集多种半监督学习范式为一体,谷歌新研究提出新型半监督方法 MixMatch
选自arXiv
作者:David Berthelot等
机器之心编译
参与:王子嘉、路
谷歌研究者通过融合多种主流半监督学习范式,提出了一种新算法 MixMatch。该算法在多个数据集上获得了当前最优结果,且明显优于次优算法。
事实证明,半监督学习可以很好地利用无标注数据,从而减轻对大型标注数据集的依赖。而谷歌的一项研究将当前主流的半监督学习方法统一起来,得到了一种新算法 MixMatch。该算法可以为数据增强得到的无标注样本估计(guess)低熵标签,并利用 MixUp 来混合标注和无标注数据。实验表明,MixMatch 在许多数据集和标注数据上获得了 STOA 结果,展现出巨大优势。例如,在具有 250 个标签的 CIFAR-10 数据集上,MixMatch 将错误率降低了 71%(从 38% 降至 11%),在 STL-10 上错误率也降低了 2 倍。对于差分隐私 (differential privacy),MixMatch 可以在准确率与隐私间实现更好的权衡。最后,研究者通过模型简化测试对 MixMatch 进行了分析,以确定哪些组件对该算法的成功最为重要。
缺少数据怎么办
近期大型深度神经网络取得的成功很大程度上归功于大型标注数据集的存在。然而,对于许多学习任务来说,收集标注数据成本很高,因为它必然涉及专家知识。医学领域就是一个很好的例子,在医学任务中,测量数据出自昂贵的机器,标签则来自于多位人类专家耗时耗力的分析。此外,数据标签可能包含一些隐私类的敏感信息。相比之下,在许多任务中,获取无标注数据要容易得多,成本也低得多。
