
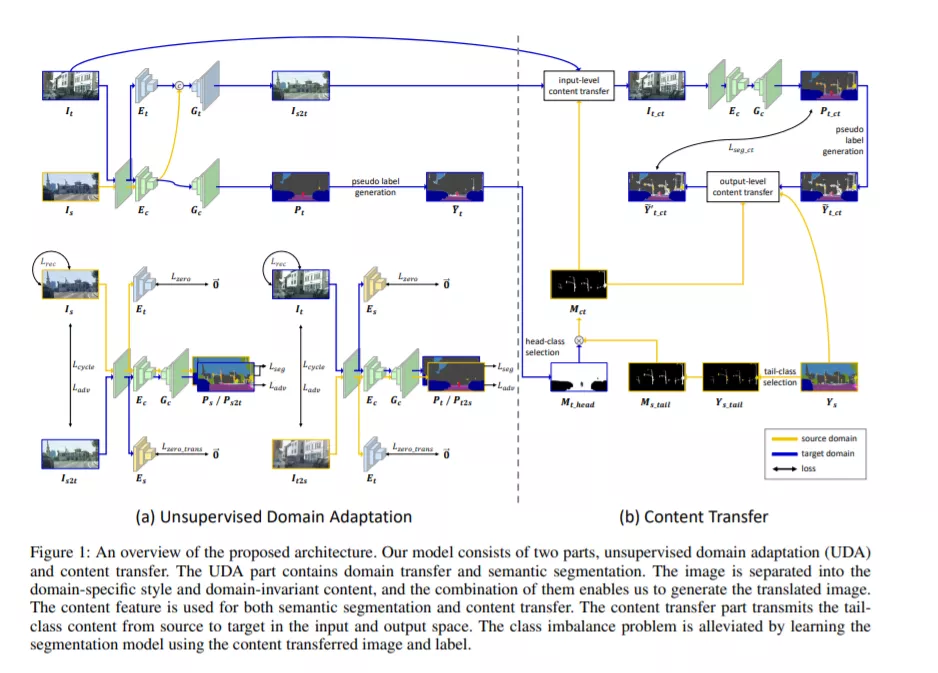
在本文中,我们提出了一种用于语义分割的无监督域自适应算法,该算法的目标是利用有标记的合成数据来分割无标记的真实数据。UDA语义分割的主要问题在于缩小真实图像与合成图像之间的域差距。为了解决这个问题,我们将重点放在将图像中的信息分离为内容和样式。在这里,只有内容具有进行语义分割的线索,而风格造成了领域差距。因此,即使在使用合成数据进行学习时,也可以将图像中的内容和风格进行精确的分离,起到监督真实数据的作用。为了充分利用这种效果,我们提出采用零损失模式。尽管我们在实域上很好地提取了用于语义分割的内容,但在语义分类器中仍然存在类别不平衡的问题。我们通过将尾部类的内容从合成域转移到实域来解决这个问题。实验结果表明,该方法在两种主要的神经网络环境下都取得了最先进的语义分割性能。
成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2019年1月17日
相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年1月17日