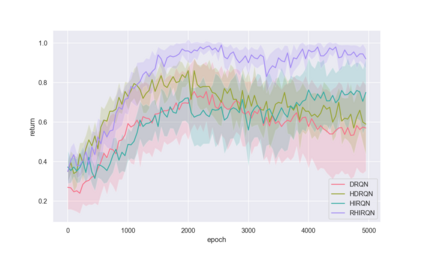
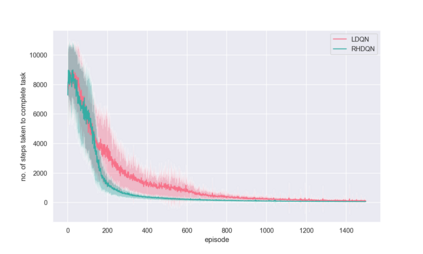
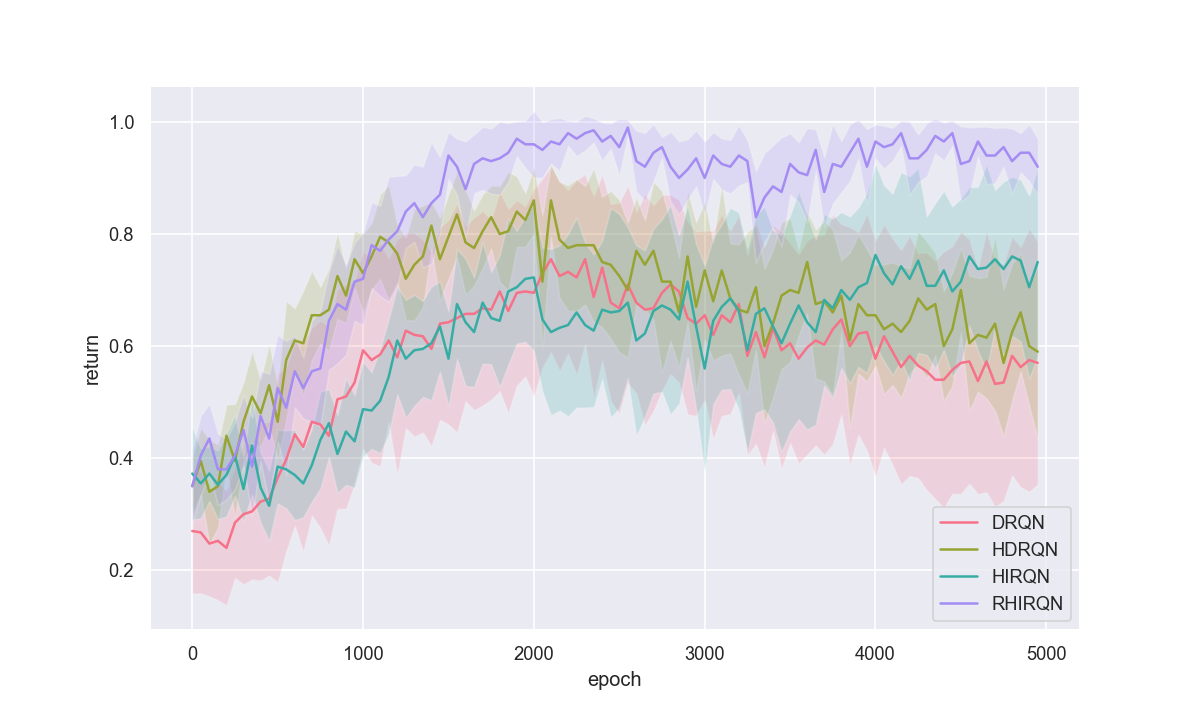
Recent successes of value-based multi-agent deep reinforcement learning employ optimism in value function by carefully controlling learning rate(Omidshafiei et al., 2017) or reducing update prob-ability (Palmer et al., 2018). We introduce a de-centralized quantile estimator: Responsible Implicit Quantile Network (RIQN), while robust to teammate-environment interactions, able to reduce the amount of imposed optimism. Upon benchmarking against related Hysteretic-DQN(HDQN) and Lenient-DQN (LDQN), we findRIQN agents more stable, sample efficient and more likely to converge to the optimal policy.
翻译:最近在基于价值的多试剂深层强化学习方面取得的成功,通过仔细控制学习率(Omidshafiei等人,2017年)或降低更新概率(Palmer等人,2018年),在价值功能方面带来了乐观主义。 我们引入了一个分散的量化估算器:负责任的隐性量子网络(RIQN),同时对团队-环境互动十分活跃,能够减少强加的乐观程度。在对照相关的Hysteric-DQN(HDQN)和Lenient-DQN(LDQN)进行基准测试后,我们发现RIQN代理物更加稳定、高效、更可能与最佳政策趋同。