
【导读】图像分类是计算机视觉中的基本任务之一,深度学习的出现是的图像分类技术趋于完善。最近,自监督学习与预训练技术的发展使得图像分类技术出现新的变化,这篇论文概述了最新在实际情况中少标签小样本等情况下,关于自监督学习、半监督、无监督方法的综述,值得看!

地址:
https://www.zhuanzhi.ai/paper/6d160a5f8634d25a2feda7a30e1e5132
摘要
虽然深度学习策略在计算机视觉任务中取得了突出的成绩,但仍存在一个问题。目前的策略严重依赖于大量的标记数据。在许多实际问题中,创建这么多标记的训练数据是不可行的。因此,研究人员试图将未标记的数据纳入到培训过程中,以获得与较少标记相同的结果。由于有许多同时进行的研究,很难掌握最近的发展情况。在这项调查中,我们提供了一个概述,常用的技术和方法,在图像分类与较少的标签。我们比较了21种方法。在我们的分析中,我们确定了三个主要趋势。1. 基于它们的准确性,现有技术的方法可扩展到实际应用中。2. 为了达到与所有标签的使用相同的结果所需要的监督程度正在降低。3.所有方法都共享公共技术,只有少数方法结合这些技术以获得更好的性能。基于这三个趋势,我们发现了未来的研究机会。
1. 概述
深度学习策略在计算机视觉任务中取得了显著的成功。它们在图像分类、目标检测或语义分割等各种任务中表现最佳。
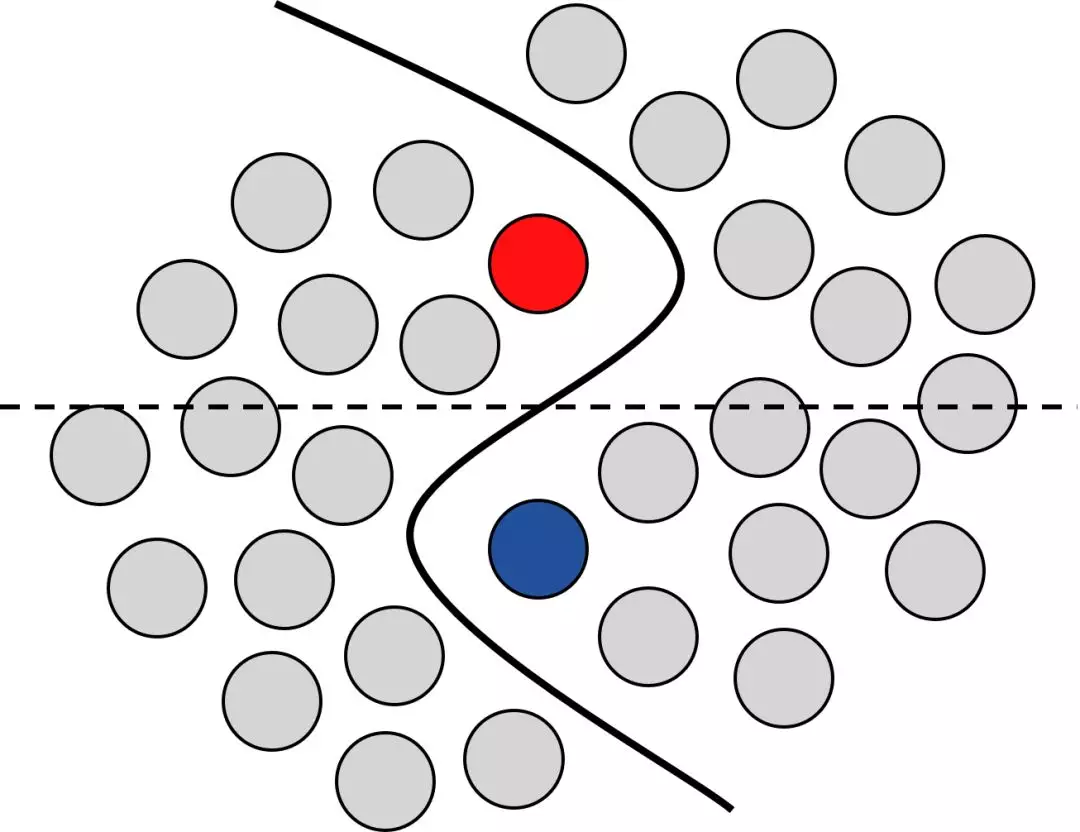
图1: 这张图说明并简化了在深度学习训练中使用未标记数据的好处。红色和深蓝色的圆圈表示不同类的标记数据点。浅灰色的圆圈表示未标记的数据点。如果我们只有少量的标记数据可用,我们只能对潜在的真实分布(黑线)做出假设(虚线)。只有同时考虑未标记的数据点并明确决策边界,才能确定这种真实分布。
深度神经网络的质量受到标记/监督图像数量的强烈影响。ImageNet[26]是一个巨大的标记数据集,它允许训练具有令人印象深刻的性能的网络。最近的研究表明,即使比ImageNet更大的数据集也可以改善这些结果。但是,在许多实际的应用程序中,不可能创建包含数百万张图像的标记数据集。处理这个问题的一个常见策略是迁移学习。这种策略甚至可以在小型和专门的数据集(如医学成像[40])上改进结果。虽然这对于某些应用程序来说可能是一个实际的解决方案,但基本问题仍然存在: 与人类不同,监督学习需要大量的标记数据。
