CVPR 2018 | 无监督语义分割之全卷积域适应网络

论文地址:https://arxiv.org/abs/1804.08286
背景介绍
众所周知,当前大部分的语义分割算法都需要大量有标签的数据集(如CityScape等)进行训练,通过精细的网络结构设计和复杂的后处理,性能的提升已经到达一个瓶颈。然而,这些像素级的标注信息的获取代价是非常巨大的。针对这一问题,有学者提出了通过游戏引擎来合成自动驾驶场景下的图像数据,同时得到像素级的语义标签,避免了标注真实图像所需要耗费的大量人力物力。
但是,随之带来的问题是,合成图像上训练的模型能否适用于真实图像?答案是否定的,因为合成图像和真实图像的数据分布存在巨大的偏差,也叫domain shift,如何解决这一domain shift问题,使得利用合成数据训练得到的模型能很好地迁移到真实图像上,是本文探索的一个问题。
域适配(Domain Adaptation, DA)问题已经在图像分类任务上得到了广泛研究,今年CVPR上也有很多相关工作。其本质属于迁移学习的一种,问题设定是:如何使得源域(Source Domain)上训练好的分类器能够很好地迁移到没有标签数据的目标域上(Target Domain)上。这种域适配问题在语义分割中同样存在,在本文中具体体现为合成图像和真实图像直接的Domain Adaptation。
如下图所示,来自游戏引擎的合成图像和来自自动驾驶场景的真实图像还是有显著区别的,如果用合成图像训练好的模型对真实图像直接进行测试,得到的是如图1(a)所示的结果,第一直觉发现效果很差,而图1(b)所示的结果是经过本文的DA算法得到的语义分割结果,可以发现较图1(a)有了非常明显的提升。值得注意的是,本文算法的整个训练过程中是不需要利用真实图像的标签数据的,因此可以称为一种无监督语义分割方法。

解决思路
针对合成图像和真实图像之间的域适应问题,本文主要提出了两种域适应策略,分别是图像层面的域适应(Appearance Adaptation)和特征表示层面的域适应(Representation Adaptation),具体实现为两个网络架构:图像域适应网络(Appearance Adaptation Networks,AAN)和特征适应网络(Representation Adaptation Networks,RAN)。整体网络架构如下图所示:
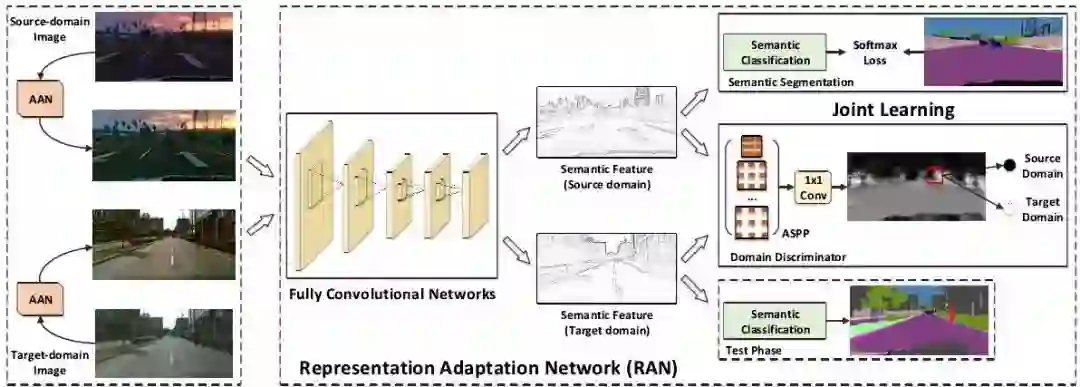
上图给出了本文方法的处理流程,左侧的AAN负责对合成图像进行转换,使得生成的图像在内容上依然保留原始合成图像的内容,但在风格上要非常接近真实场景中的图像,右侧的RAN本质上是一个生成对抗网络GAN,其目的都是使得基础网络FCN提取的特征具有域不变性,也即要使得不管是来自合成图像还是来自真实图像,提取的特征应该分布在同一个特征空间上。结合上图下面重点论述本文提出的以上两个域适应网络:
1、Appearance Adaptation Networks
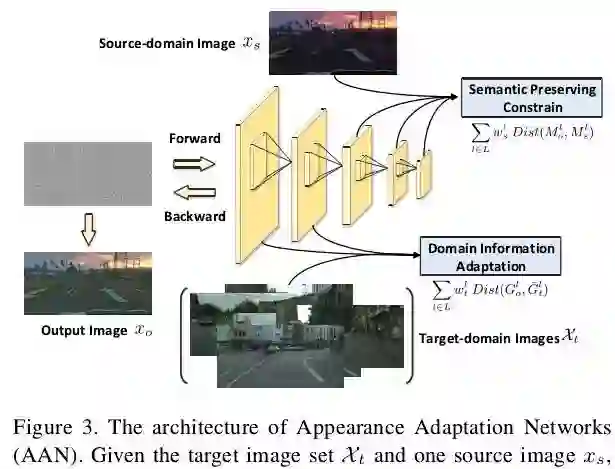
图3展示了图像域适应网络AAN的具体细节和处理流程,熟悉style transfer的同学其实已经发现了它本质上就是一个图像风格转换网络,其实现思路也是和CVPR2016的这篇文章[1]类似的,这里简单阐明一下实现思路:输入是一张高斯白噪声图像,输出图像是在网络反向传播的过程中不断更新得到的,训练的损失函数包含两部分:内容上和合成图像尽可能接近,风格上和真实图像尽可能接近,因此整个AAN的损失函数如下式所示:
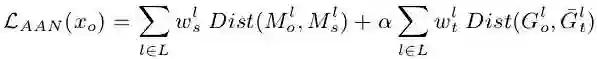
2、Representation Adaptation Networks
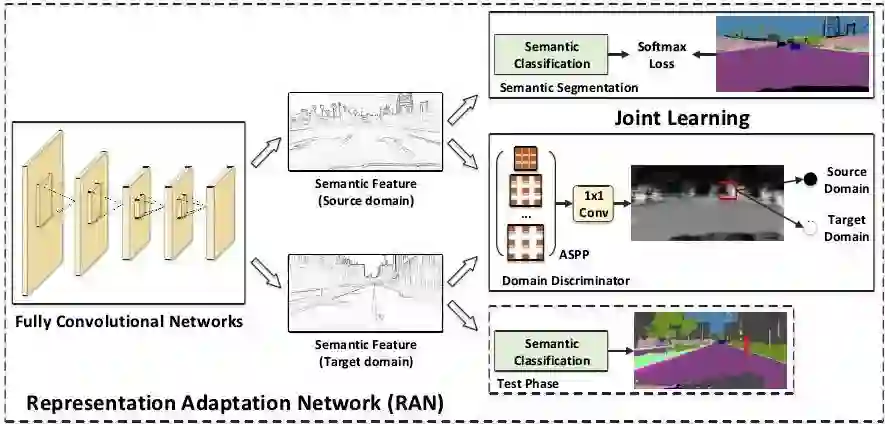
RAN的目的是为了使得基础网络FCN提取的特征具有域不变性,其本质上是个生成对抗网络,其中的生成器G是上图中的基础网络Fully Convolutional Networks,用于提取来自两个域的图像特征;判别器D是上图中的Domain Discriminator,用于判别特征来自源域还是目标域。对于源域的合成图像而言,该特征分别输入两个分支:一是上图中的语义分割分支,利用合成图像的标签进行有监督训练,损失函数是正常的逐像素分类损失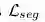
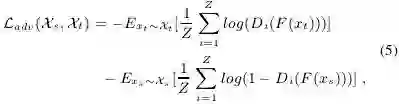
因此,整个RAN训练的损失函数包括两个部分:语义分割损失和对抗损失,优化下式就可以端到端进行训练了。
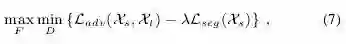
在测试时,将真实图像输入基础网络和语义分割分支就可以得到结果。
实验分析
1、AAN的实验分析
实验用GTA5合成图像数据集作为源域,CityScape和BDDS两个数据集作为目标域分别进行实验。论文是实验分析主要基于CityScape数据集。评估指标采用语义分割任务中常用的mIOU。

