深度 | 通过方差分析详解最流行的Xavier权重初始化方法
选自Manas Blog
作者:Manas George
机器之心编译
参与:蒋思源
本文假定各位读者了解一些神经网络的基础,包括一些基本的前向与反向传播的表达式。本文很大一部分是进行基础的代数操作,只有少量的基本统计数据。如果读者希望先复习一点神经网络相关的知识,可以阅读以下机器之心曾发过的基础教程。本文尝试用 Glorot 和 Bengio 在他们论文中使用的推导以探讨深度神经网络中的权重初始化问题,并更好地说明为什么他们的方法解决了神经网络面临的训练问题。
梯度消失问题
起初,阻碍深度神经网络训练效率的最大问题之一就是极端的梯度情况。如果我们了解最初广泛作为神经网络激活函数的 Sigmoid 函数图像,很显然在函数的上下界附近梯度趋近于 0、激活值趋近于 0 或 1。但激活值处于这些极端区域时,我们称神经元已经饱和。在训练深度神经网络中,最后一个隐藏层往往会快速饱和至 0,所以随着梯度趋向于 0,前一层的反向梯度将会变得更小。因为极小的梯度无法给优化算法提供必要的优化信息,所以前面的隐藏层权重基本得不到更新。这显然是一个大问题,早期的隐藏层应该需要识别数据集中的局部特征,因此后续的层级才能用来在更高的抽象层次上构建更复杂的特征。如果前面层级的梯度基本影响不到权重的更新,那么模型将学不到任何信息。
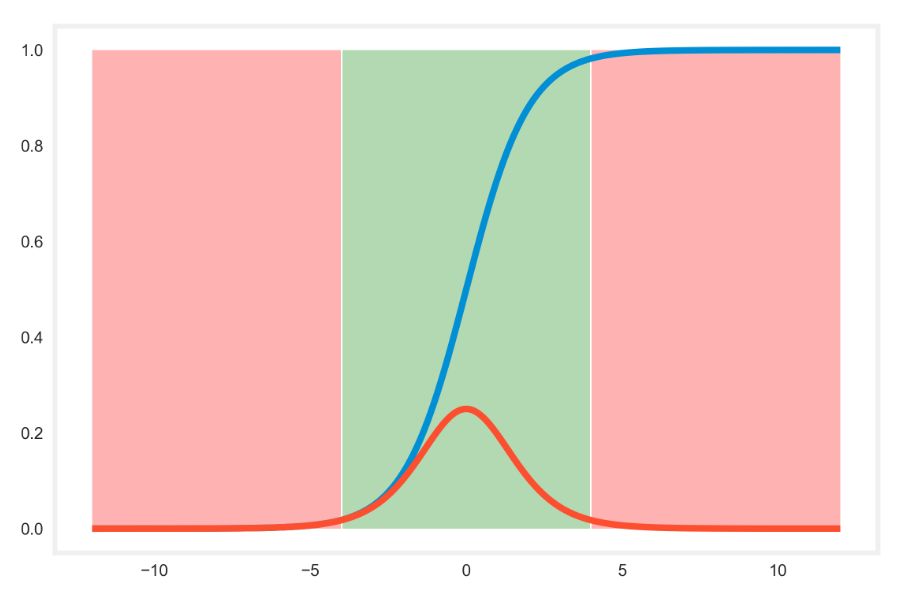
在以下 Sigmoid 激活函数(蓝线)和它的导数(红线)中,我们可以看到饱和的区域为浅红色的区域。该区域令 Sigmoid 函数的导数接近为 0,且不能提供有效的优化信息。
Glorot 和 Bengio
在 Xavier Glorot 和 Yoshua Bengio 2010 年的论文 Understanding the difficulty of training deep feedforward neural networks 中,他们从理论上探讨了权重初始化对梯度消失的影响。该论文第一部分比较了激活函数,并解释了常用的 Sigmoid 函数为何对饱和问题如此敏感。他们还表示双曲正切函数和 softsign(x/(1+|x|)) 激活函数在这方面有更好的表现。
该论文的第二部分考虑了全连接网络的权重初始化问题,为从均匀分布中采样初始化权重提供了理论性分析。该分析的直观性解释可以分为两部分,首先对于前向传播,我们需要确保所有层的激活值方差近似相等,因此每一个训练样本传播经过网络的信息才能保持平滑的属性。同样对于反向传播,每层梯度保持近似的方差将允许信息平滑地反向流动以更新权重。近似方差的梯度同样确保误差数据能反馈到所有层级,因此它是整个训练过程中的关键。
为了形式化这些概念,首先我们必须定义各个符号与表达式的意义:
a^L 为第 L 层的激活值向量,它的维度为 n_L × 1,其中 n_L 为第 L 层单元数。
W^L 为第 L 层的权重矩阵,它的维度为 n_L × n_L-1,其中每一个元素 W_jk 表示前一层第 j 个神经元连接到后一层第 k 个神经元的权重。