对于给定的问题,我们通常可以访问大量未标记的数据集。Xie等人是最早研究无监督深度学习策略来利用这些数据[45]的人之一。从那时起,未标记数据的使用被以多种方式研究,并创造了研究领域,如半监督、自我监督、弱监督或度量学习[23]。统一这些方法的想法是,在训练过程中使用未标记的数据是有益的(参见图1中的说明)。它要么使很少有标签的训练更加健壮,要么在某些不常见的情况下甚至超过了监督情况下的性能[21]。
由于这一优势,许多研究人员和公司在半监督、自我监督和非监督学习领域工作。其主要目标是缩小半监督学习和监督学习之间的差距,甚至超越这些结果。考虑到现有的方法如[49,46],我们认为研究处于实现这一目标的转折点。因此,在这个领域有很多正在进行的研究。这项综述提供了一个概述,以跟踪最新的在半监督,自监督和非监督学习的方法。
大多数综述的研究主题在目标、应用上下文和实现细节方面存在差异,但它们共享各种相同的思想。这项调查对这一广泛的研究课题进行了概述。这次调查的重点是描述这两种方法的异同。此外,我们还将研究不同技术的组合。
2. 图像分类技术
在这一节中,我们总结了关于半监督、自监督和非监督学习的一般概念。我们通过自己对某些术语的定义和解释来扩展这一总结。重点在于区分可能的学习策略和最常见的实现策略的方法。在整个综述中,我们使用术语学习策略,技术和方法在一个特定的意义。学习策略是算法的一般类型/方法。我们把论文方法中提出的每个算法都称为独立算法。方法可以分为学习策略和技术。技术是组成方法/算法的部分或思想。
2.1 分类方法
监督、半监督和自我监督等术语在文献中经常使用。很少有人给出明确的定义来区分这两个术语。在大多数情况下,一个粗略的普遍共识的意义是充分的,但我们注意到,在边界情况下的定义是多种多样的。为了比较不同的方法,我们需要一个精确的定义来区分它们。我们将总结关于学习策略的共识,并定义我们如何看待某些边缘案例。一般来说,我们根据使用的标记数据的数量和训练过程监督的哪个阶段来区分方法。综上所述,我们把半监督策略、自我学习策略和无监督学习策略称为reduced减约监督学习策略。图2展示了四种深度学习策略。