从上图可以发现AAN可以成功将GAT5和Cityscape中的图像进行转换,保留原图中的内容并转换成目标域图像的风格。
2、RAN的实验分析
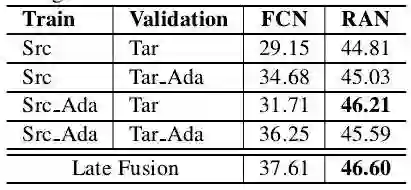
从上表中可以发现本文提出的RAN较原始的FCN可以带来非常明显的性能提升,充分验证了进行特征层面的域适应非常有必要,基本可以提升10个点以上。同时从第一列和第四列的结果对比中可以发现图像层面的域适应也有7个点左右的性能提升。总之经过本文算法连个层面的域适应策略,将CityScape上的语义分割性能从原始的29.15提升到了46.60。
总结展望
本文贡献:
(1)提出了语义分割任务中的域适应问题:如何利用合成数据有效提升真实场景中的语义分割性能;
(2)提出了两个层面的域适应策略(图像层面的域适应和特征层面的域适应),用于解决该问题。
个人见解:
(1)熟悉style transfer的同学可能知道,本文的AAN主要借鉴了[1]中的风格转换思想,并将其成功应用于合成图像向真实图像的转换;本文的RAN主要借鉴了图像分类任务中利用对抗网络解决无监督域适应的思路,详见[2]。作者成功将这两种想法成功迁移到语义分割任务中,并充分证明了这两种策略在语义分割任务中非常有效。
(2)域适应问题近年来得到了广泛关注,该问题在目标检测领域同样存在,并有相关工作发表于CVPR2018[3],极市已有技术文章对[3]进行解读。不可否认的是,对域适应问题的解决是CV算法迈向现实应用的重要一步。
参考文献
[1] Image Style Transfer Using Convolutional Neural Networks. CVPR (2016)
[2] Adversarial Discriminative Domain Adaptation. CVPR (2017)
[3] Domain Adaptive Faster R-CNN for Object Detection in the Wild. CVPR(2018)
注:[3]已有论文解读发表于极市技术平台:
CVPR 2018 | ETH Zurich提出利用对抗策略,解决目标检测的域适配问题
本文为极市原创文章,转载请至微信公众号后台留言,同时欢迎大家投稿~
*推荐文章*
CVPR 2018 | 牛津大学&Emotech首次严谨评估语义分割模型对对抗攻击的鲁棒性
一文概览主要语义分割网络:FCN,SegNet,U-Net...
PS.极市平台诚招计算机视觉算法工程师啦~工作要求请关注“极市平台”公众号(id:extrememart),点击菜单加入极市“诚招”栏或直接私信小助手(微信:Extreme-Vision),欢迎大牛来戳~




