GAN 为什么需要如此多的噪声?

文 | Conor Lazarou
译 | Mr Bear
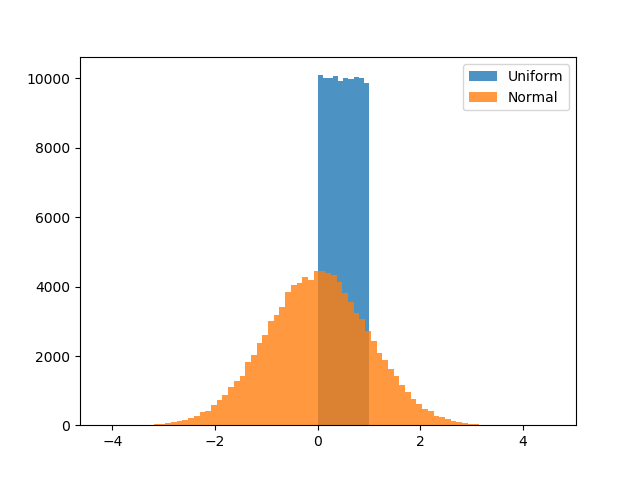
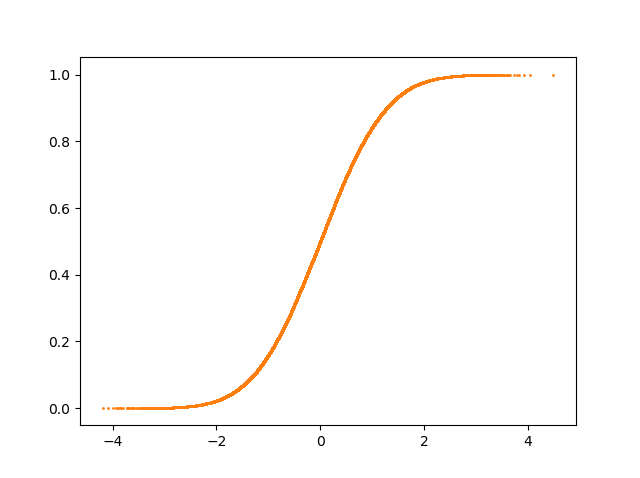
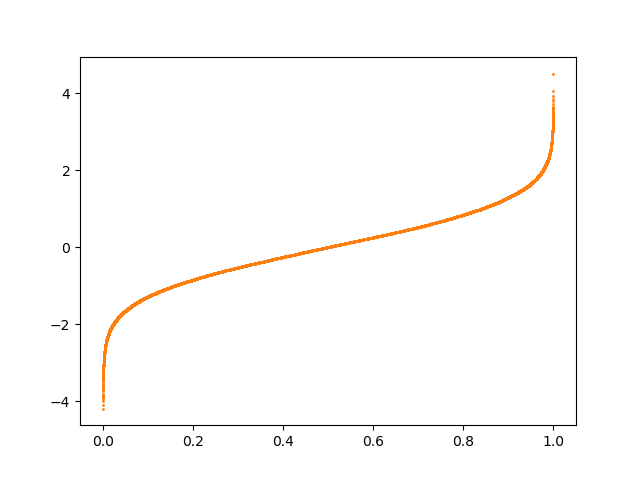
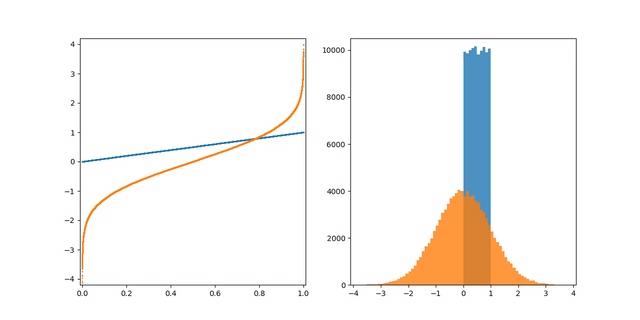
2
这与 GAN 有何关系?