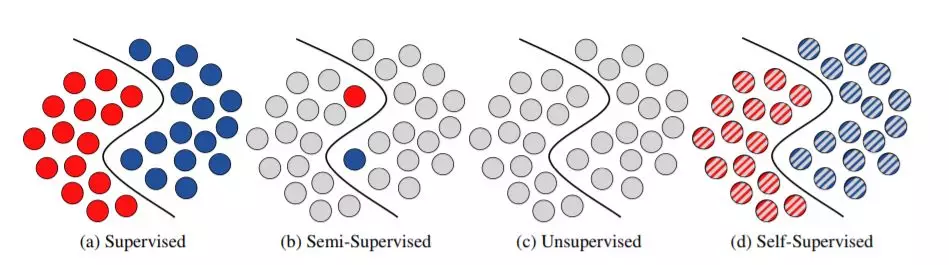
图2: 插图的四个深学习策略——红色和深蓝色的圆圈表示标记数据点不同的类。浅灰色的圆圈表示未标记的数据点。黑线定义了类之间的基本决策边界。带条纹的圆圈表示在训练过程的不同阶段忽略和使用标签信息的数据点。
监督学习 Supervised Learning
监督学习是深度神经网络图像分类中最常用的方法。我们有一组图像X和对应的标签或类z。设C为类别数,f(X)为X∈X的某个神经网络的输出,目标是使输出与标签之间的损失函数最小化。测量f(x)和相应的z之间的差的一个常用的损失函数是交叉熵。
迁移学习
监督学习的一个限制因素是标签的可用性。创建这些标签可能很昂贵,因此限制了它们的数量。克服这一局限的一个方法是使用迁移学习。
迁移学习描述了训练神经网络的两个阶段的过程。第一个阶段是在大型通用数据集(如ImageNet[26])上进行有无监督的训练。第二步是使用经过训练的权重并对目标数据集进行微调。大量的文献表明,即使在小的领域特定数据集[40]上,迁移学习也能改善和稳定训练。
半监督学习
半监督学习是无监督学习和监督学习的混合.
Self-supervised 自监督学习
自监督使用一个借托pretext任务来学习未标记数据的表示。借托pretext任务是无监督的,但学习表征往往不能直接用于图像分类,必须进行微调。因此,自监督学习可以被解释为一种无监督的、半监督的或其自身的一种策略。我们将自我监督学习视为一种特殊的学习策略。在下面,我们将解释我们是如何得出这个结论的。如果在微调期间需要使用任何标签,则不能将该策略称为无监督的。这与半监督方法也有明显的区别。标签不能与未标记的数据同时使用,因为借托pretext任务是无监督的,只有微调才使用标签。对我们来说,将标记数据的使用分离成两个不同的子任务本身就是一种策略的特征。
2.2 分类技术集合
在减少监督的情况下,可以使用不同的技术来训练模型。在本节中,我们将介绍一些在文献中多种方法中使用的技术。
一致性正则化 Consistency regularization