b^L 表示第 L 层的偏置项向量,它的维度和 a^L 相同。
z^L 表示第 L 层激活函数的加权输入向量,即 z^L = W^L × a^L-1 + b^L。
C 为我们尝试优化的损失函数。Glorot 和 Bengio 使用条件对数似然函数−logP(y|x) 作为损失函数,但该函数的具体表达式在本文并不重要。
σ 为激活函数,因此 a^L = σ(z^L),其中该函数应用到输入向量的每一个元素。
n_L 为第 L 层的神经元数量。
x 为神经网络的输入向量。
δ^L=δC/δz^L 为损失函数对第 L 层加权输入向量的梯度,同样也成为误差方向。
下面的分析适用于层级数为 d 的全连接神经网络,且具有在零点为单位梯度的对称激活函数。偏置项初始化为 0,且在初始阶段激活函数近似表达为函数 f(x) = x。
我们假设权重、激活值、加权输入、网络的原始输入和梯度都服从独立分布,它们的参数都仅取决于所需要考虑的层级。在这样的假设下,第 L 层权重的方差可以表示为 Var[W^L],其它如激活值或梯度等变量的方差表达式同理可得。
前向传播
对于前向传播,我们希望所有层都保持激活值的输入和输出方差相等,因此激活值在网络的传递中不会放大或缩小。若考虑第 L 层第 j 个单元的加权输入 z_j:
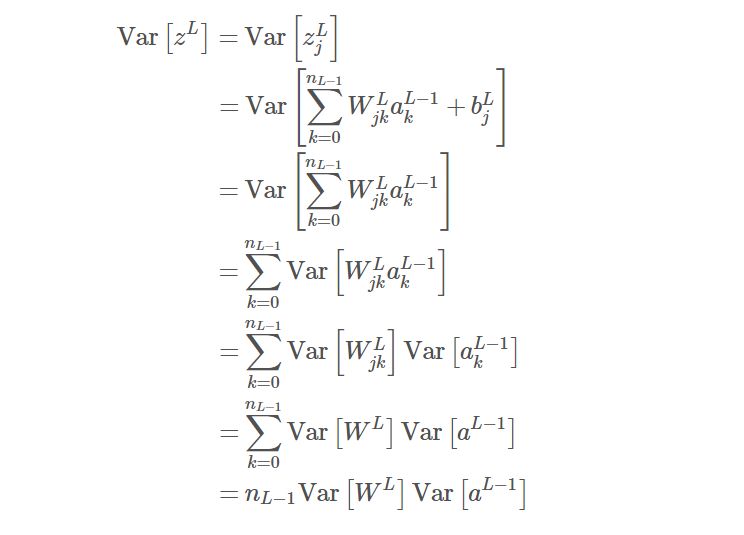
在上面的化简过程中,我们需要使用定理「两个独立随机变量和的方差等于这两个变量方差的和」,且前面我们假设了加权的激活值与其它变量相互独立。此外,若假设当前层的权重独立于前一层的激活值,乘积的方差可扩展等价于方差的乘积。两个独立随机变量乘积的方差等于方差的乘积还要加上对应的均值项,不过由于我们假设激活值与权重都服从均值为 0 的分布,因此均值项可以省略。
由于激活函数是对称的,因此输入为 0 的激活值为 0。此外,若假设零点的导数为 1,那么我们在初始化阶段就可以恒等地近似表达 σ 激活函数,其中偏置项为零,加权输入向量的期望同样为零。在这个假设下,a^L ≈ z^L,因此我们可以将前面的方程式简化表达为:
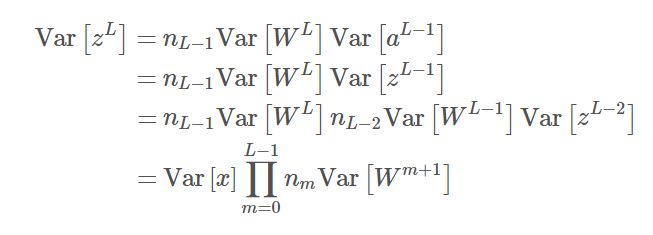
因此如果我们希望所有加权输入的方差相等,乘数项必须为 1,最简单的方法是确保 Var[W^m+1] = 1/n_m。同样对于所有层级 L,n_in 为输入到层级的单元数(输入端数),那么我们希望有:
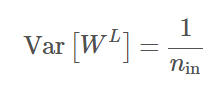
反向传播
对于反向传播,我们梯度的方差在各个层级中都相等,所以梯度才不会出现消失或爆炸等问题。我们使用反向传播方程式作为我们的出发点:
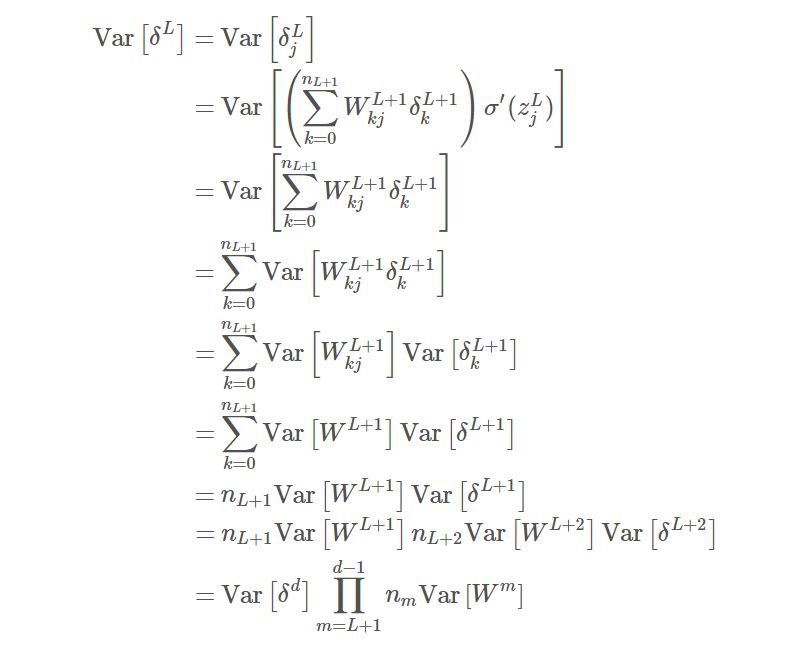
