
题目: The Break-Even Point on Optimization Trajectories of Deep Neural Networks
摘要:
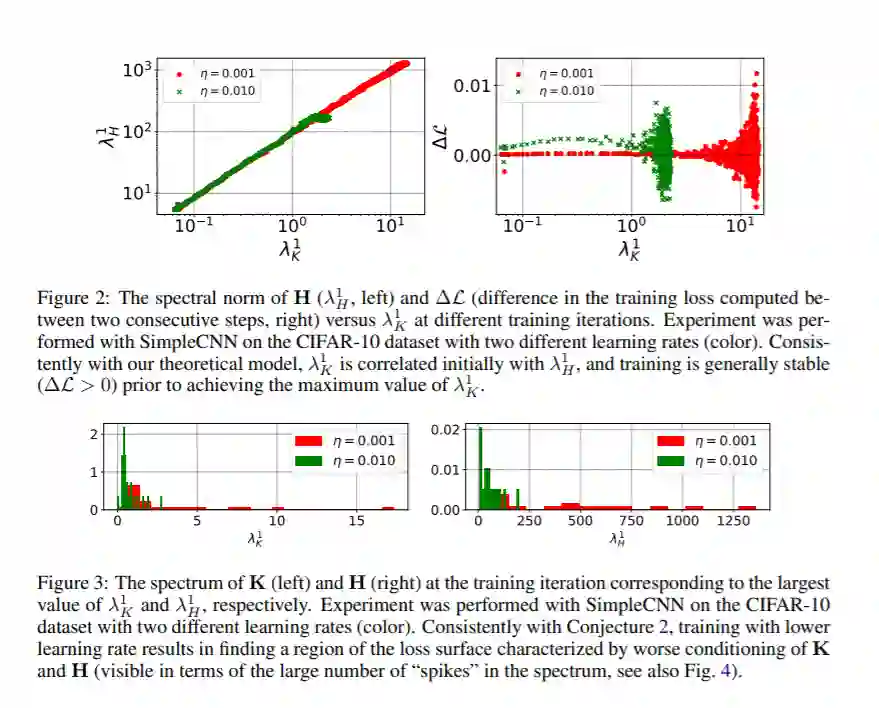
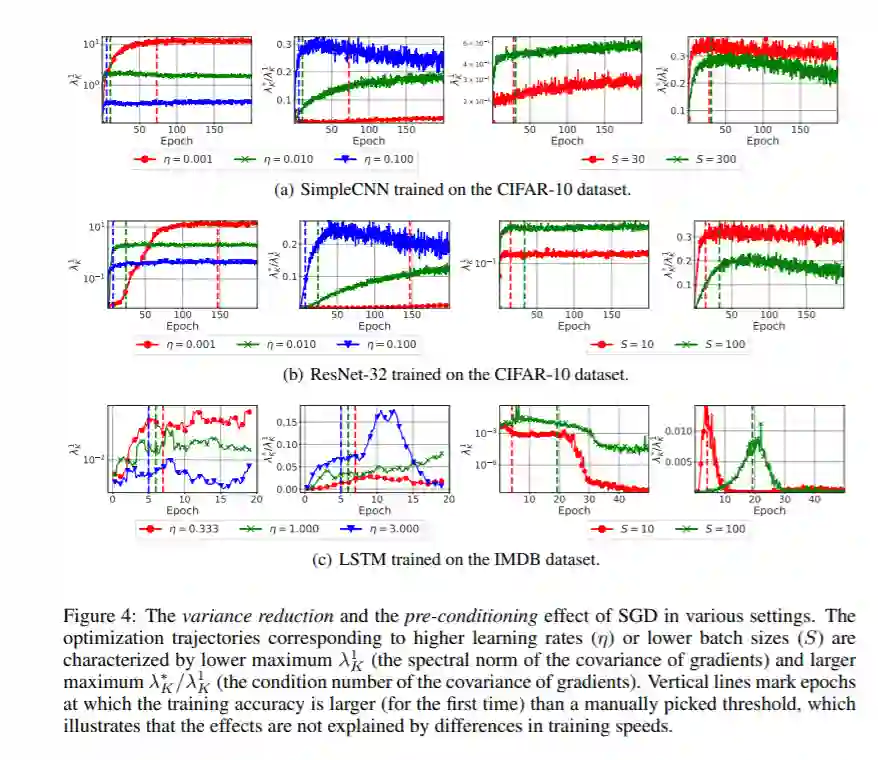
深度神经网络的早期训练对其最终性能至关重要。在这项工作中,我们研究了在训练初期使用的随机梯度下降(SGD)超参数如何影响优化轨迹的其余部分。我们认为在这条轨迹上存在“盈亏平衡点”,超过这个平衡点,损失曲面的曲率和梯度中的噪声将被SGD隐式地正则化。特别是在多个分类任务中,我们证明了在训练的初始阶段使用较大的学习率可以减少梯度的方差,改善梯度的协方差条件。从优化的角度来看,这些效果是有益的,并且在盈亏平衡点之后变得明显。补充之前的工作,我们还表明,使用低的学习率,即使对于具有批处理归一化层的神经网络,也会导致损失曲面的不良适应。简而言之,我们的工作表明,在训练的早期阶段,损失表面的关键属性受到SGD的强烈影响。我们认为,研究确定的效应对泛化的影响是一个有前途的未来研究方向。

成为VIP会员查看完整内容
相关内容

专知会员服务
26+阅读 · 2020年3月26日
专知会员服务
78+阅读 · 2020年3月1日


相关VIP内容
专知会员服务
26+阅读 · 2020年3月26日
专知会员服务
78+阅读 · 2020年3月1日
相关资讯