半监督学习 (SSL) 旨在通过在模型中使用无标注数据,来大大减轻对标注数据的需求。近期许多半监督学习方法都增加了一个损失项,该损失项基于无标注数据计算,以促进模型更好地泛化到未知数据。在最近的工作中,该损失项一般分为三类:熵最小化 [17, 28]——促使模型输出对无标注数据的可信预测;一致性正则化(consistency regularization)——促使模型在其输入受到扰动时产生相同的输出分布;通用正则化(generic regularization)——促使模型很好地泛化,并避免出现对训练数据的过拟合。
谷歌的解决方案
谷歌的这项研究中介绍了一种新型半监督学习算法 MixMatch。该算法引入了单个损失项,很好地将上述主流方法统一到半监督学习中。与以前的方法不同,MixMatch 同时针对所有属性,从而带来以下优势:
实验表明,MixMatch 在所有标准图像基准上都获得了 STOA 结果。例如,在具备 250 个标签的 CIFAR-10 数据集上获得了 11.08% 的错误率(第二名的错误率为 38%);
模型简化测试表明,MixMatch 比其各部分的总和要好;
MixMatch 有助于差分隐私学习 (differentially private learning),使 PATE 框架 [34] 中的学生能够获得新的 STOA 结果,该结果在增强隐私保障的同时,也提升了准确率。
简而言之,MixMatch 为无标注数据引入了一个统一的损失项,它在很好地减少了熵的同时也能够保持一致性,以及保持与传统正则化技术的兼容。
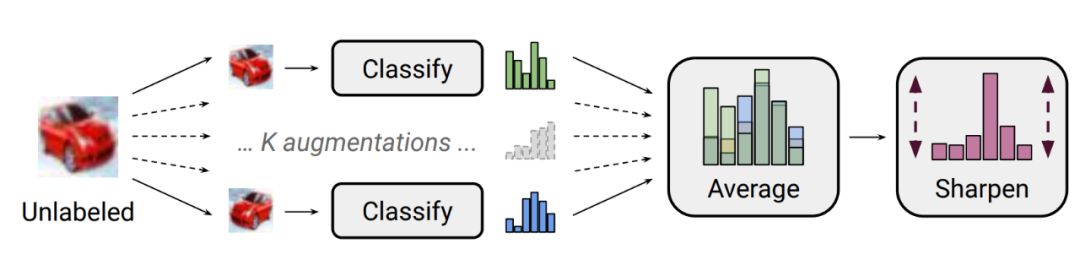
图 1:MixMatch 中使用的标签估计过程图。对无标注图像使用 k 次随机数据增强,并将每张增强图像馈送到分类器中。然后,通过调整分布的温度来「锐化」这 K 次预测的平均值。完整说明参见算法 1。
MixMatch
半监督学习方法 MixMatch 是一种「整体」方法,它结合了半监督学习主流范式的思想和组件。给定一组标注实例 X 及其对应的 one-hot 目标(代表 L 个可能标签中的一个)和一组同样大小的无标注实例 U,MixMatch 可以生成一组增强标注实例 X' 和一组带有「估计」标签的增强无标注实例 U'。然后分别使用 U' 和 X' 计算无标注损失和标注损失。下式即为半监督学习的组合损失 L:
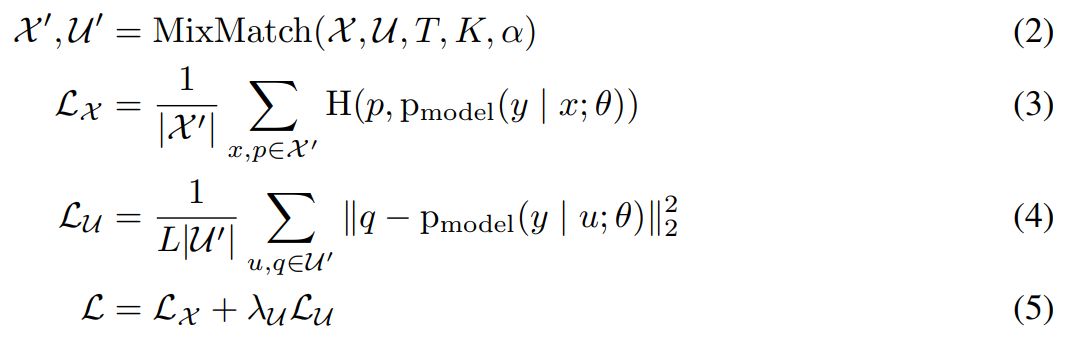
其中 H(p, q) 是分布 p 和 q 之间的交叉熵,T、K、α 和 λ_U 是下面算法 1 中的超参数。下图展示了完整的 MixMatch 算法和图 1 中展示的标签估计过程。

实验
为了测试 MixMatch 的有效性,研究者在半监督学习基准上测试其性能,并执行模型简化测试,梳理 MixMatch 各个组件的作用。
研究者首先评估了 MixMatch 在四个基准数据集上的性能,分别是 CIFAR-10、CIFAR-100、SVHN 和 STL-10。其中前三个数据集是监督学习常用的图像分类基准;利用这些数据集评估半监督学习的标准方法是将数据集中的大部分数据视为无标注的,将一小部分(例如几百或数千个标签)作为标注数据。STL-10 是专为半监督学习设计的数据集,包含 5000 个标注图像和 100,000 个无标注图像,无标注图像的分布与标注数据略有不同。
对于 CIFAR-10,研究者使用 250 到 4000 个不同数量的标注样本来评估每种方法的准确率(标准做法)。结果如图 2 所示。
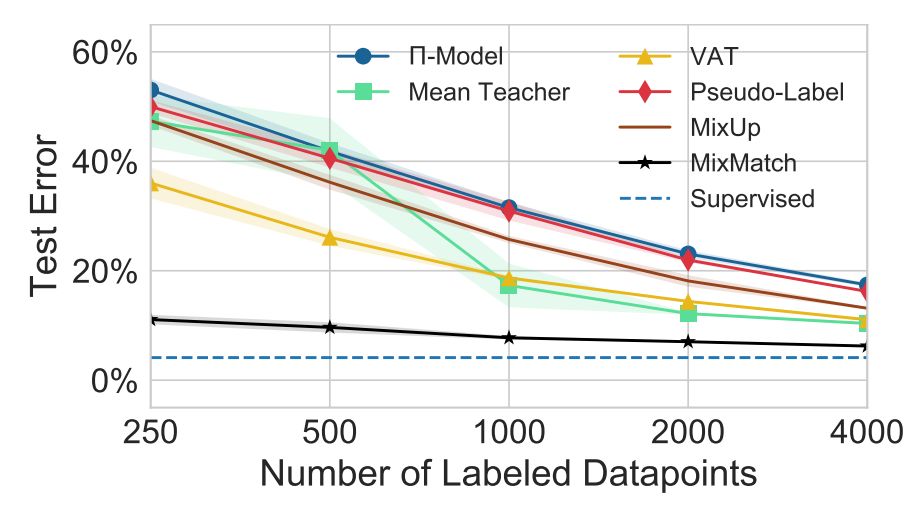
图 2:对于不同数量的标签,MixMatch 与基线方法在 CIFAR-10 上的错误率对比。「Supervised」表示所有 50000 个训练样本都是标注数据。当使用 250 个标注数据时,MixMatch 的错误率与使用 4000 个标签的次优方法性能相当。
研究者还在具备 10000 个标签的 CIFAR-100 数据集上评估了基于较大模型的 MixMatch,并与 [2] 的结果进行了对比。结果如表 1 所示。
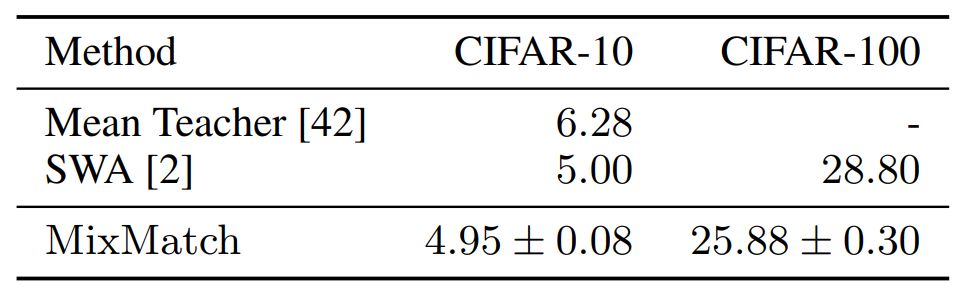