3
二维高斯分布
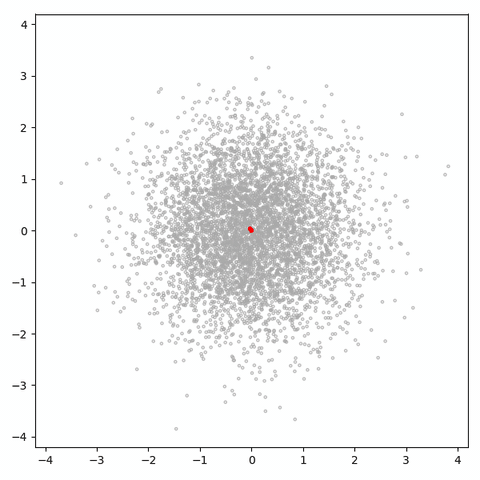 图 6:
一个潜在空间维数为 1 的 GAN 试图学习二维高斯分布。
灰色的点是从真实分布中抽样得到的样本,红色的点是生成的样本。
每一帧都是一个训练步。
图 6:
一个潜在空间维数为 1 的 GAN 试图学习二维高斯分布。
灰色的点是从真实分布中抽样得到的样本,红色的点是生成的样本。
每一帧都是一个训练步。
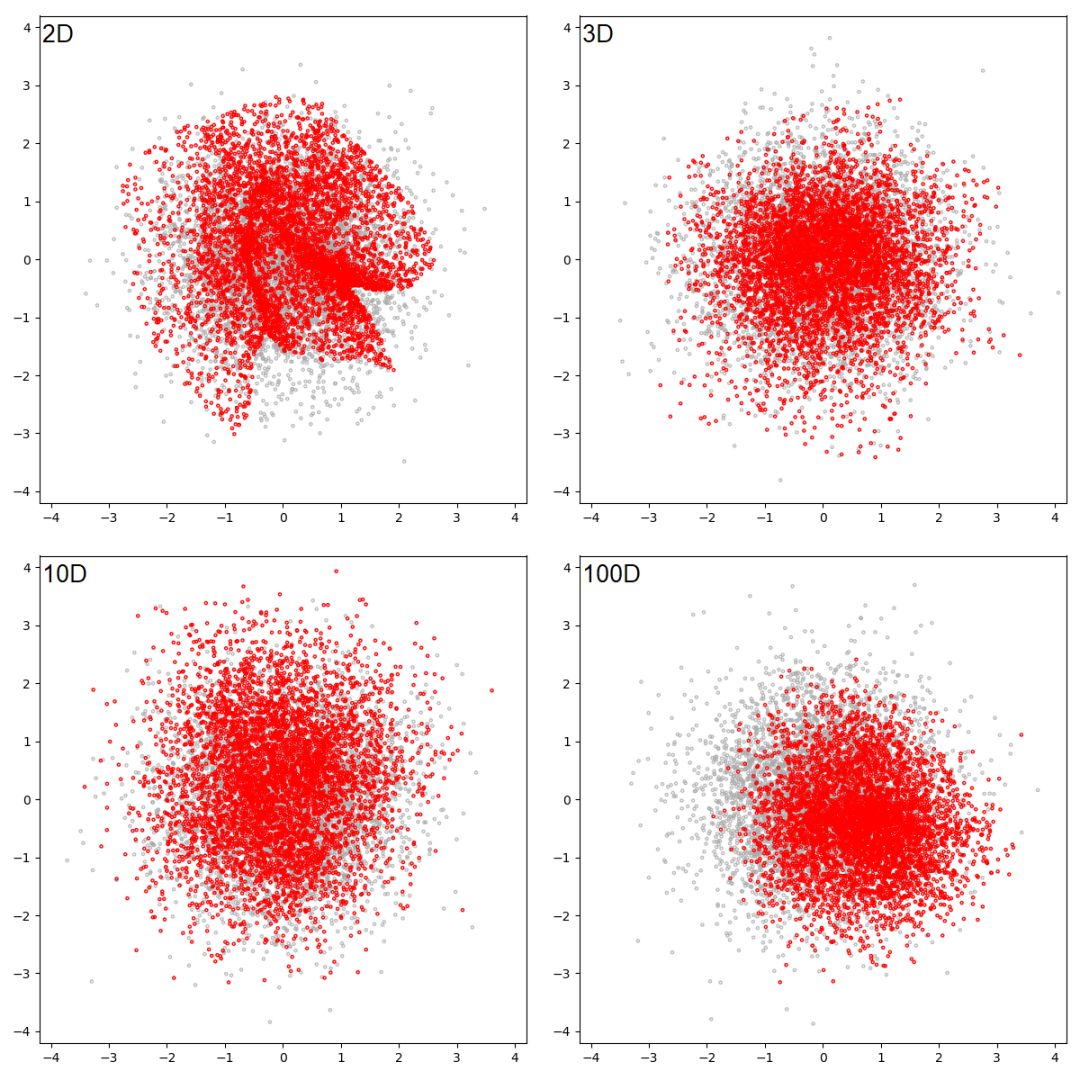
