2020的机器学习在研究什么?请看最新8篇ICML2020投稿论文:自监督学习、联邦学习、图学习、数据隐私、语言模型、终身学习…

1、联邦学习,Distributed Non-Convex Optimization with Sublinear Speedup under Intermittent Client Availability(分布式非凸优化与次线性加速下的间歇客户端可用性)
上海交通大学,University of Texas at Dallas,阿里巴巴
作者:Yikai Yan, Chaoyue Niu, Yucheng Ding, Zhenzhe Zheng, Fan Wu, Guihai Chen, Shaojie Tang, Zhihua Wu
摘要:联邦学习是一种新的分布式机器学习框架,在这个框架中,一群异构的客户机协作地训练一个模型,而不共享训练数据。在这项工作中,我们考虑了联邦学习中一个实际且普遍存在的问题:间歇性客户端可用性,其中合格的客户端集可能在训练过程中发生更改。这种间歇性的客户端可用性模型会严重影响经典的联邦平均算法(简称FedAvg)的性能。我们提出了一个简单的分布式非凸优化算法,称为联邦最新平均(简称FedLaAvg),它利用所有客户端的最新梯度,即使客户端不可用,在每次迭代中共同更新全局模型。我们的理论分析表明,FedLaAvg达到了$O(1/(N^{1/4} T^{1/2}))$的收敛速度,实现了相对于客户总数的次线性加速。我们使用CIFAR-10数据集实现和评估FedLaAvg。评价结果表明,FedLaAvg确实达到了次线性加速,测试精度比FedAvg提高了4.23%。

地址:
https://www.zhuanzhi.ai/paper/409e21c47c63f1847126af70ad874ba8
2、自监督学习,Improving Molecular Design by Stochastic Iterative Target Augmentation(通过随机迭代目标增强改进分子设计)
UC Berkeley ,MIT ,剑桥 University of Cambridge
作者:Kevin Yang, Wengong Jin, Kyle Swanson, Regina Barzilay, Tommi Jaakkola
摘要:在分子设计中,生成模型往往是参数丰富的、需要大量数据的神经模型,因为它们必须创建复杂的结构化对象作为输出。由于缺乏足够的训练数据,从数据中估计这些模型可能具有挑战性。在这篇论文中,我们提出了一种非常有效的自我训练方法来迭代创造额外的分子目标。我们首先用一个简单的属性预测器对生成模型进行预训练。然后使用属性预测器作为似然模型,从生成模型中筛选候选结构。在随机EM迭代过程中,迭代生成和使用目标,以最大限度地提高候选结构被接受的对数似然性。一个简单的拒绝(重权)采样器就足以获得后验样本,因为生成模型在预训练后已经是合理的。我们证明了在无条件和条件分子设计的强基线上有显著的进展。特别是,我们的方法在条件分子设计方面比以前的最先进技术的绝对增益高出10%以上。
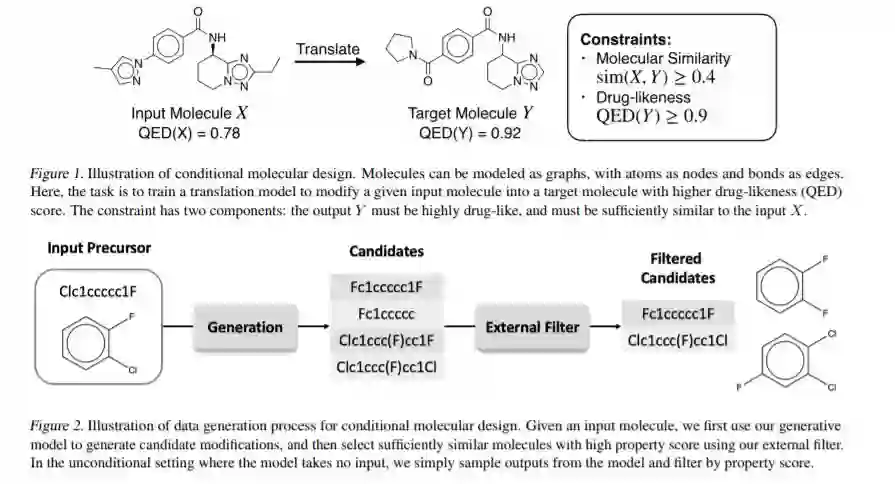
地址:
https://arxiv.org/abs/2002.04720
3、图神经网络,Graph Prolongation Convolutional Networks: Explicitly Multiscale Machine Learning on Graphs, with Applications to Modeling of Biological Systems(图延长卷积网络:在图上显式多尺度机器学习,用于生物系统建模)
University of California Irvine, Irvine, California, USA.
