
题目: On the Generalization Benefit of Noise in Stochastic Gradient Descent
摘要:
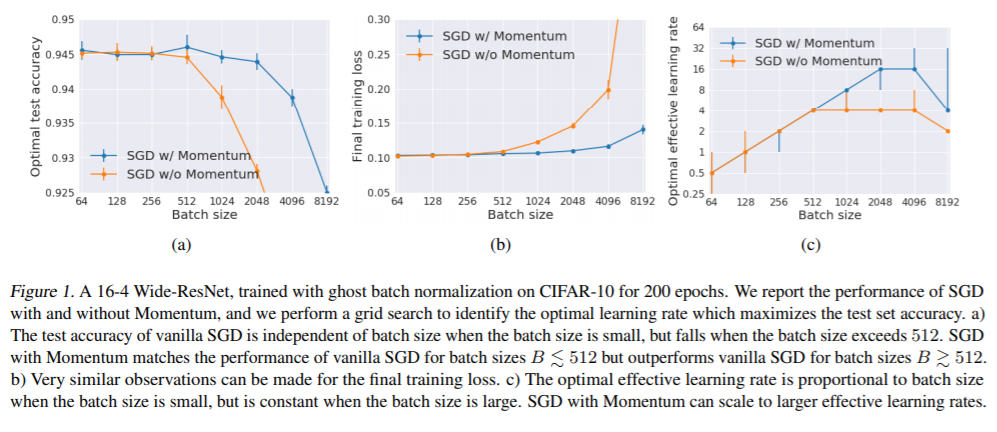
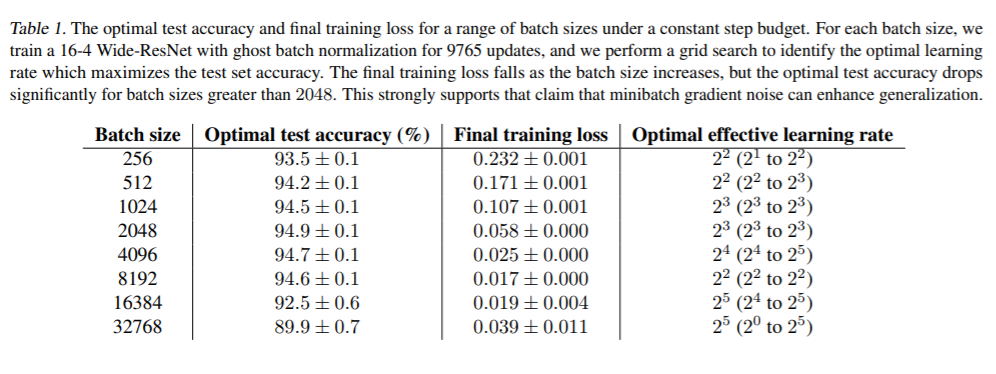
长期以来一直有人认为,在深度神经网络中,小批量随机梯度下降比大批量梯度下降具有更好的泛化能力。但是,最近的论文对此主张提出了质疑,认为这种影响仅是批处理量较大时超优化超参数调整或计算预算不足的结果。在本文中,我们对一系列流行的模型进行了精心设计的实验并进行了严格的超参数扫描,这证明了小批量或中等批量都可以大大胜过测试集上的超大批量。即使两个模型都经过相同数量的迭代训练并且大批量实现较小的训练损失时,也会发生这种情况。我们的结果证实,随机梯度中的噪声可以增强泛化能力。我们研究最佳学习率时间表如何随着epoch budget的增长而变化,并基于SGD动力学的随机微分方程视角为我们的观察提供理论解释。
成为VIP会员查看完整内容
相关内容
专知会员服务
34+阅读 · 2020年2月27日
Arxiv
8+阅读 · 2018年11月21日

相关VIP内容
专知会员服务
34+阅读 · 2020年2月27日
相关资讯
相关论文
Arxiv
8+阅读 · 2018年11月21日