如何有效避开鞍点——Michael Jordan 在 BAIR blog 发文

Michael Jordan 教授是机器学习领域神经网络的大牛,发表过很多神经网络方面的学术论文。雷锋网 AI 科技评论整理了公开发表在伯克利博客上的一篇机器学习领域的学术性文章,作者 Chi Jin、Michael Jordan。
原文地址链接:http://bair.berkeley.edu/blog/2017/08/31/saddle-efficiency/
在机器学习领域中,非凸优化中的一个核心问题是鞍点的逃逸问题。最近关于这个方面的研究表明,梯度下降法(GD, Gradient Descent)一般可以渐近地逃离鞍点(详见 Rong Ge 和 Ben Recht 的相关论文),但是还有一个未解决的问题——效率,即梯度下降法是否可以加速逃离鞍点,还是反而速度明显地降低了?逃逸率和环境维度的关系是怎样的?那么,这篇文章将会就涵盖这些问题,描述 Chi Jin 与 Michael Jordan 在与 Rong Ge,Praneeth Netrapalli 以及 Sham Kakade 合作的相关成果。效率方面,他们首次公开了梯度下降法在效率问题上的正面表现;令人惊讶的是,使用合理的扰动参数增强的梯度下降法可有效地逃离鞍点;实际上,rate 和 dimension 上的结果几乎看不出任何鞍点存在的痕迹。
扰动梯度下降
在经典的梯度下降(GD)领域——假设函数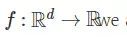
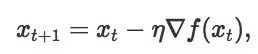
这里 xt 是需优化变量在第 t 步的值,η 是步长。梯度下降法的理论研究在凸优化上已经很充分了,但是在非凸优化情况下就少了很多。我们知道,在非凸情况下,GD 会快速收敛到驻点(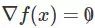
显然,如果驻点是起点,GD 是不可能逃离这个起始点的(就算起始点是局部最大点也一样);因此,为了实现 GD 的作用,我们需要稍稍调整一下 GD,增加一些随机变量。目前已经有了两种方法:
1. 间歇性扰动:Ge/Huang/Jin/Yuan 在 2015 年提出了《Escaping From Saddle Points --- Online Stochastic Gradient for Tensor Decomposition》,增加偶尔的随机扰动,并提供了逃离鞍点的多项式时间保证。(亦见 Rong Ge 的博客);
2. 随机初始化:Lee 等人在 2016 年提出《Gradient Descent Converges to Minimizers》,进使用随机初始化的方法,GD 也可渐近地逃离鞍点(但是实现步骤趋向无穷大)(见 Ben Recht 的博客)。
渐进——甚至多项式时的结果对一般的理论研究来说是重要的,但这两点不能解释基于梯度算法在实际非凸问题中的成功。它们既不能证明 GD 的运行是可靠的——我们发现自己无法处于一种状态中,即学习曲线趋于平缓一段时间(无法定义时间的长度),但是用户无法知道渐近是否已经开始了。它们也不能证明 GD 具有在高维度中的良好性质,这一点在凸优化中是已知的。
解决这个问题的一个合理的办法是考虑二阶算法(Hessian-based)。尽管这些算法一般在一次迭代中的成本远比 GD 高,也比 GD 执行起来更加复杂,但是它们确实提供了可有效地逃离鞍点所需的鞍点的几何信息。因此,文献中出现了对 Hessian-based 的算法合理解释,并且使用这种算法已经取得了切实有效的结果。
GD 是否是高效的呢?或者说,Hessian 对快速逃离鞍点是必不可少的?
如果考虑随机初始化策略,基于第一个问题则出现了一个反面的结果。总的来说,GD 是低效的,尤其在最坏情况下花费幂指数的时间来逃离鞍点(详见后文 “增加扰动的必要性” 部分)。
但是如果我们考虑扰动策略,神奇的是,结果竟大不相同。为了清楚的陈述这个结果,我们使用如下的算法进行分析:

这里,扰动参数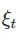
严格鞍点和二阶驻点
在这篇文章中,我们定义鞍点,既包括经典鞍点,也包括局部极大值。它们是沿着至少一个方向在局部最大化的驻点。鞍点和局部极小值可以根据 Hessian 的最小特征值来分类:
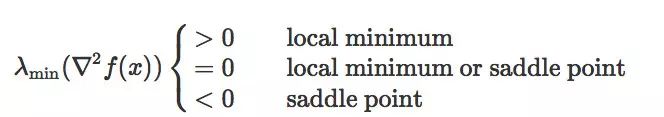
我们将上述情况中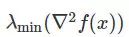
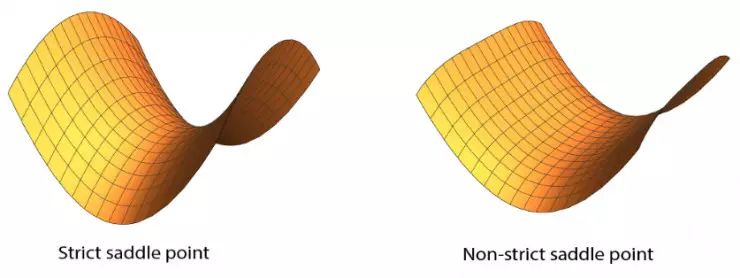
尽管非严格鞍点在谷底可以是平坦的,但是严格鞍点需要在至少一个方向上的曲率严格为负。这样的方向的存在则给基于梯度的算法逃离鞍点的可能性。一般来说,区分局部极小和非严格鞍点是 NP-hard 的;因此,我们,也包括之前这方面的学者们,都会把注意力放在逃离严格鞍点上。
形式上,我们就光滑度提出以下两个标准假设:

传统理论是通过限定迭代次数找到一阶驻点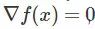
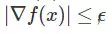
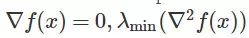

在这个定义中,ρ 是 Hessian Lipschitz 常数。这个定标是根据 Nesterov and Polyak 2016 公约设定的。
应用
在大多数的非凸问题中,已经证实所有的鞍点都是严格鞍点——这些非凸问题包括,但不仅限于 principal components analysis, canonical correlation analysis, orthogonal tensor decomposition, phase retrieval, dictionary learning, matrix sensing, matrix completion 等其他非凸低秩问题。
此外,在所有这些非凸问题中,所有的局部极小值事实上也是全局极小值。因此,在这种情况下,所有寻找 - 二阶驻点的问题立即成为解决这些非凸问题的全局保证。
使用微不足道的开销避开鞍点
在经典的一阶驻点情况下,GD 具有很好的理论性质:
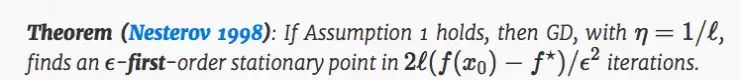
在这个定理中,x0 是初始点,f⋆ 是全局极小值的函数。定理规定任何 gradient-Lipschitz 函数,任何驻点都可以通过 GD 在第 O(1/ϵ2) 次获得,不受 d 的影响,这就是所谓的 “自由尺寸优化”。对一个 GD 的成本计算为 O(d),因此整体的运行时间为 O(d) 的阶。 O(d) 这样线性 scaling 对现代高维非凸问题(比如深度学习)来说是非常重要的。
那么,我们将同样的方法应用到二阶驻点的问题上。我们可以得到什么样的结论呢?我们是否也可以像之前一样实现:
1. 一个无维数的迭代次数;
2. O(1/ϵ2) 的收敛速度;
3. 对 ℓ 和 (f(x0)−f⋆) 的依赖与 Nesterov 1998 中的结果相同;
结果是出人意料的,对这三个问题的答案都是 Yes。