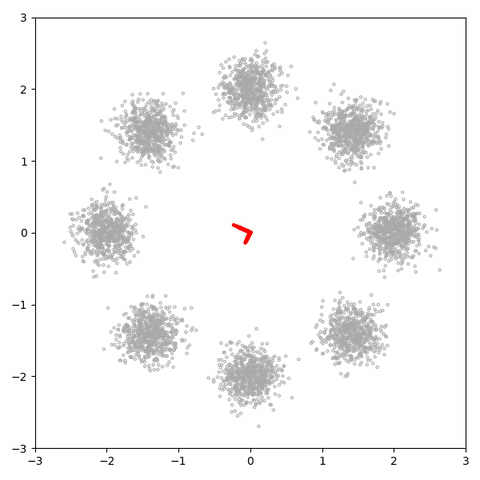 图
10:
潜在维度
为 1 的 GAN 试图学习八个高斯分布。
灰色的点是从真实分布中抽取出来的样本,红色的点代表生成的样本。
每一帧都是一个训练步。
图
10:
潜在维度
为 1 的 GAN 试图学习八个高斯分布。
灰色的点是从真实分布中抽取出来的样本,红色的点代表生成的样本。
每一帧都是一个训练步。
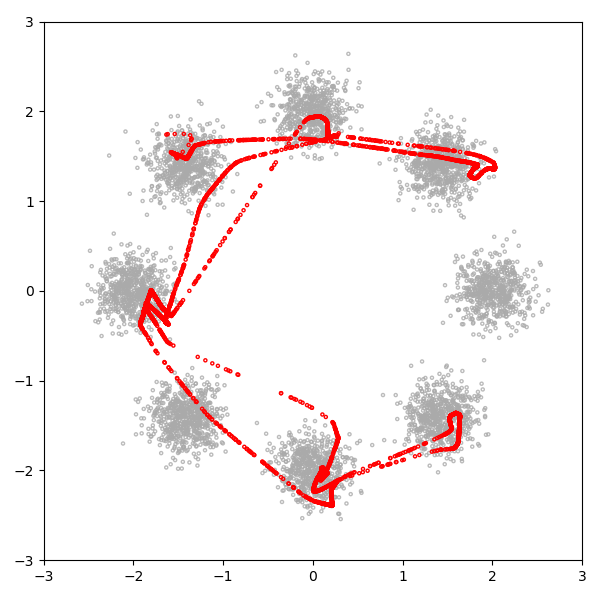
