成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
半监督学习
关注
2924
半监督学习(Semi-Supervised Learning,SSL)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性,因此,半监督学习目前正越来越受到人们的重视。
综合
百科
VIP
热门
动态
论文
精华
精品内容
标注受限场景下的视觉表征与理解
专知会员服务
14+阅读 · 2月6日
【斯坦福博士论文】推动医学人工智能发展的数据高效算法
专知会员服务
28+阅读 · 2024年12月1日
【牛津大学博士论文】探索用于半监督学习的概率模型,127页pdf
专知会员服务
26+阅读 · 2024年6月15日
[ICML2024]消除偏差:微调基础模型以进行半监督学习
专知会员服务
17+阅读 · 2024年5月23日
【剑桥大学博士论文】主动学习和半监督学习在语音识别中的应用,238页pdf
专知会员服务
30+阅读 · 2024年4月13日
【牛津大学博士论文】探索半监督学习的概率模型,127页pdf
专知会员服务
40+阅读 · 2024年4月8日
基于图神经网络的高光谱图像分类研究进展
专知会员服务
29+阅读 · 2023年7月23日
【KDD2023】半监督图不平衡回归
专知会员服务
26+阅读 · 2023年5月24日
【词汇表征】《多模态表示的半监督学习》美国空军、宾夕法尼亚大学等最新74页项目总结报告
专知会员服务
27+阅读 · 2022年10月30日
德国蒂宾根大学最新《半监督和无监督深度视觉学习》综述,22页pdf涵盖322篇文献阐述SSL与UL分类
专知会员服务
38+阅读 · 2022年8月26日
监督和半监督学习下的多标签分类综述
专知会员服务
46+阅读 · 2022年8月3日
北航等最新《深度半监督学习医学图像分割》综述,16页pdf阐述医学图像分割的半监督学习方法体系
专知会员服务
63+阅读 · 2022年8月2日
上海交大最新《标签高效深度分割》研究进展综述,全面阐述无监督、粗监督、不完全监督和噪声监督的深度分割方法
专知会员服务
42+阅读 · 2022年7月7日
小数据如何学习?佐治亚理工杨笛一等《有限文本数据学习》ACL2022教程,阐述最新前沿技术,附Slides
专知会员服务
34+阅读 · 2022年5月23日
【CVPR2022】开放集半监督图像生成
专知会员服务
23+阅读 · 2022年5月3日
参考链接
父主题
机器学习
数据挖掘
子主题
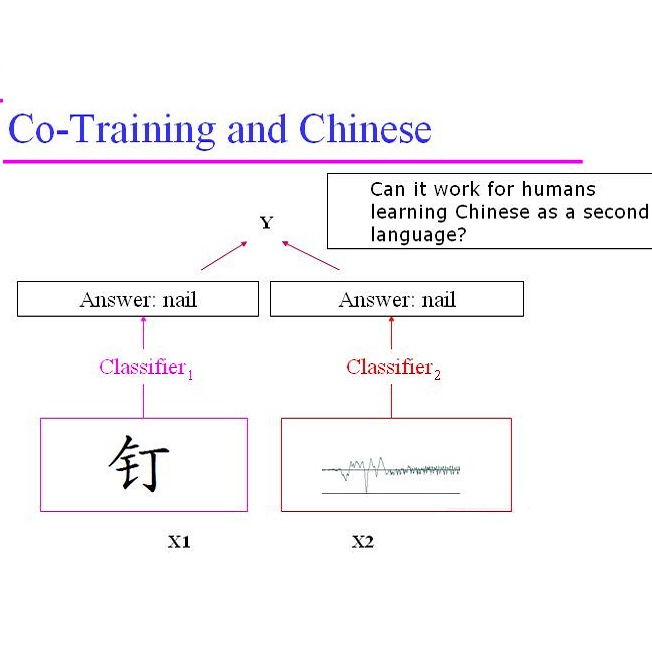
Co-training
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top