腾讯出品:自循环半监督算法性能逼近监督学习!

问题的挖掘
方法
 ;
第二,将拼图游戏任务整合成到端到端自监督框架中,输入的自监督子任务的尺寸要求与分割任务的尺寸一致,即输入和输出长宽一致。
因此,本文没有使用共享权重的神经网络结构(没有再单独设计一个针对于图像块的分类网络),而是将随机排列的图像块拼接成和原始图像输入同等大小的图像(即原始图像裁剪成9块,随机排列组合后,依然还是原始图像的大小,只是相对位置进行了改变)输入进网络进行K分类训练。
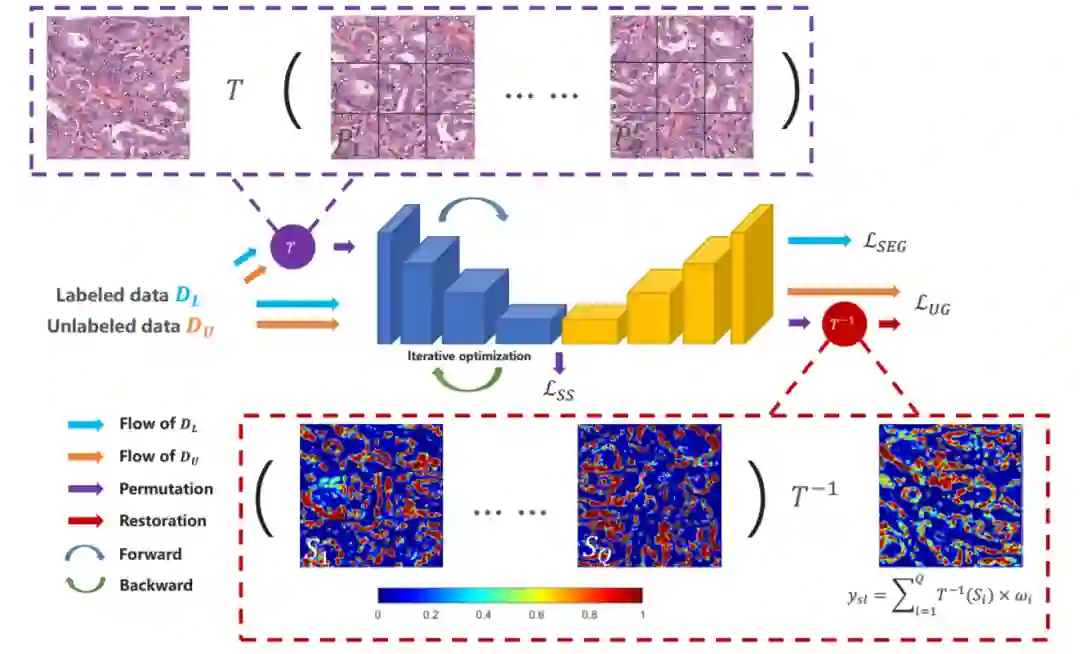
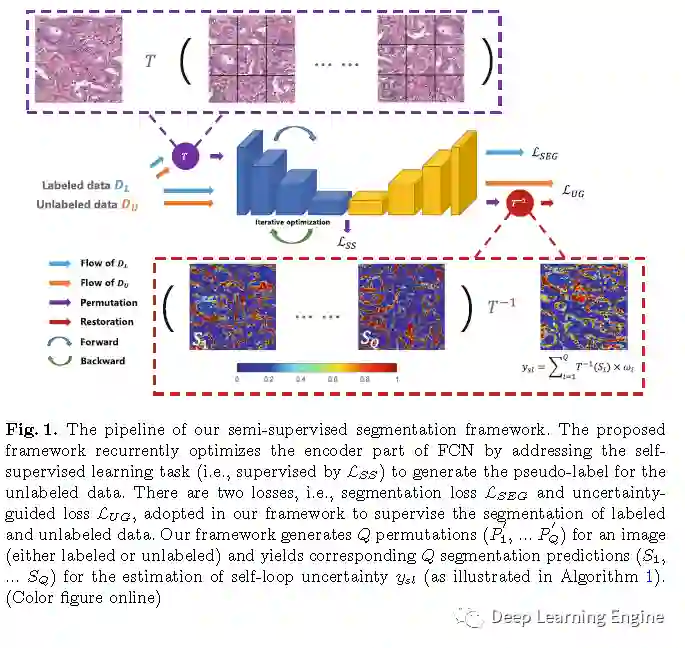
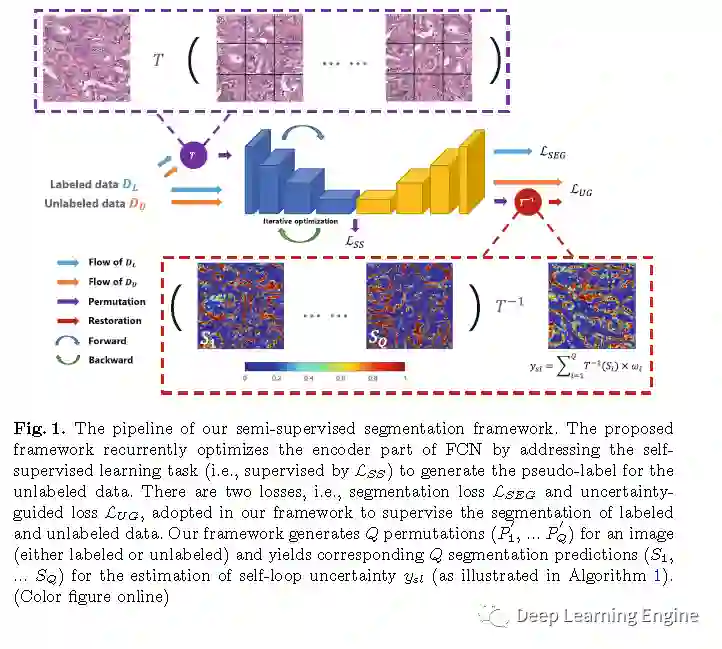
算法流程图以及伪代码如下。
;
第二,将拼图游戏任务整合成到端到端自监督框架中,输入的自监督子任务的尺寸要求与分割任务的尺寸一致,即输入和输出长宽一致。
因此,本文没有使用共享权重的神经网络结构(没有再单独设计一个针对于图像块的分类网络),而是将随机排列的图像块拼接成和原始图像输入同等大小的图像(即原始图像裁剪成9块,随机排列组合后,依然还是原始图像的大小,只是相对位置进行了改变)输入进网络进行K分类训练。
算法流程图以及伪代码如下。