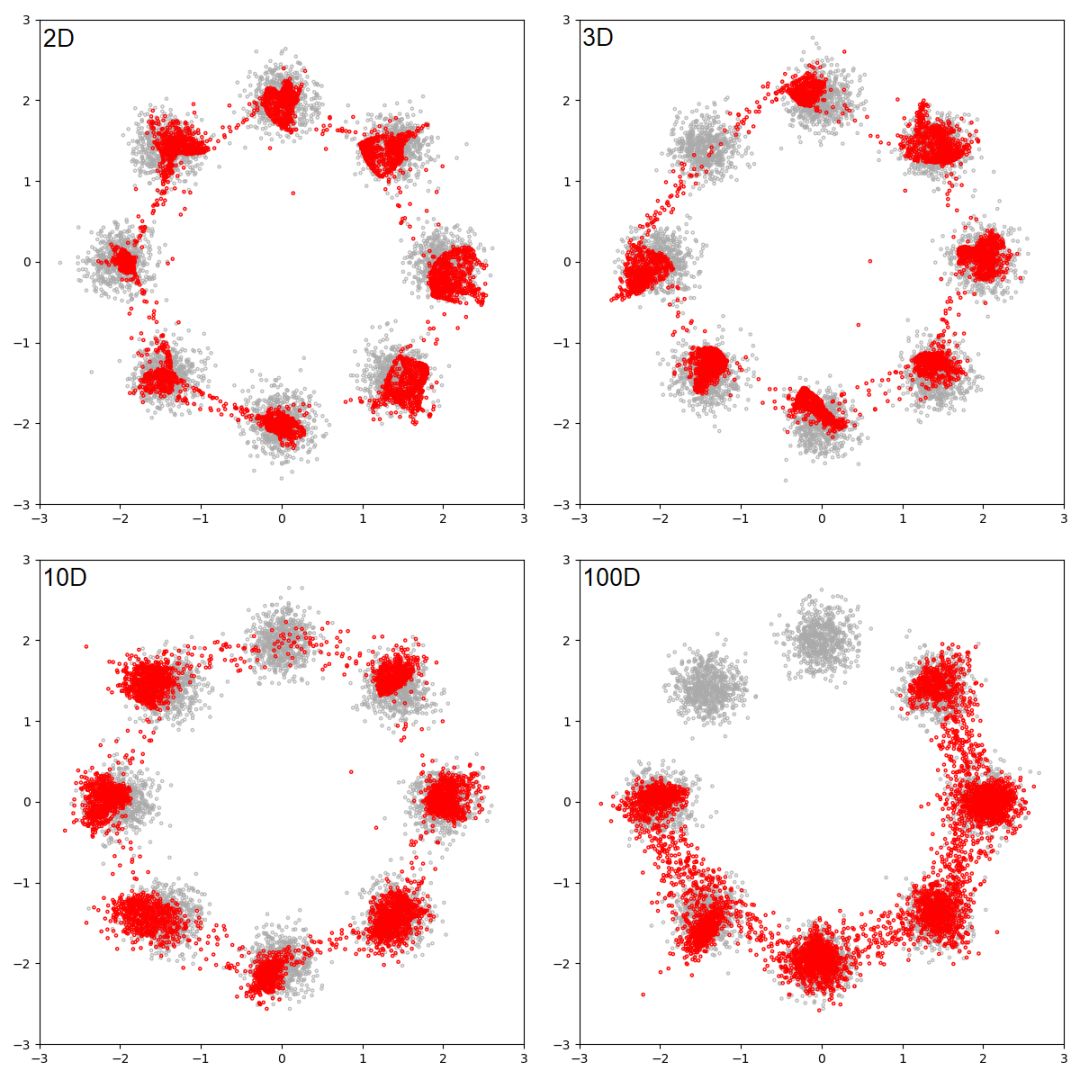
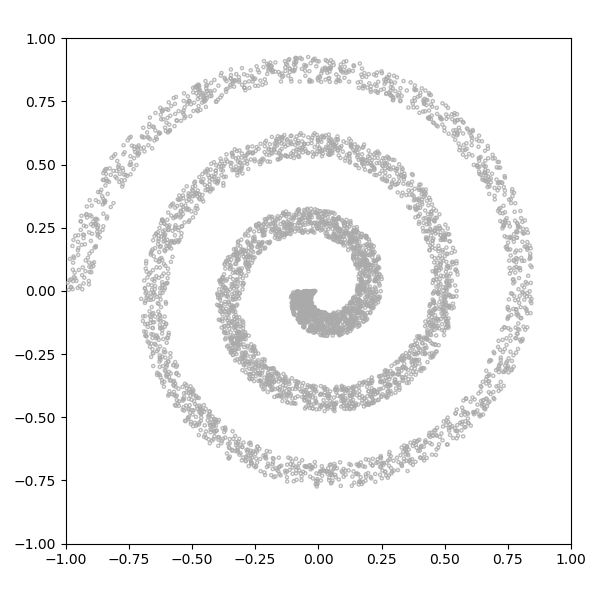
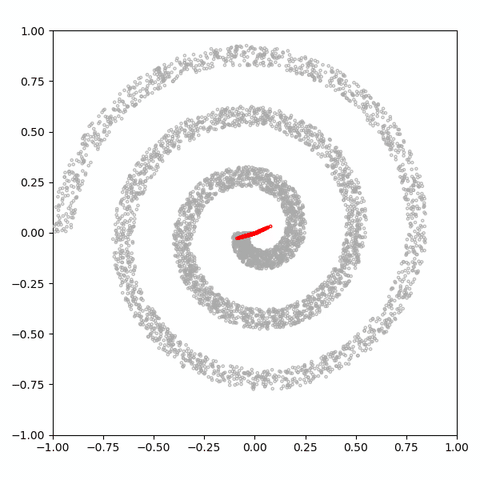 图 14:
潜在维度为 1 的 GAN 试图拟合螺旋分布。
灰色的点是从真实分布中抽取出的样本,红色的点是生成的样本。
每一帧都是一个训练步。
图 14:
潜在维度为 1 的 GAN 试图拟合螺旋分布。
灰色的点是从真实分布中抽取出的样本,红色的点是生成的样本。
