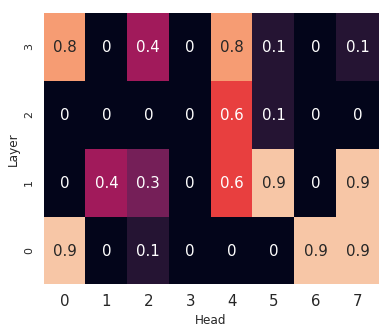
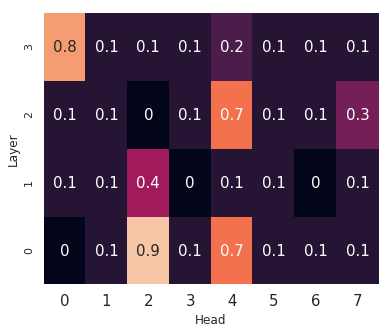
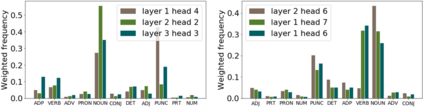
Learning algorithms become more powerful, often at the cost of increased complexity. In response, the demand for algorithms to be transparent is growing. In NLP tasks, attention distributions learned by attention-based deep learning models are used to gain insights in the models' behavior. To which extent is this perspective valid for all NLP tasks? We investigate whether distributions calculated by different attention heads in a transformer architecture can be used to improve transparency in the task of abstractive summarization. To this end, we present both a qualitative and quantitative analysis to investigate the behavior of the attention heads. We show that some attention heads indeed specialize towards syntactically and semantically distinct input. We propose an approach to evaluate to which extent the Transformer model relies on specifically learned attention distributions. We also discuss what this implies for using attention distributions as a means of transparency.
翻译:学习算法变得更加强大, 往往以复杂程度增加为代价。 作为回应, 对算法透明度的需求正在增加。 在 NLP 的任务中, 关注深度学习模型所学到的注意力分布被用于了解模型行为。 在多大程度上这个观点对所有NLP 的任务都有效? 我们调查变压器结构中不同关注负责人所计算的分布是否可用于提高抽象合成任务的透明度。 为此, 我们同时提出质和量两方面的分析, 以调查关注负责人的行为。 我们表明, 某些关注者确实专门致力于合成和语义上截然不同的投入。 我们建议一种方法, 评估变压器模型在多大程度上依赖特定学习的注意力分布。 我们还讨论, 将关注分布作为透明度手段意味着什么。