干货 | 深入理解深度学习中的激活函数
点击“计算机视觉life”关注,置顶更快接收消息!
本文阅读时间约6分钟
在这个文章中,我们将会了解几种不同的激活函数,同时也会了解到哪个激活函数优于其他的激活函数,以及各个激活函数的优缺点。
1. 什么是激活函数?
生物神经网络是人工神经网络的起源。然而,人工神经网络(ANNs)的工作机制与大脑的工作机制并不是十分的相似。不过在我们了解为什么把激活函数应用在人工神经网络中之前,了解一下激活函数与生物神经网络的关联依然是十分有用的。一个典型神经元的物理结构由细胞体、向其他神经元发送信息的轴突以及从其他神经元接受信号或信息的树突组成。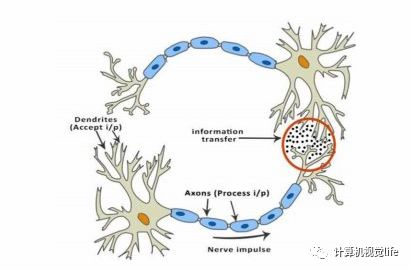
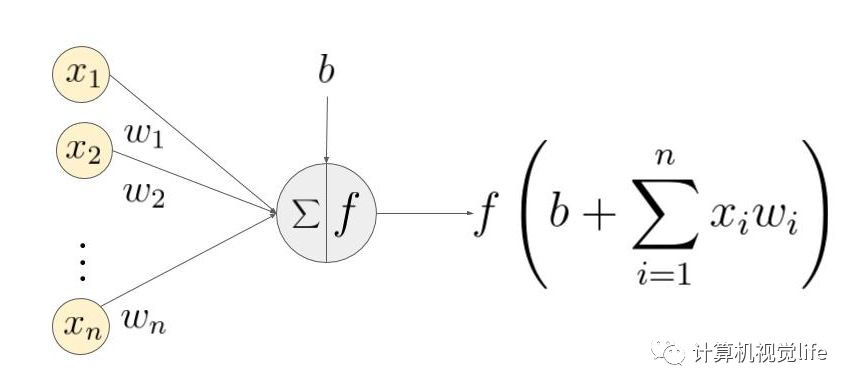
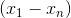

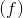
图二中的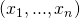
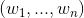
这些年来,人们使用了各种各样的激活函数,但是寻找一个合适的激活函数使神经网络学习得更好更快依然是一个非常活跃的研究领域。
2. 网络是怎么学习的?
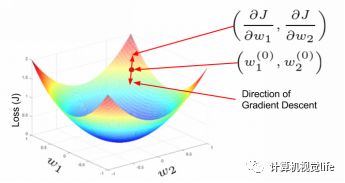
理解神经网络学习的基本概念是关键。假设网络原本应该得到的输出为y。网络产生的输出为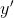
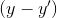
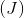
在图三中,损失函数的形状像一个碗。在训练过程中的任何一点,损失函数关于权值的偏导数只是在碗的当前位置上的斜率。可见通过向偏导数预测出的方向移动,我们可以到达碗的底部,从而最小化了损失函数。这个使用函数的偏导数来迭代找到局部最小值的方法称为梯度下降法。在人工神经网络中,权值通过称为反向传播的方法来更新。损失函数关于权值的偏导数用于更新权值。在某种意义上来说,误差是在网络上用导数来反向传播的。这是用迭代的方式来完成的,在许多轮迭代之后,损失达到最小值,并且损失函数的导数变为0。
3. 激活函数的类型
线性激活函数:形式为
的简单的线性函数。基本上,输入不经过任何修正就传递给输出。
图四 线性激活函数
非线性激活函数:这些函数用于分离非线性可分的数据,并且是最常使用的激活函数。一个非线性等式决定了从输入到输出的映射。不同类型的非线性激活函数分别有sigmod, tanh, relu, lrelu, prelu, swish等等。本文接下来会详细的讨论这些激活函数。
图五 非线性激活函数
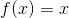
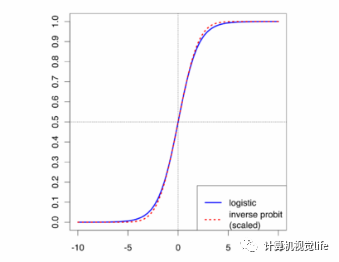
4. 在一个人工神经网络中,我们为什么需要非线性激活函数?