每一帧都是一个训练步。
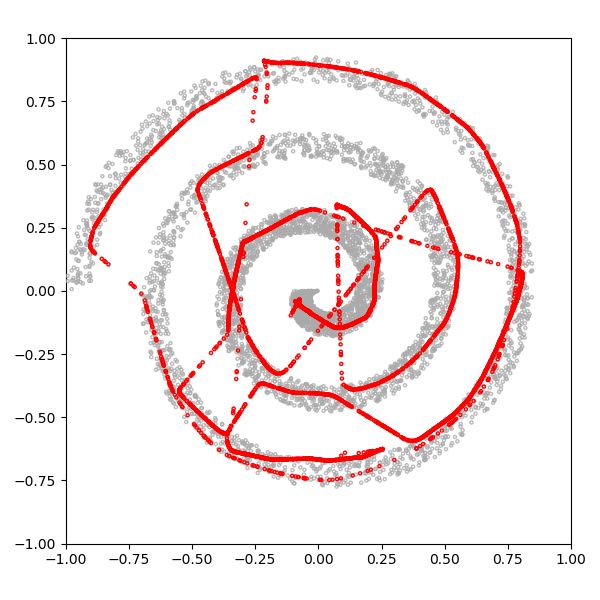
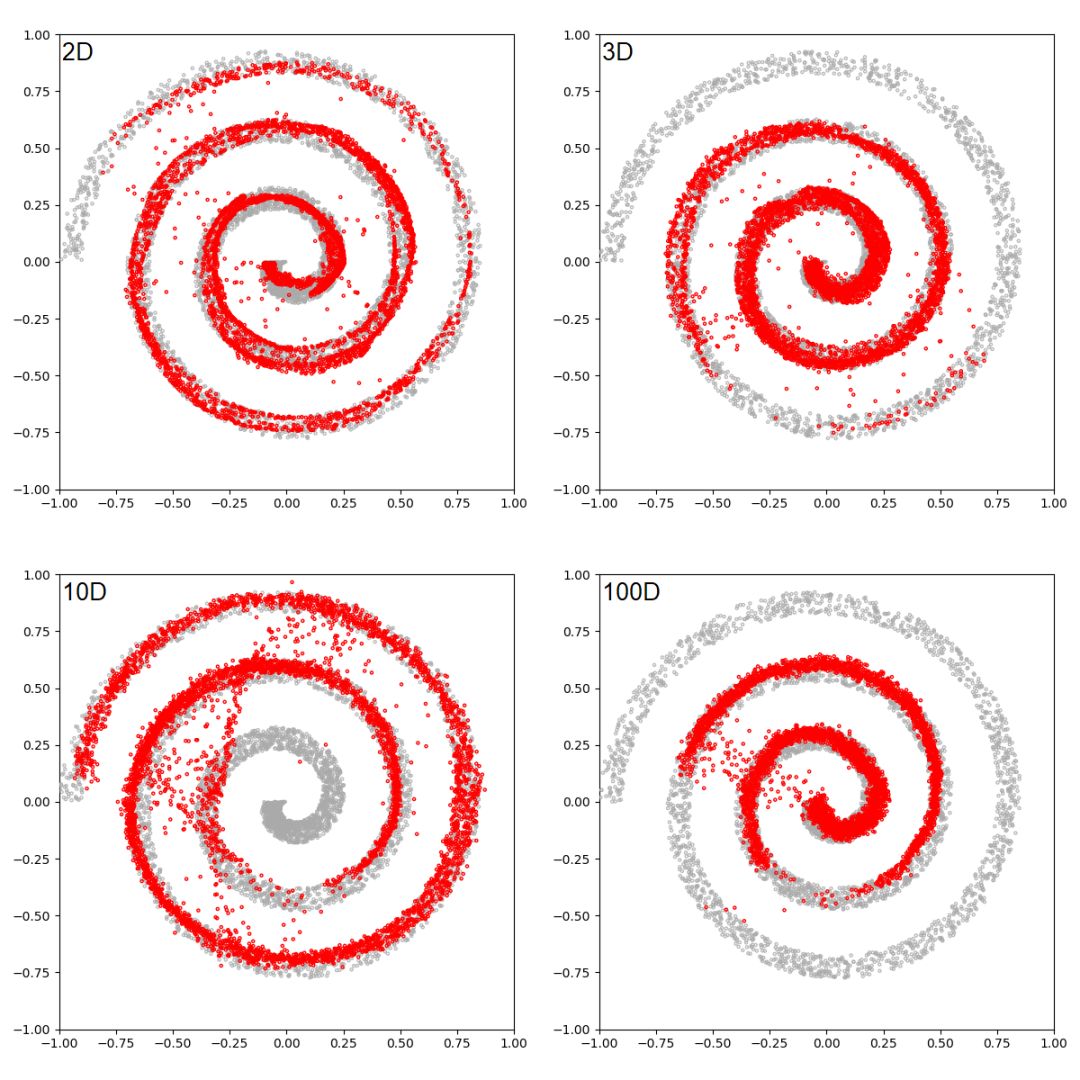

 点击“
阅读原文” 查看 ICLR 系列论文解读
点击“
阅读原文” 查看 ICLR 系列论文解读
登录查看更多
相关内容

Arxiv
5+阅读 · 2018年1月26日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2018年1月26日