与前向传播相似,我们假设初始阶段的梯度与权重是相互独立的,且使用前面解释的方差恒等式。此外,我们假设加权输入 z^L 的均值为 0,且在初始化阶段激活函数的导数σ′(z_j) 逼近为 1。为了确保在反向传播中保持一致的方差,我们服从约束条件 Var[W^m] = 1/n_m。对于层级 L 和层级输出单元数 n_out,该表达式可以写为:
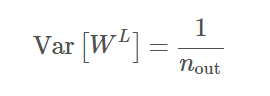
结语
在一般条件下,一个层级的输入端和输出端数量并不会相等。因此作为一种权衡,Glorot 和 Bengio 建议使用输入端和输出端数量的均值,即提出了以下方程式:
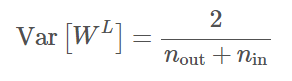
如果从均匀分布采样,那么分布的区间可以选为 [-a, a],其中 a =(6/n_out + n_in)^0.5。其中特定项 6^0.5 来源于区间 [-a, a] 内均匀分布的方差 a^2/3。当然权重也可以从均值为 0、方差服从上述表达式的正态分布中采样。
在本论文之前,一般标准的初始化技术是从区间 [-1/n^0.5, 1/n^0.5] 内均匀分布中采样权重。这样会使权重之间的方差变为 Var[W^L] = 1/3n^L,把该方差代入我们用于反向传播的方程后,我们能发现在传递的过程中梯度会减小。大概每层会减小 1/3 左右,这个梯度消失的效果也可以在实验中证明。该论文发现新的初始化方法能确保梯度在各层之间保持相对稳定,且此初始化方法目前是大多数深度学习模型所采用的。
有意思的是,本论文假设了一个在零点有单位梯度的对称激活函数。但实际上,本论文的实验结果可以使用 tanh 激活函数表示,它同时满足这两个假设。
对于像 ReLU 等激活函数,它们也进行了必要的调整。由于 ReLU 激活函数在值域上有一半为零,所以可以通过加倍权重的方差进行补偿,这种启发式的方法与 He 等人的详细分析结果相匹配,即 Var[W^L] = 4/(n_out + n_in)。
logistic 激活函数
在前向传播的推导中,我们将激活函数近似地等价于初始化阶段中的单位函数。对于 logistic 激活函数,因为函数在零点的导数为 1/4、函数值为 0,所以我们可以等效计算为 x/4 + 1/2。我们在零点展开泰勒级数,并带入计算:
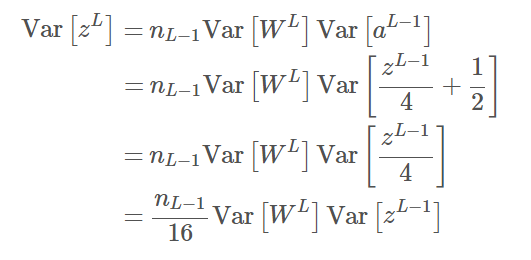
其余的步骤都是等价的,除了前面的因子 1/16。
在反向传播中有类似的过程,我们忽略了激活函数的导数,因为在前面的假设中导数为 0。如果我们插入修正值 1/4,那么我们同样可以得到因子 1/16。由于这个因子在两个传播过程都相同,那么我们可以将它添加到输入端数量和输出端数量以构建约束项:
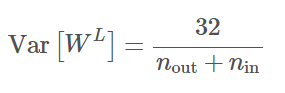
以下是权重初始化的参数:

原文链接:https://www.mnsgrg.com/2017/12/21/xavier-initialization/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




