
题目
自监督图像分类:Self-training with Noisy Student improves ImageNet classification
关键字
图像分类,自监督学习,计算机视觉,深度学习,人工智能
简介
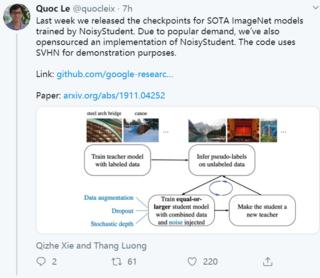
我们提出了一种简单的自我训练方法,该方法可在ImageNet上达到88.4%的top-1准确性,这比要求3.5B弱标记Instagram图像的最新模型高2.0%。在健壮性测试集上,它将ImageNet-A top-1的准确性从61.0%提高到83.7%,将ImageNet-C的平均损坏错误从45.7降低到28.3,并将ImageNet-P的平均翻转率从27.8降低到12.2。
为了获得此结果,我们首先在标记的ImageNet图像上训练EfficientNet模型,并将其用作教师,以在300M未标记的图像上生成伪标记。然后,我们将更大的EfficientNet训练为带有标记和伪标记图像组合的学生模型。我们通过让学生作为老师来迭代此过程。在伪标签的生成过程中,不会对教师产生干扰,从而使伪标签尽可能准确。但是,在学生学习期间,我们通过RandAugment向学生注入诸如辍学,随机深度和数据增强之类的噪声,从而使学生的普遍性优于老师。
作者
Qizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le
成为VIP会员查看完整内容
相关内容

专知会员服务
29+阅读 · 2020年3月27日




相关VIP内容
专知会员服务
29+阅读 · 2020年3月27日
相关资讯
相关论文