作者:C.B. Scott, Eric Mjolsness
摘要:我们定义了一种新型的集成图卷积网络模型。该集成模型利用优化后的线性投影算子在图的空间尺度之间进行映射,学习对各个尺度的信息进行聚合,从而进行最终的预测。我们计算这些线性投影算子作为一个目标函数的infima,该目标函数与每个GCN使用的结构矩阵相关。利用这些投影,我们的模型(图扩展卷积网络)在微管弯曲粗粒机械化学模拟中预测单体亚单元的势能方面优于其他GCN整体模型。我们通过测量训练每个模型所花费的时间以及壁钟时间来演示这些性能改进。因为我们的模型在多个尺度上学习,所以有可能在每个尺度上按照预定的粗细训练时间表进行训练。我们研究了几个从代数多重网格(AMG)文献改编的这样的调度,并量化了每个调度的计算收益。最后,我们证明了在一定的假设下,我们的图延拓层可以分解成更小的GCN操作的矩阵外积。
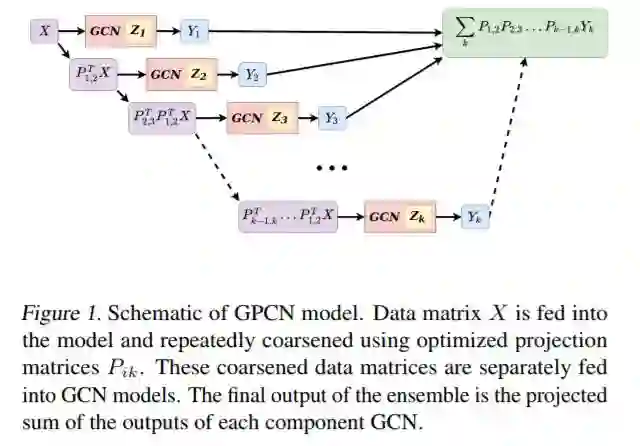
地址:
https://arxiv.org/abs/2002.05842
4、强化学习,Reinforcement Learning Enhanced Quantum-inspired Algorithm for Combinatorial Optimization(强化学习增强的量子启发组合优化算法)
Russian Quantum Center, Moscow, University of Oxford
作者:Dmitrii Beloborodov A. E. Ulanov Jakob N. Foerster Shimon Whiteson A. I. Lvovsky
摘要:量子硬件和量子启发算法在组合优化中越来越受欢迎。然而,这些算法可能需要对每个问题实例进行仔细的超参数调优。我们使用一个强化学习代理与一个量子启发算法来解决能量最小化问题,这相当于最大割问题。代理通过调整其中一个参数来控制算法,其目标是改进最近看到的解决方案。我们提出了一个新的重新排序的奖励(R3)方法,使稳定的单机版本的自我游戏训练,帮助代理人逃脱局部最优。对任意问题实例的训练都可以通过应用对随机生成问题训练的agent的转移学习来加速。我们的方法允许采样高质量的解决方案,以高概率,并优于基线启发和一个黑匣子超参数优化方法。
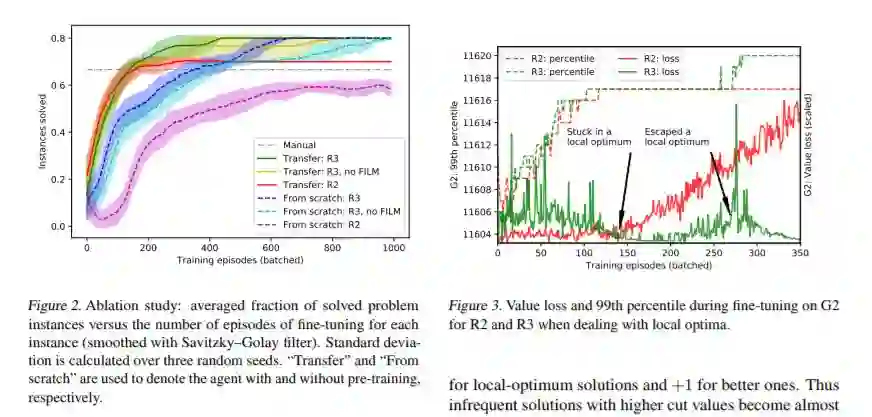
地址:
https://www.zhuanzhi.ai/paper/fb7eef4291247609ac9407e3211cbe1d
5、语言模型,Aligning the Pretraining and Finetuning Objectives of Language Models(对齐语言模型的预训练和微调目标)
微软