一个主要的研究方向是一致性正则化。在半监督学习过程中,这些正则化被用作数据非监督部分的监督损失的附加损失。这种约束导致了改进的结果,因为在定义决策边界时可以考虑未标记的数据[42,28,49]。一些自监督或无监督的方法甚至更进一步,在训练中只使用这种一致性正则化[21,2]。
虚拟对抗性训练(VAT)
VAT[34]试图通过最小化图像与转换后的图像之间的距离,使预测不受小转换的影响。
互信息(MI)
MI定义为联合分布和边缘分布[8]之间的Kullback Leiber (KL)散度。
熵最小化(EntMin)
Grandvalet和Bengio提出通过最小化熵[15]来提高半监督学习的输出预测。
Overclustering
过度聚类在减少监督的情况下是有益的,因为神经网络可以自行决定如何分割数据。这种分离在有噪声的数据中或在中间类被随机分为相邻类的情况下是有用的。
Pseudo-Labels
一种估计未知数据标签的简单方法是伪标签
3. 图像分类模型
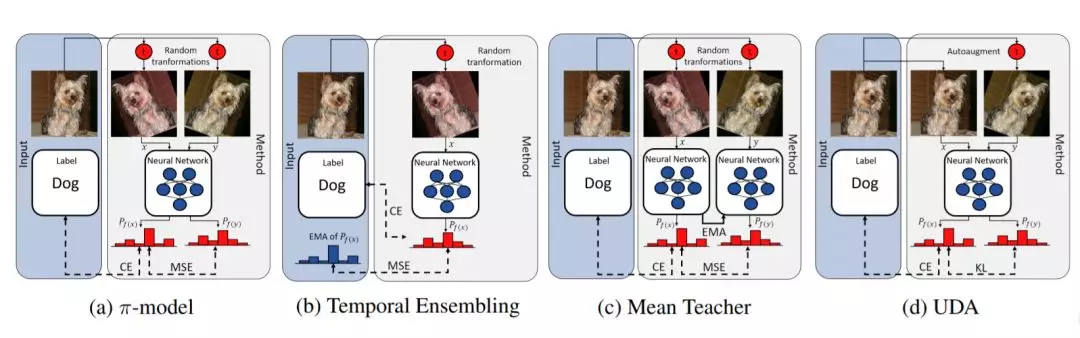
3.1 半监督学习
3.2 自监督学习
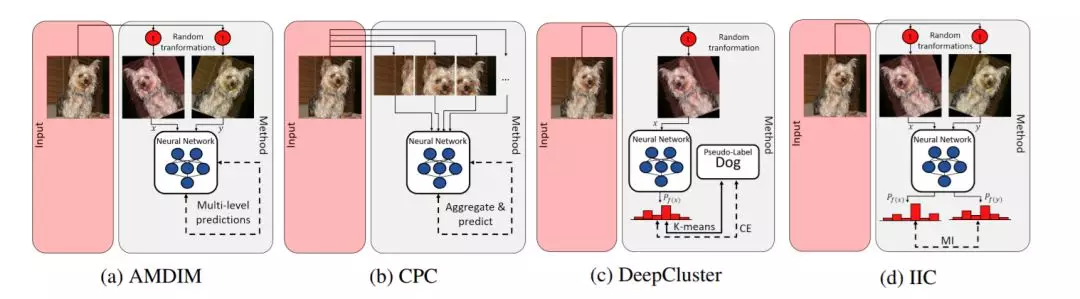
四种选择的自我监督方法的图解——使用的方法在每张图像下面给出。输入在左边的红色方框中给出。在右侧提供了该方法的说明。微调部分不包括在内。一般来说,这个过程是自上而下组织的。首先,对输入图像进行一两次随机变换预处理或分割。下面的神经网络使用这些预处理图像(x, y)作为输入。损失的计算(虚线)对于每种方法都是不同的。AMDIM和CPC使用网络的内部元素来计算损失。DeepCluster和IIC使用预测的输出分布(Pf(x)、Pf(y))来计算损耗
3.3 21种图像分类方法比较
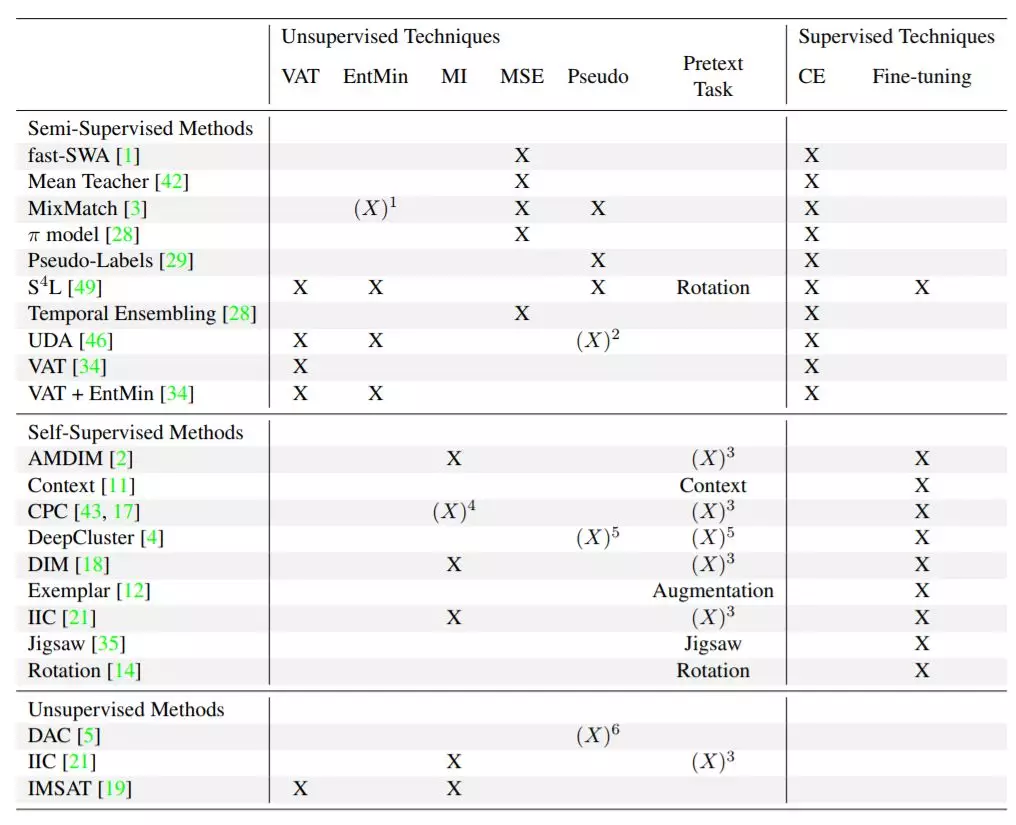
21种图像分类方法及其使用技术的概述——在左侧,第3节中回顾的方法按学习策略排序。第一行列出了在2.2小节中讨论过的可能的技术。根据是否可以使用带标签的数据,将这些技术分为无监督技术和有监督技术。技术的缩写也在第2.2小节中给出。交叉熵(Cross-entropy, CE)将CE的使用描述为训练损失的一部分。