神经网络用于实现复杂的函数,而非线性激活函数能够使神经网络逼近任意复杂的函数。如果没有激活函数引入的非线性,多层神经网络就相当于单层的神经网络。让我们看一个简单的例子来理解为什么没有非线性,神经网络甚至不可能逼近像XOR和XNOR门这样简单的函数。在图六中,我们用图表表示了XOR门。我们的数据集中有两个类,分别用交叉和圆圈来表示。当两个特征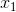
通过图六我们可以看到数据点都是非线性可分的。也就是说,我们无法画出一条笔直的直线来分开蓝色圆圈和红色交叉。因此,我们才需要非线性的决策边界来将它们分开。如果没有非线性,神经网络就不能逼近XOR门。激活函数对控制神经网络的输出范围也起着至关重要的作用。神经元的输出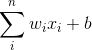
5. 非线性激活函数的类型
5.1 Sigmoid激活函数
Sigmoid也被称为逻辑激活函数(Logistic Activation Function)。它将一个实数值压缩到0至1的范围内。当我们的最终目标是预测概率时,它可以被应用到输出层。它使很大的负数向0转变,很大的正数向1转变。在数学上表示为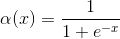
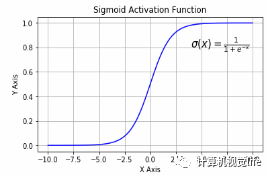
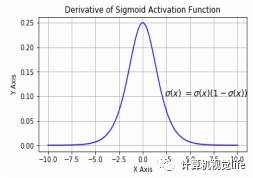
Sigmoid激活函数的三个主要缺点是:
梯度消失:sigmoid函数在0和1附近是平坦的。也就是说,sigmoid的梯度在0和1附近为0。在通过sigmoid函数网络反向传播时,当神经元的输出近似于0和1时它的梯度接近于0。这些神经元被称为饱和神经元。因此,这些神经元的权值无法更新。不仅如此,与这些神经元相连接的神经元的权值也更新得非常缓慢。这个问题也被称为梯度消失。所以,想象如果有一个大型网络包含有许多处于饱和动态的sigmoid激活函数的神经元,那么网络将会无法进行反向传播。
不是零均值:sigmoid的输出不是零均值的。
计算量太大:指数函数与其它非线性激活函数相比计算量太大了。下一个要讨论的是解决了sigmoid中零均值问题的非线性激活函数。
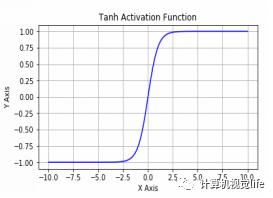
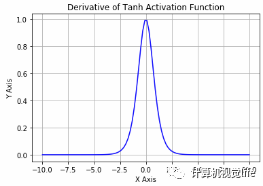
5.2 Tanh激活函数
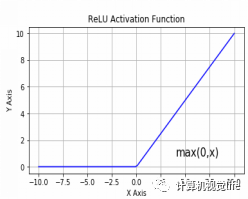
5.3 线性整流函数(ReLU)
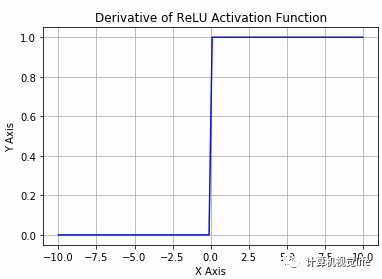
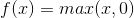
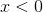
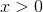
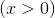
不是零均值的:与sigmoid相同,它的输出不是零均值的。
Relu的另一个问题是,如果在前向传播的过程中
,神经元保持没有被激活的状态并且在反向传播时抵消了梯度。此时权值得不到更新,网络无法学习。当
时,斜率在这个点是没有定义的,不过这个问题在实现的过程中通过选择左或者右梯度解决。为了解决relu激活函数在x<0时的梯度消失问题, 我们提出了被称为泄漏relu(Leaky Relu)的激活函数,这个激活函数试图解决ReLU激活函数”Dead ReLU”的问题。让我们详细了解一下leaky relu。
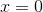
5.4泄漏ReLU激活函数(leaky relu)
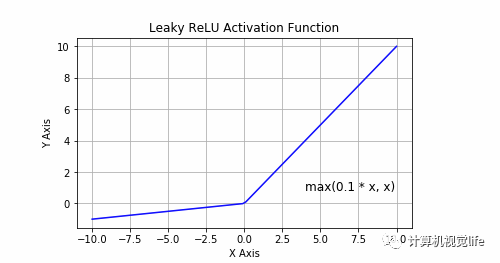
Leaky relu的思想就是当
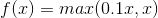
5.5 参数ReLU激活函数(Parametric ReLU)
PRelu的函数为: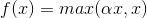
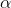
5.6 SWISH激活函数
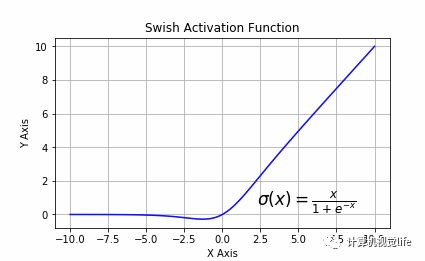
图十四 SWISH激活函数Swish也被称为self-gated(自门控)激活函数,最近由谷歌研究人员发布。它的数学表达式为: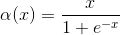
参考:
https://www.learnopencv.com/understanding-activation-functions-in-deep-learning/



