
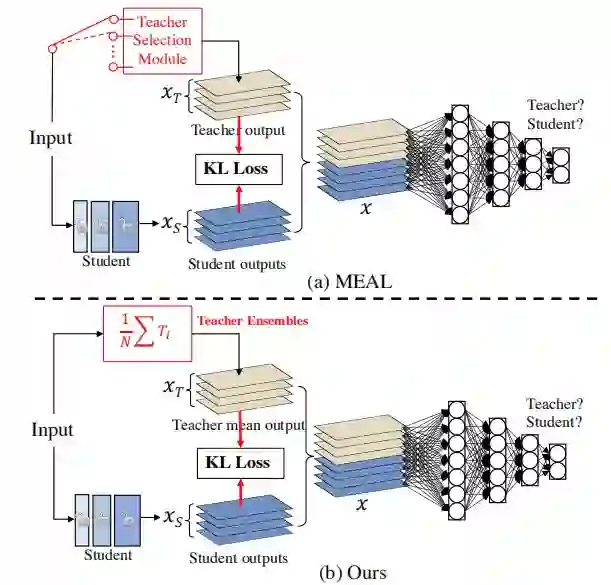
该文提出一种简单而有效的方法,无需任何tricks,它可以将标准ResNet50的Top1精度提升到80%+。该方法是基于作者之前MEAL(通过判别方式进行知识蒸馏集成)改进而来,作者对MEAL进行了以下两点改进:
(1) 仅在最后的输出部分使用相似性损失与判别损失;
(2) 采用所有老师模型的平均概率作为更强的监督信息进行蒸馏。
该文提到一个非常重要的发现:在蒸馏阶段不应当使用one-hot方式的标签编码。这样一种简单的方案可以取得SOTA性能,且并未用到以下几种常见涨点tricks:(1)类似ResNet50-D的架构改进;(2)额外训练数据;(3) AutoAug、RandAug等;(4)cosine学习率机制;(5)mixup/cutmix数据增广策略;(6) 标签平滑。
在ImageNet数据集上,本文所提方法取得了80.67%的Top1精度(single crop@224),以极大的优势超越其他同架构方案。该方法可以视作采用知识蒸馏对ResNet50涨点的一个新的基准,该文可谓首个在不改变网路架构、无需额外训练数据的前提下将ResNet提升到超过80%Top1精度的方法。
成为VIP会员查看完整内容
相关内容
相关主题

相关VIP内容
相关资讯
相关论文