
主题: On the information bottleneck theory of deep learning
摘要: 深度神经网络的实际成功并没有得到令人满意地解释其行为的理论进展。在这项工作中,我们研究了深度学习的信息瓶颈理论,它提出了三个具体的主张:第一,深度网络经历了两个不同的阶段,分别是初始拟合阶段和随后的压缩阶段;第二,压缩阶段与深网络良好的泛化性能有着因果关系;第三,压缩阶段是由随机梯度下降的类扩散行为引起的。在这里,我们证明这些声明在一般情况下都不成立,而是反映了在确定性网络中计算有限互信息度量的假设。当使用简单的binning进行计算时,我们通过分析结果和模拟的结合证明,在先前工作中观察到的信息平面轨迹主要是所采用的神经非线性的函数:当神经激活进入饱和时,双边饱和非线性如产生压缩相但线性激活函数和单边饱和非线性(如广泛使用的ReLU)实际上没有。此外,我们发现压缩和泛化之间没有明显的因果关系:不压缩的网络仍然能够泛化,反之亦然。接下来,我们表明,压缩阶段,当它存在时,不产生从随机性在训练中,通过证明我们可以复制IB发现使用全批梯度下降,而不是随机梯度下降。最后,我们证明当输入域由任务相关信息和任务无关信息的子集组成时,隐藏表示确实压缩了任务无关信息,尽管输入的总体信息可能随着训练时间单调增加,并且这种压缩与拟合过程同时发生而不是在随后的压缩期间。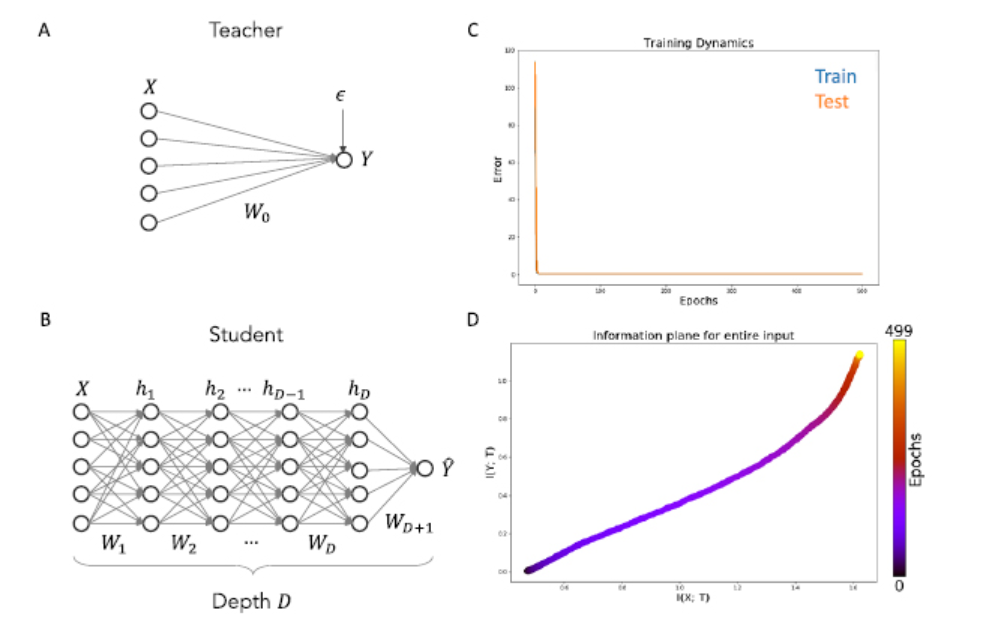


成为VIP会员查看完整内容
相关内容

人工智能(Artificial Intelligence, AI )是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 人工智能是计算机科学的一个分支。
专知会员服务
34+阅读 · 2020年2月27日
专知会员服务
51+阅读 · 2020年2月22日
专知会员服务
148+阅读 · 2019年12月28日
Arxiv
11+阅读 · 2018年7月12日


相关VIP内容
专知会员服务
34+阅读 · 2020年2月27日
专知会员服务
51+阅读 · 2020年2月22日
专知会员服务
148+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
11+阅读 · 2018年7月12日