干货|神经网络最容易被忽视的基础知识二-激活函数以及损失函数知识
上篇讲解了神经网络最容易被忽视的基础知识一
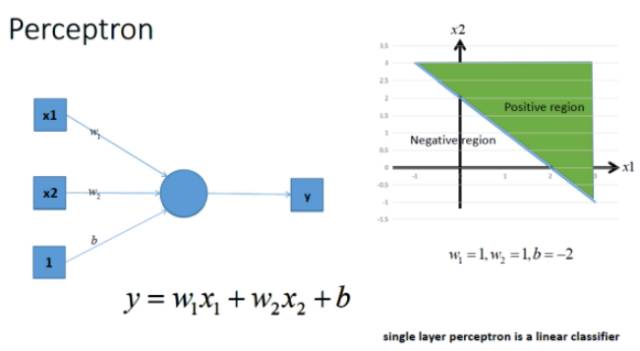
上图可看做普通的线性分类器,也就是线性回归方程。这个比较基础,效果如右图。当然有时候我们发现这样的线性分类器不符合我们要求时,我们很自然的想到那我们就加多一层,这样可以拟合更加复杂的函数,如下图a:
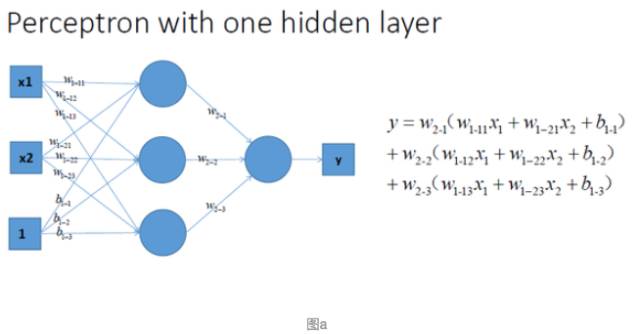
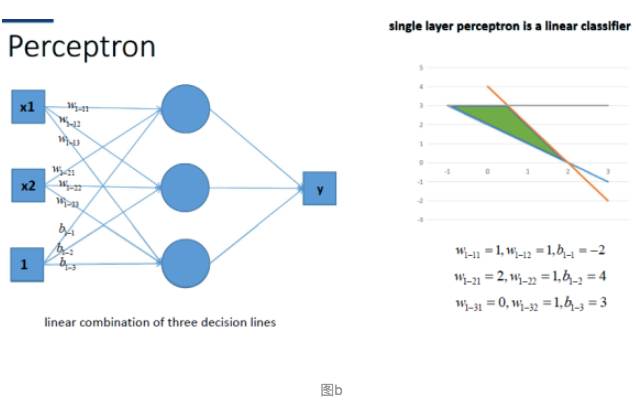
但同时当我们动笔算下, 就会发现, 这样一个神经网络组合起来,输出的时候无论如何都还是一个线性方程。如上图b右边,就只能这样分类。(那也太蠢了吧)。下图表示一层加如激活函数的情况!
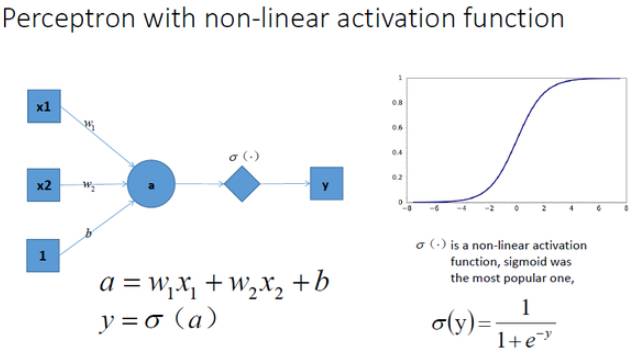
一层很多时候是远远不够的,前面讲过,简单的线性分类器就可以看成是一层的神经网络,比如上图,激活函数是signmoid,那就可以看成是二分类的逻辑回归!
