言模型在文本生产方面非常擅长。模型在经过训练之后,能够根据输入预测出下一个单词,如此将模型集成,便会产生非常创新性的应用程序,例如基于文本的游戏“AI地下城”。
T5使用的预训练目标与填空任务非常相似,在填空任务中,模型预测文本中缺少的单词,但是此目标是对“继续任务”(continuation task)的概括,因为填空任务中的空白有可能出现在文本的末尾。 为了完成目标,创建了一个名为“填充空白”的新任务,并要求模型用指定数量的单词替换空白。例如给模型输入:我喜欢吃花生酱和—4—三明治。大概会训练模型用4个单词进行填空。 用C4对模型进行了微调,效果良好,尤其是模型对缺失文本的预测非常棒!例如下列对于输入:“我喜欢花生酱和—N—三明治”,输出结果如下所示:
预训练模型: https://github.com/google-research/text-to-text-transfer-transformer#released-model-checkpoints
代码: https://github.com/google-research/text-to-text-transfer-transformer Colab Notebook https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb