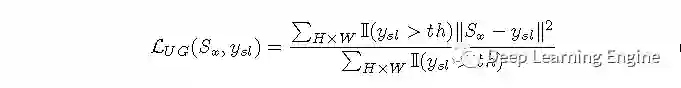
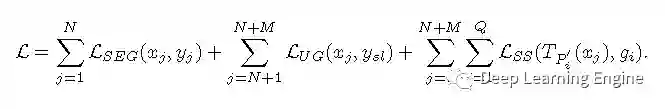
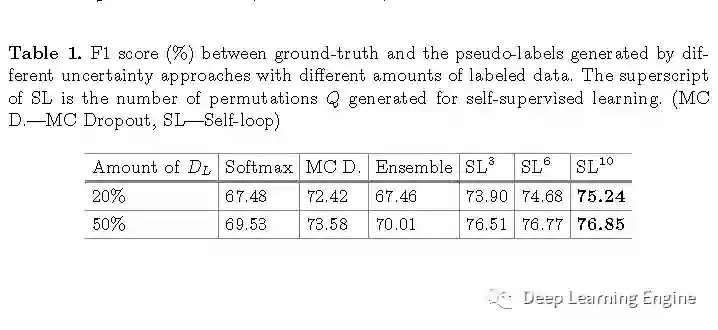
实验
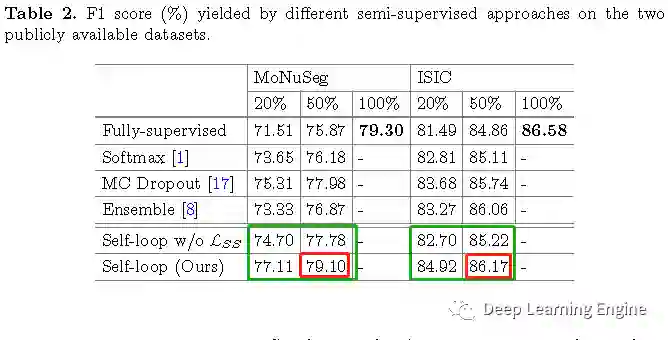
结论
结语
AI科技评论联合【机械工业出版社华章公司】为大家带来15本“新版蜥蜴书”正版新书。
在10月24号头条文章《1024快乐!最受欢迎的AI好书《蜥蜴书第2版》送给大家!》留言区留言,谈一谈你对本书内容相关的看法和期待,或你对机器学习/深度学习的理解。
AI 科技评论将会在留言区选出 15名读者,每人送出《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(原书第2版)》一本(在其他公号已获赠本书者重复参加无效)。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月24日 - 2020年10月31日(23:00),活动推送内仅允许中奖一次。

点击阅读原文,直达NeurIPS小组~
登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文