
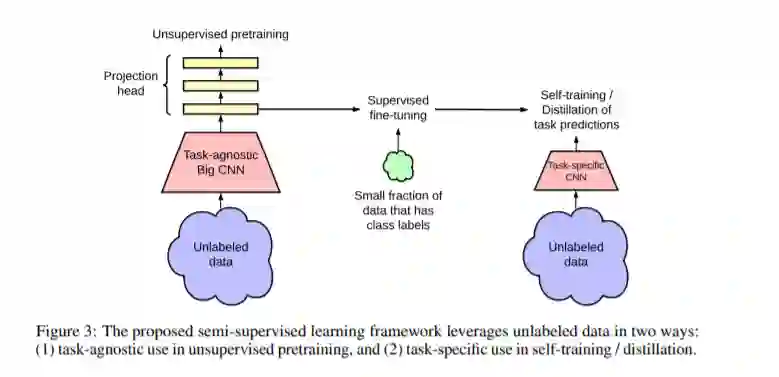
在充分利用大量未标记数据的同时,从少量带标记的样例中学习的一种模式是,先进行无监督的预训练,然后进行有监督的微调。尽管与计算机视觉半监督学习的常见方法相比,这种范式以任务无关的方式使用未标记数据,但我们证明它对于ImageNet上的半监督学习非常有效。我们方法的一个关键要素是在训练前和微调期间使用大的(深度和广度的)网络。我们发现,标签越少,这种方法(使用未标记数据的任务无关性)从更大的网络中获益越多。经过微调后,通过第二次使用未标记的例子,将大的网络进一步改进,并以特定任务的方式将其精简为分类精度损失很小的小网络。本文提出的半监督学习算法可归纳为三个步骤: 使用SimCLRv2对一个大的ResNet模型进行无监督的预训练,对少量带标记的样例进行有监督的微调,以及对未带标记的样例进行精化和传递特定任务的知识。使用ResNet-50,该程序仅使用1%的标签(每个类别≤13张标记图像),就实现了73.9%的ImageNet top-1精度,比以前的最先进的标签效率提高了10倍。对于10%的标签,ResNet-50用我们的方法训练达到77.5%的top-1准确性,优于所有标签的标准监督训练。
https://www.zhuanzhi.ai/paper/0c81b63b2aaae1ae2cc1a9b0fbb382b2
成为VIP会员查看完整内容
相关内容

Arxiv
3+阅读 · 2020年5月13日

相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2020年5月13日