
简介:
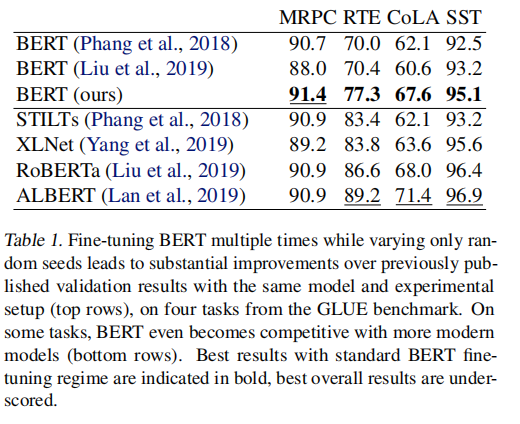
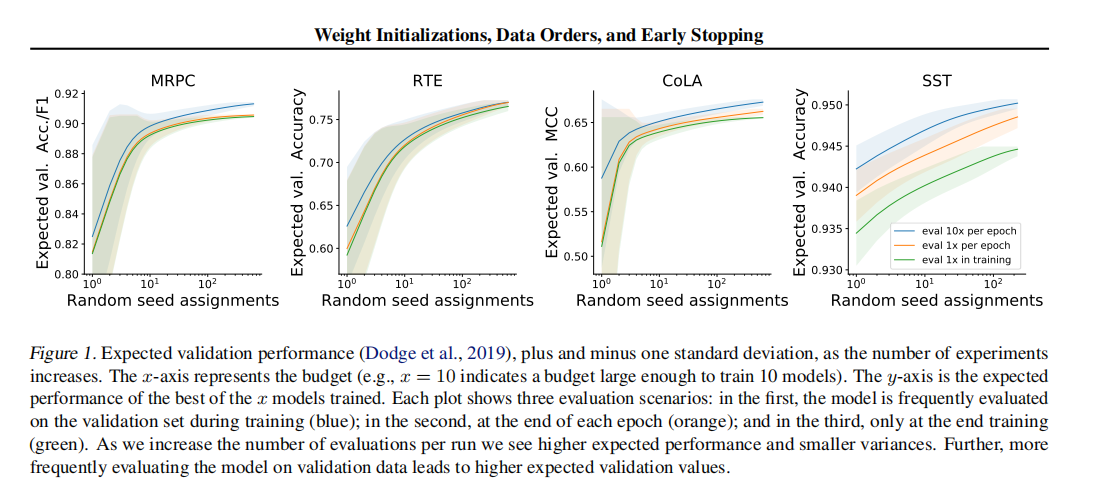
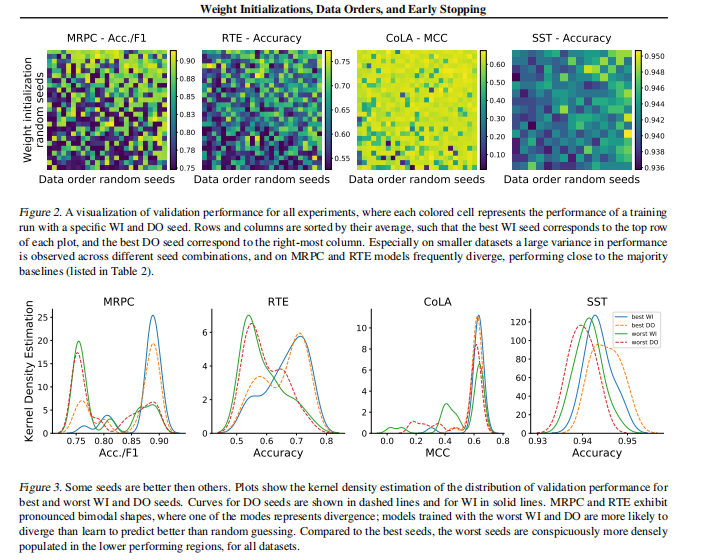
在自然语言处理中,将预训练的上下文词嵌入模型微调到受监督的下游任务已变得司空见惯。但是,此过程通常很脆弱:即使具有相同的超参数值,不同的随机种子也可能导致结果截然不同。为了更好地理解这种现象,我们尝试使用GLUEbenchmark中的四个数据集,每个BERT都微调了数百个时间,同时仅改变了随机种子。与先前报告的结果相比,我们发现性能有了实质性的提高,并且我们量化了最佳发现模型的性能如何随微调试验次数的变化而变化。此外,我们研究了随机种子选择影响的两个因素:权重初始化和训练数据顺序。我们发现这两者都对样本外性能的差异做出了可比的贡献,并且在所有探索的任务中,一些权重初始化都表现良好。在小型数据集上,我们观察到许多微调试验在整个训练过程中存在差异,并且我们为从业者提供最佳实践,以便尽早停止训练不太理想的跑步。我们公开发布了我们的所有实验数据,包括2100个试验的训练和验证分数,以鼓励在微调过程中进一步分析训练动力学。

成为VIP会员查看完整内容
相关内容

华盛顿大学(University of Washington)创建于1861年,坐落在美国最适宜居住和工作的城市西雅图,是美国西海岸最古老的大学,是一所世界顶尖的著名大学,长期保持世界大学财政支出和研究经费前三位。华盛顿大学拥有世界最顶尖的教师队伍,拥有29,804名教职员工,包括5803名教师,师生比例为 1:7.3 ,其中众多教授为所在学术领域的世界领导者。
Arxiv
3+阅读 · 2019年8月22日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
5+阅读 · 2018年4月3日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年8月22日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
5+阅读 · 2018年4月3日