主要定理中,O~(⋅) 只隐藏了对数因子;这边对维度的依赖只有 log4(d).。定理证明,在一个额外增加的 Hessian-Lipschitz 条件下,增加扰动的 GD 收敛到二阶驻点的时间和 GD 收敛到一阶驻点的时间几乎是一样的。因此,我们可以得出结论,PGD 可以无消耗的逃离鞍点。
下面我们讨论一下得出这个结论所必须的几个关键点。
为什么 polylog(d) 的迭代次数是足够的?
我们关于严格鞍点的假设是,在最坏的情况下,逃离鞍点在 d 维度上只能沿着一个方向实现。一般的鞍点逃逸在梯度下降的方向上至少需要 poly(d) 次迭代,那么 polylog(d) 次真的就足够了吗?
举个简单的例子,假设一个函数在鞍点附近是二次的。那么目标函数假定为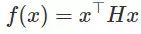
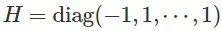
迭代次数的推导是很直接的:
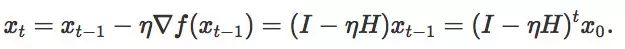
假设我们的起始点是 0,那么增加扰动后,从一个以 0 为圆心半径为 1 的球
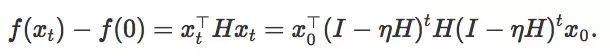
将迭代次数设置为 1/2,λi 将作为 Hessian H 的第 i 个本征值,并将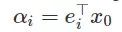
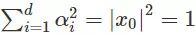
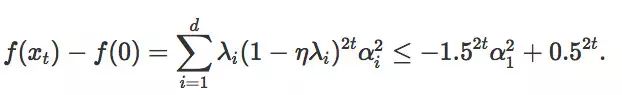
可以得出结论,如果要让函数值减少一定常量,最多进行 O(log d) 次迭代。
一般 Hessian 的饼状限制区域
我们可以得出这样的结论:一个恒定的 Hessian 矩阵的情况下,只有当扰动处 x0 在集合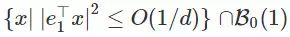
以前的学术分析试图用一个平面集来逼近鞍点附近的动态范围的限制区域。这需要非常小的步长和相应的非常大的运行时间和复杂度。我们的速度则非常快,这取决于一个关键的因素——虽然我们不知道限制区域的形状,但是我们知道,这个限制区域很薄。
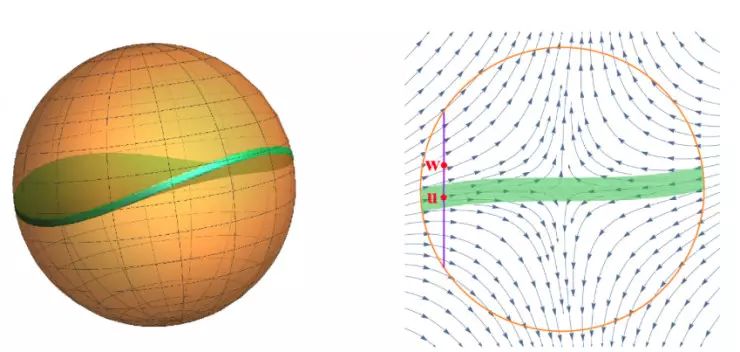
为了量化这个 “薄” 的概念,我们假设两个扰动参数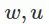
增加扰动的必要性
以上我们已经讨论了两种方法来修改标准的梯度下降算法了,第一种是增加间歇性的扰动,第二种是依靠随机初始化。虽然后者具备渐近收敛性,但是它需要耗费大量的时间和资源,牺牲了有效性;在近期与 Simon Du,Jason Lee, Barnabas Poczos 和 Aarti Singh 的合作中,我们已经展现出,尽管使用非常自然的随机初始化方法和非病理函数,仅仅使用随机初始化的 GD 会因为鞍点大大降低效率,需要非常长的时间才能实现鞍点逃离。而 PGD 的表现却非常不同,它一般可以在多项式的时间内逃离鞍点。
为了更好的解释这个结果,我们使用包括高斯(Gaussians)和均匀分布的超立方体来进行随机初始化,同时我们构建一个光滑的目标函数,满足假设 1 和 2。这个函数被设计成即使随机初始化,在很大概率上 GD 和 PGD 在达到局部极小值之前都需要依次经过 d 范围内的严格鞍点。所有的严格鞍点都只有一个逃逸方向(见下方左图,d=2)
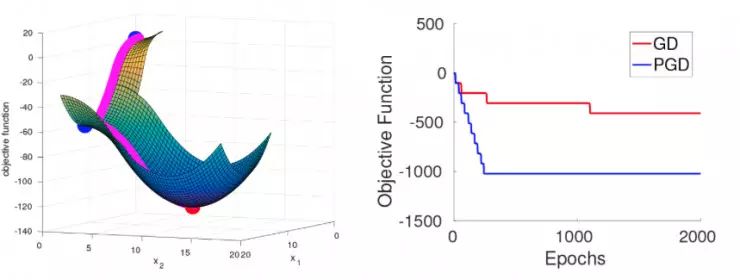
当 GD 在一系列鞍点附近移动时,它会越来越接近后面一个鞍点,因此需要越来越长的时间实现逃逸。逃逸的时间抽象为:逃离第 i 个鞍点的时间为。另一方面,PGD 始终可以在很少的迭代时间内实现逃逸,不管之前的逃逸过程是怎么样的。这个过程在我们的实验中得到了验证,见上方右图,d=10。
结论
在这篇文章中,我们证明了一个扰动形式的梯度下降可以收敛到二阶驻点,其使用的时间与标准的梯度下降收敛到一阶驻点的时间几乎相同。这意味着,在有效地逃离鞍点的问题上,Hessian 信息是不必要的。同时,这还解释了在非凸问题上基本的 GD 和 SGD 表现的出奇的好的原因。这一新的收敛结果可以直接应用于非凸问题,如 matrix sensing/completion 来进行有效地全局收敛。
当然,在非凸优化领域,还存在着许多悬而未决的问题。举几个例子:加入动量会使收敛到一个二阶驻点的速度提高?什么类型的局部极小值可用,并且是否存在一些有用的结构性假设可以让我们有效地应用在局部极小值上,从而避免局部极小值?在非凸优化问题上我们正在缓慢而稳步地取得这进展,在不久的将来,我们可以真正实现 “科学” 的跨越。


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
为什么说随机最速下降法 (SGD) 是一个很好的方法?
▼▼▼