下面扩展到多层,如下图1,2:
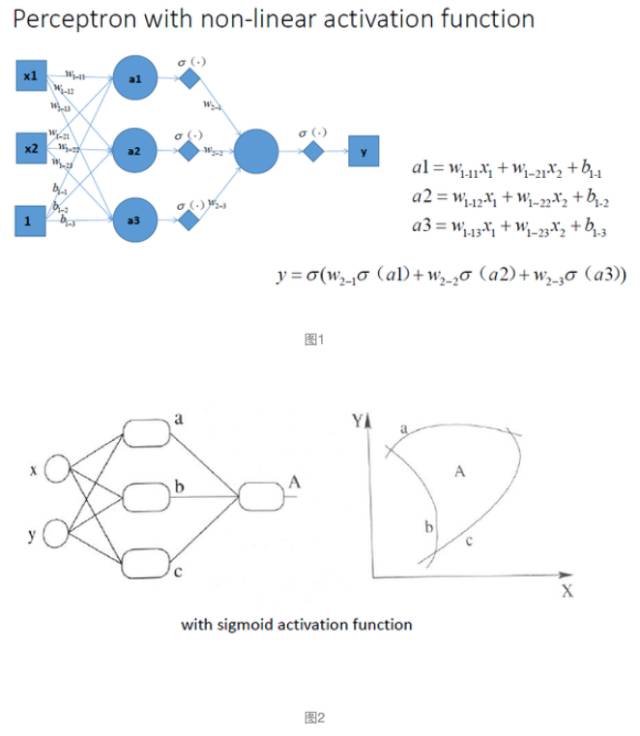
图1是一个简单的MLP(全链接神经网络),图2的右边课简单表示左图的可视化,那么对比之前的无激活函数的图,很明显是更加的非线性,拟合能力也会更强,同时可以想到,当层数更多,其能力也会越来越强!
简单来说:就是使得神经网络具有的拟合非线性函数的能力,使得其具有强大的表达能力!
简单扩展,神经网络的万能近似定理:一个前馈神经网络如果具有线性层和至少一层具有"挤压"性质的激活函数(如signmoid等),给定网络足够数量的隐藏单元,它可以以任意精度来近似任何从一个有限维空间到另一个有限维空间的borel可测函数。
要相符上面的定理,也就是想拟合任意函数,一个必须点是“要有带有“挤压”性质的激活函数”。
这里的“挤压”性质是因为早期对神经网络的研究用的是sigmoid类函数,所以对其数学性质的研究也主要基于这一类性质:将输入数值范围挤压到一定的输出数值范围。(后来发现,其他性质的激活函数也可以使得网络具有普适近似器的性质,如ReLU 。
sigmoid
优点:有较好的解释性
缺点:1.Sigmoid函数饱和使梯度消失。sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。2.输出不是零中心的,这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数,那么关于w的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数,这样梯度下降权重更新时出现z字型的下降。
这样收敛会变得异常的慢。(这也是为什么要一直保持为数据的0中心化)—–但这个问题比较小3.exp()在深度神经网络时候相比其他运算就比较慢
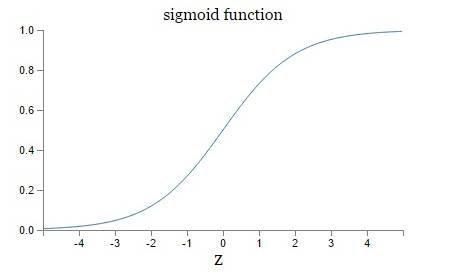
Tanh非线性函数
优点:1.它的输出是零中心的。因此,在实际操作中,tanh非线性函数比sigmoid非线性函数更受欢迎。
