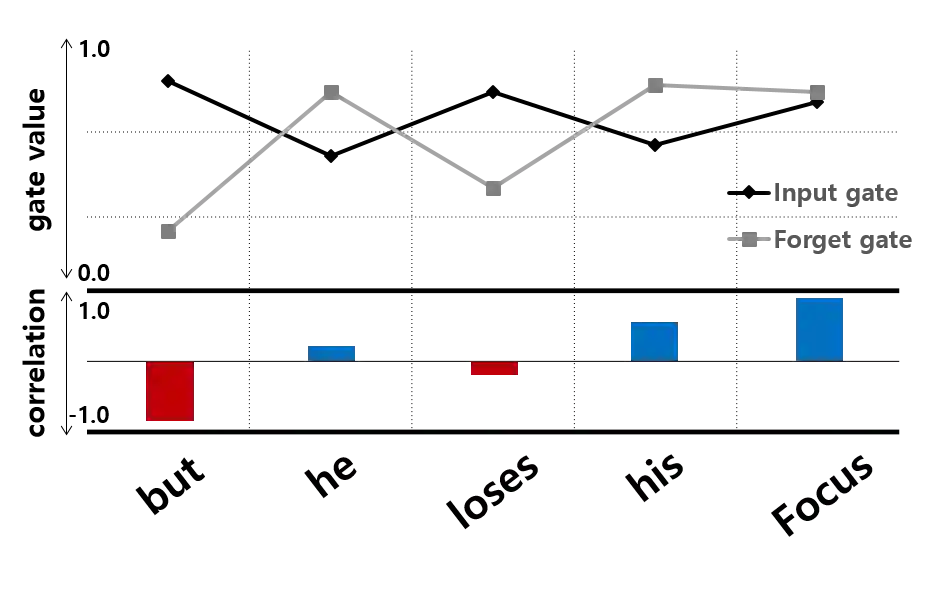
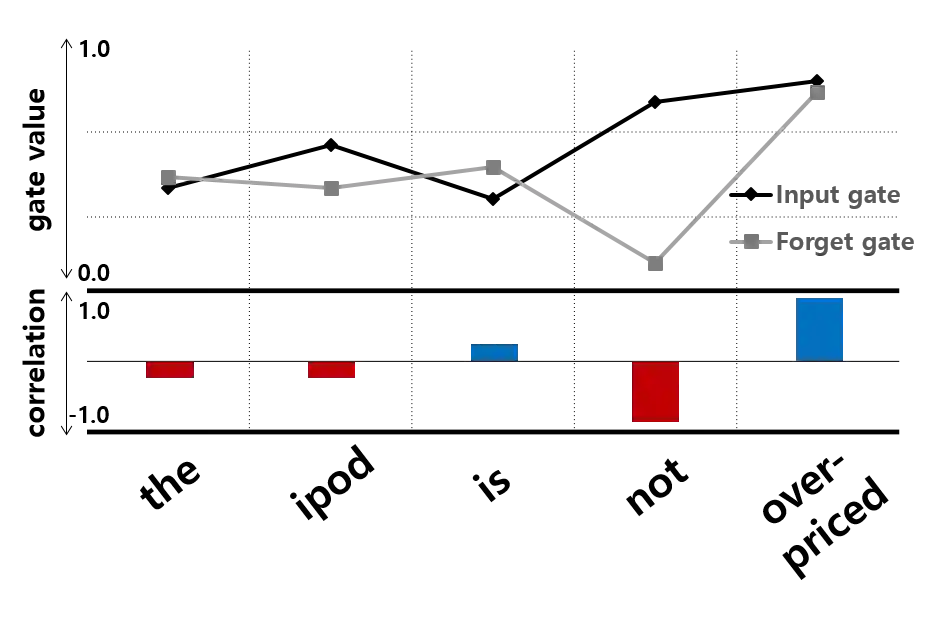
Long Short-Term Memory (LSTM) infers the long term dependency through a cell state maintained by the input and the forget gate structures, which models a gate output as a value in [0,1] through a sigmoid function. However, due to the graduality of the sigmoid function, the sigmoid gate is not flexible in representing multi-modality or skewness. Besides, the previous models lack modeling on the correlation between the gates, which would be a new method to adopt inductive bias for a relationship between previous and current input. This paper proposes a new gate structure with the bivariate Beta distribution. The proposed gate structure enables probabilistic modeling on the gates within the LSTM cell so that the modelers can customize the cell state flow with priors and distributions. Moreover, we theoretically show the higher upper bound of the gradient compared to the sigmoid function, and we empirically observed that the bivariate Beta distribution gate structure provides higher gradient values in training. We demonstrate the effectiveness of bivariate Beta gate structure on the sentence classification, image classification, polyphonic music modeling, and image caption generation.
翻译:长期短期内存( LSTM) 通过输入和遗忘门结构所维护的单元格状态来推断长期依赖性, 以输入和遗忘门结构所维护的单元格状态来模拟门输出值, 以 [0, 1 以数值为 [0], 以示象形函数为模型。 但是, 由于Sigmoid 函数的渐进性, sigmoid门在代表多式或扭曲性时不具有灵活性。 此外, 以前的模型缺乏对门之间相关性的模型, 这将是对先前和当前输入之间的关系采用感应偏差的新方法。 本文建议使用双变量 Beta 分布的新门结构 。 拟议的门结构使得在 LSTM 单元格的门上能够进行概率性建模, 以便模型能够根据先前和分布来定制细胞的状态流。 此外, 我们理论上展示了梯度与象函数功能相比较高的上限, 我们从经验中观察到, 双变量Beta 分发门结构在培训中提供了更高的梯度值 。 我们展示了在句分类、 图像分类、 多式音乐模型和图像生成图象 上 的效能 。