微调(FT)描述了交叉熵在初始训练后(例如在一个借口任务中)对新标签的使用。(X)指该技术不是直接使用,而是间接使用。个别的解释由所指示的数字给出。1 - MixMatch通过锐化预测[3],隐式地实现了熵最小化。2 - UDA预测用于过滤无监督数据的伪标签。3 -尽量减少相互信息的目的作为借口任务,例如视图之间的[2]或层之间的[17]。4 -信息的丢失使相互信息间接[43]最大化。5 - Deep Cluster使用K-Means计算伪标签,以优化分配为借口任务。6 - DAC使用元素之间的余弦距离来估计相似和不相似的项。可以说DAC为相似性问题创建了伪标签。
4. 实验比较结果
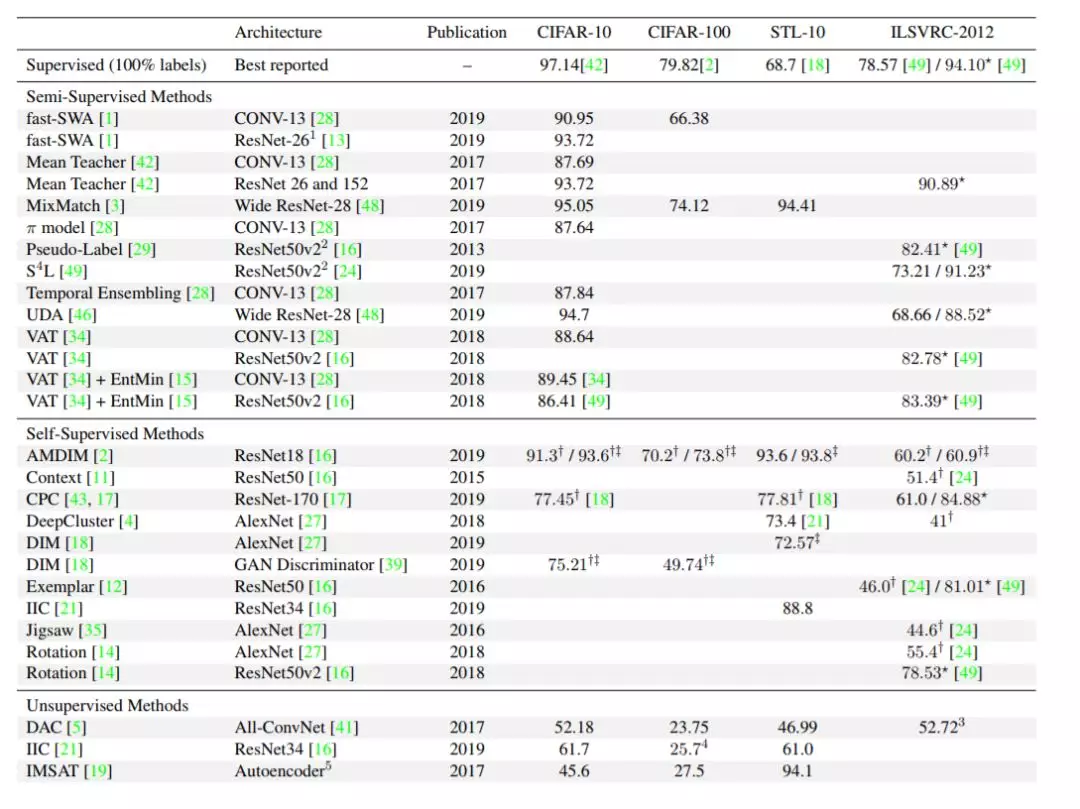
报告准确度的概述——第一列说明使用的方法。对于监督基线,我们使用了最好的报告结果,作为其他方法的基线。原始论文在准确度后的括号内。第二列给出了体系结构及其参考。第三列是预印本的出版年份或发行年份。最后四列报告了各自数据集的最高准确度分数%。
5 结论
在本文中,我们概述了半监督、自监督和非监督技术。我们用21种不同的方法分析了它们的异同和组合。这项分析确定了几个趋势和可能的研究领域。
我们分析了不同学习策略(半监督学习策略、自监督学习策略和无监督学习策略)的定义,以及这些学习策略中的常用技术。我们展示了这些方法一般是如何工作的,它们使用哪些技术,以及它们可以被归类为哪种策略。尽管由于不同的体系结构和实现而难以比较这些方法的性能,但我们确定了三个主要趋势。
ILSVRC-2012的前5名正确率超过90%,只有10%的标签表明半监督方法适用于现实问题。然而,像类别不平衡这样的问题并没有被考虑。未来的研究必须解决这些问题。
监督和半监督或自监督方法之间的性能差距正在缩小。有一个数据集甚至超过了30%。获得可与全监督学习相比的结果的标签数量正在减少。未来的研究可以进一步减少所需标签的数量。我们注意到,随着时间的推移,非监督方法的使用越来越少。这两个结论使我们认为,无监督方法在未来的现实世界中对图像分类将失去意义。
我们的结论是,半监督和自监督学习策略主要使用一套不同的技术。通常,这两种策略都使用不同技术的组合,但是这些技术中很少有重叠。S4L是目前提出的唯一一种消除这种分离的方法。我们确定了不同技术的组合有利于整体性能的趋势。结合技术之间的微小重叠,我们确定了未来可能的研究机会。
参考文献:
[1] B. Athiwaratkun, M. Finzi, P. Izmailov, and A. G. Wilson. There are many consistent explanations of unlabeled data: Why you should average. In International Conference on Learning Representations, 2019.
[2] P. Bachman, R. D. Hjelm, and W. Buchwalter. Learning representations by maximizing mutual information across views. In Advances in Neural Information Processing Systems, pages 15509–15519, 2019.
[3] D. Berthelot, N. Carlini, I. Goodfellow, N. Papernot, A. Oliver, and C. A. Raffel. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems, pages 5050–5060, 2019.
[4] M. Caron, P. Bojanowski, A. Joulin, and M. Douze. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), pages 132–149, 2018.
[5] J. Chang, L. Wang, G. Meng, S. Xiang, and C. Pan. Deep adaptive image clustering. 2017 IEEE International Conference on Computer Vision (ICCV), pages 5880–5888, 2017.



