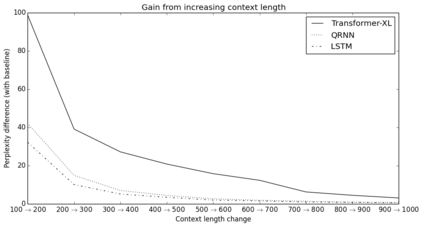
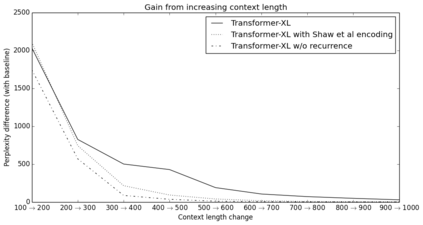
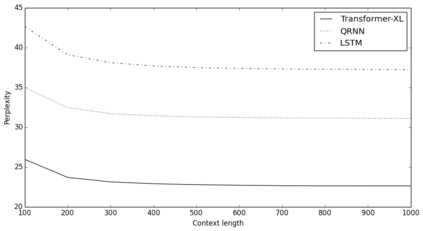
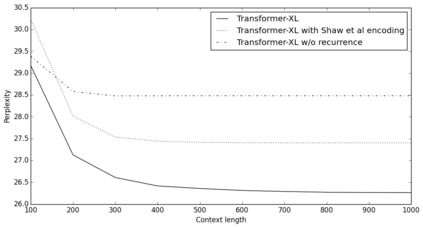
Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the setting of language modeling. We propose a novel neural architecture Transformer-XL that enables learning dependency beyond a fixed length without disrupting temporal coherence. It consists of a segment-level recurrence mechanism and a novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the context fragmentation problem. As a result, Transformer-XL learns dependency that is 80% longer than RNNs and 450% longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+ times faster than vanilla Transformers during evaluation. Notably, we improve the state-of-the-art results of bpc/perplexity to 0.99 on enwiki8, 1.08 on text8, 18.3 on WikiText-103, 21.8 on One Billion Word, and 54.5 on Penn Treebank (without finetuning). When trained only on WikiText-103, Transformer-XL manages to generate reasonably coherent, novel text articles with thousands of tokens. Our code, pretrained models, and hyperparameters are available in both Tensorflow and PyTorch.
翻译:变异器具有学习长期依赖性的潜力,但在语言模型设置中受固定时间背景的限制。 我们提议一个新的神经结构变异器- XL, 使学习依赖性超过固定长度, 且不会破坏时间的一致性。 它由部分级重现机制和一个新颖的定位编码计划组成。 我们的方法不仅能够捕捉长期依赖性, 而且还能解决背景碎裂问题。 因此, 变异器- XL 学习依赖性比RNN 长80%, 比香草变异器长450%, 在短长序列上都取得更好的性能, 在评估期间比香草变异器快1 800+倍。 值得注意的是, 我们把最先进的bpc/plislity结果改进到0. 99 enwiki8, 1.08 在文本8, 18.3 在WikitText-103, 21.8 在一亿字W, 21.8, 和 Penn Treebank (不作微调) 54.5 。 当只受过Wikit- 103 的训练时, 变异器XL 管理着合理一致的新文本和上千件。