缺点:1.和Sigmoid函数一样,饱和使梯度消失。计算慢
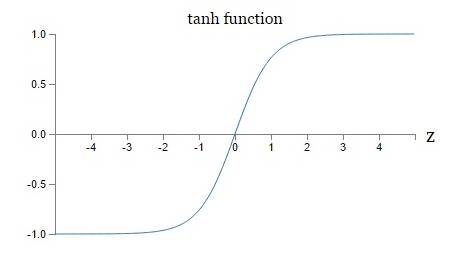
ReLU
优点:1.ReLU对于随机梯度下降的收敛有巨大的加速作用( Krizhevsky 等的论文alexnet指出有6倍之多)。据称这是由它的线性,非饱和的公式导致的;2.注意:现在大部分的DNN用的激活函数就是ReLu
缺点:1.当x是小于0的时候,那么从此所以流过这个神经元的梯度将都变成0;这个时候这个ReLU单元在训练中将死亡(也就是参数无法更新),这也导致了数据多样化的丢失(因为数据一旦使得梯度为0,也就说明这些数据已不起作用)。
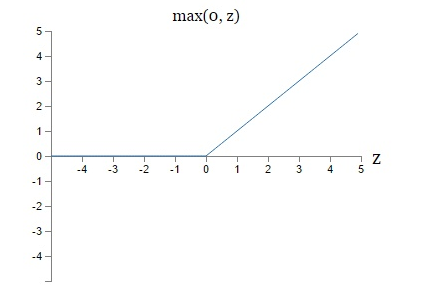
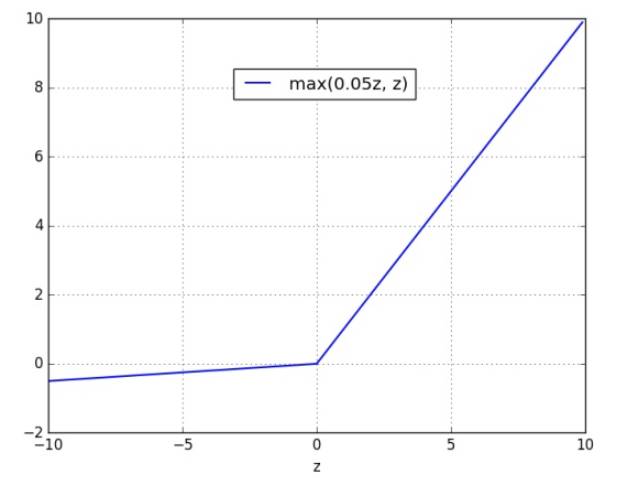
Leaky ReLU
优点:1.非饱和的公式;2.Leaky ReLU是为解决“ReLU死亡”问题的尝试
缺点:1.有些研究者的论文指出这个激活函数表现很不错,但是其效果并不是很稳定
Kaiming He等人在2015年发布的论文Delving Deep into Rectifiers中介绍了一种新方法PReLU,把负区间上的斜率当做每个神经元中的一个参数。然而该激活函数在在不同任务中均有益处的一致性并没有特别清晰。
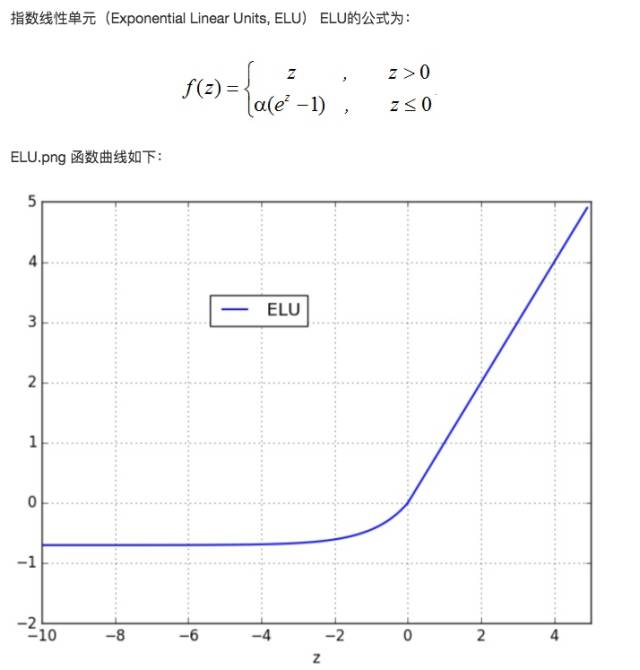
ELU
Maxout
Maxout是对ReLU和leaky ReLU的一般化归纳
优点:1.拥有ReLU单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的ReLU单元)
缺点 :1.每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。难训练,容易过拟合
转自:机器学习算法与自然语言处理
完整内容请点击“阅读原文”