表 1:使用较大模型(2600 万个参数)在 CIFAR-10 和 CIFAR-100 数据集上的错误率对比。
作为标准方法,研究者首先考虑将有 73257 个实例的训练集分割为标注数据和无标注数据的情况。结果如图 3 所示。
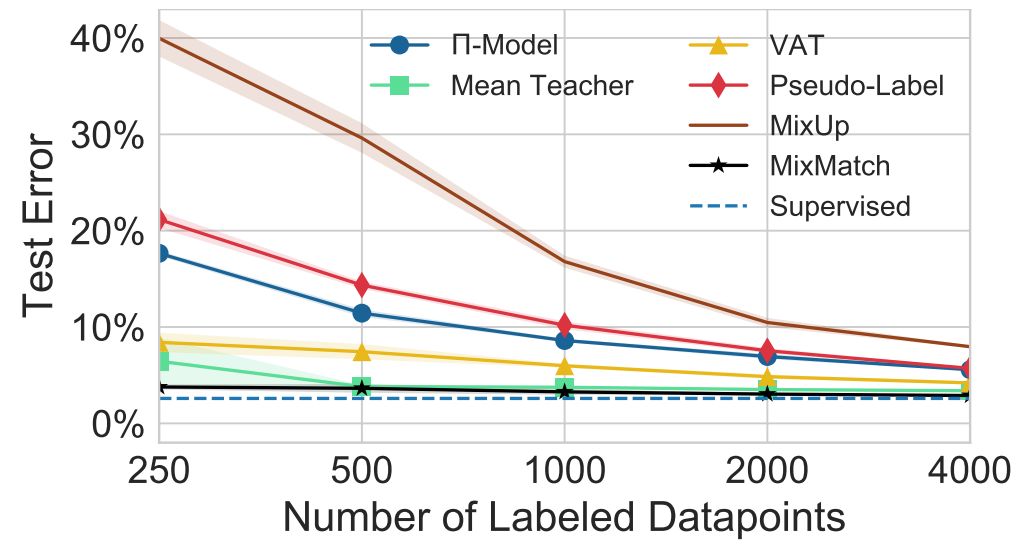
图 3:使用不同数量的标签时,MixMatch 与基线方法在 SVHN 数据集上的错误率比较。「Supervised」指所有 73257 个训练实例均为标注数据。在使用 250 个标注样本时,MixMatch 就几乎达到了 Supervised 模型的监督训练准确率。
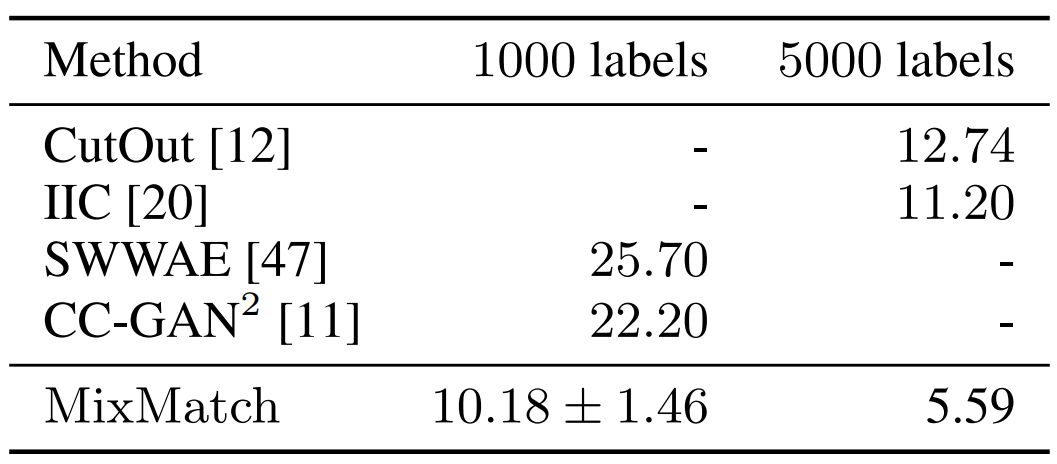
表 2:MixMatch 与其他方法在 STL-10 数据集上的错误率对比,分为全为标注数据(5000 个)与只使用 1000 个标注数据(其余为无标注数据)两种实验设置。
由于 MixMatch 结合了多种半监督学习机制,它与文献中已有的方法有很多相似之处。因此,研究者通过增删模型组件研究各个组件对模型性能的影响,以便更好地了解哪些组件为 MixMatch 提供更多贡献。
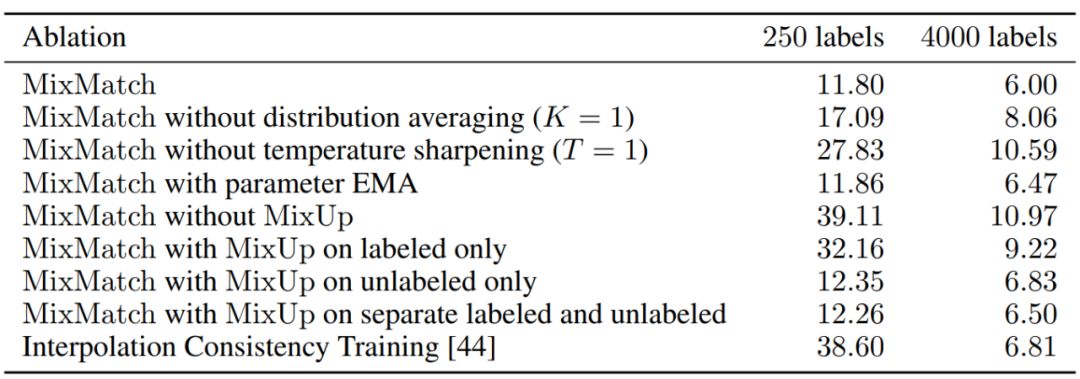
表 4:模型简化测试结果。MixMatch 及其各种「变体」在 CIFAR-10 数据集上的错误率对比,分为 250 个标注数据和 4000 个标注数据两种情况。ICT 使用 EMA 参数和无标注 mixup,无锐化。
目前,该研究代码已公开。GitHub 地址:https://github.com/google-research/mixmatch
论文链接:https://arxiv.org/abs/1905.02249
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