作者:Nuo Wang Pierse, Jingwen Lu
摘要:我们证明了在语言模型训练中明确地将训练前的目标与finetuning目标相一致可以显著地提高finetuning任务的性能,并减少所需的finetuning示例的最少数量。从目标对齐中获得的性能裕度允许我们为可用训练数据较少的任务构建更小尺寸的语言模型。我们通过将目标对齐应用于兴趣概念标签和缩略词检测任务,为这些主张提供了经验证据。我们发现,在目标对齐的情况下,我们的768×3和512×3 transformer语言模型在每个任务中仅使用200个finetuning示例进行概念标记和缩略词检测的准确率分别为83.9%/82.5%和73.8%/70.2%,比未经目标对齐预处理的768×3模型的准确率高了+4.8%/+3.4%和+9.9%/+6.3%。我们在数百个训练示例或更少的“少量示例学习”中命名finetuning小语言模型。在实践中,由目标对齐所支持的示例学习很少,这不仅节省了人工标记的成本,而且使在更实时的应用程序中利用语言模型成为可能。
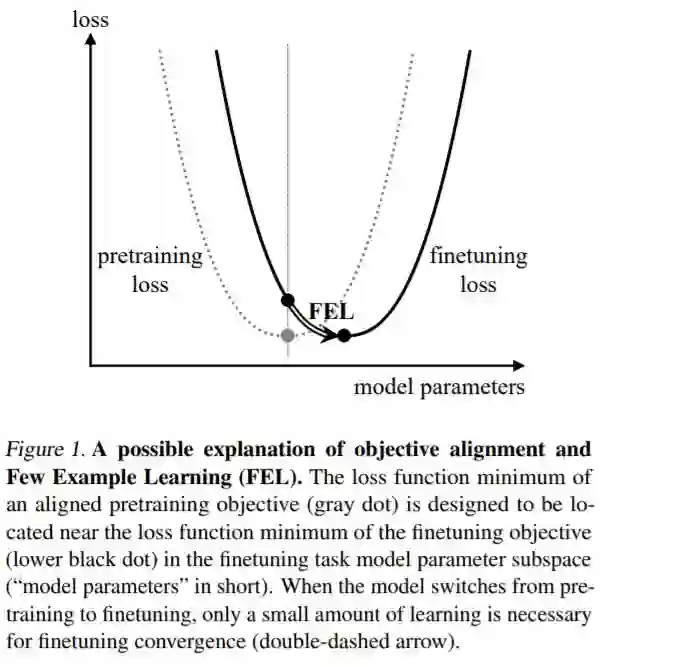
地址:
https://arxiv.org/abs/2002.02000
6、终身学习,Lipschitz Lifelong Reinforcement Learning(Lipschitz终生强化学习)
ISAE-SUPAERO, Universite de Toulouse, France
作者:Erwan Lecarpentier, David Abel, Kavosh Asadi, Yuu Jinnai, Emmanuel Rachelson, Michael L. Littman
摘要:我们研究了agent面临一系列强化学习任务时的知识迁移问题。我们在马尔可夫决策过程之间引入了一个新的度量,并证明了封闭的MDPs具有封闭的最优值函数。形式上,最优值函数是关于任务空间的Lipschitz连续函数。这些理论结果为我们提供了一种终身RL的值转移方法,我们用它来建立一个具有改进收敛速度的PAC-MDP算法。我们在终身RL实验中证明了该方法的优越性。
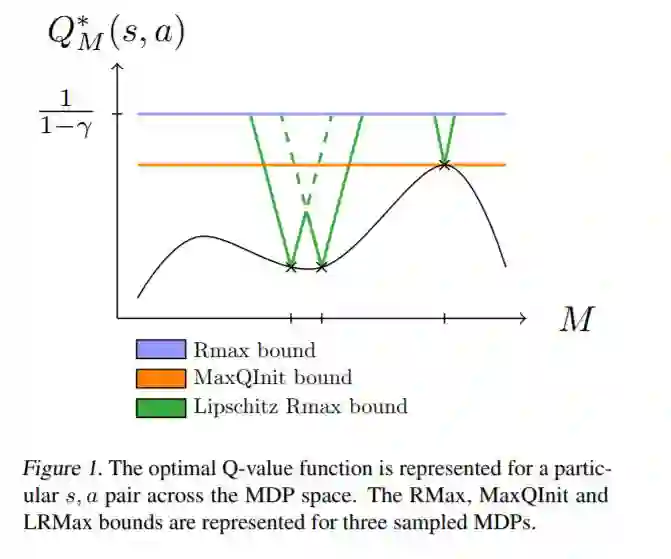
地址:
https://arxiv.org/abs/2001.05411
7、图学习,Deep Coordination Graphs(深度协调图)
University of Oxford
作者:Wendelin Böhmer, Vitaly Kurin, Shimon Whiteson
摘要:我们介绍了多智能体协同强化学习的深度协调图。DCG根据协调图将所有agent的联合价值函数分解为agent对之间的支付,从而在表征能力和泛化之间进行灵活的权衡。通过在图上传递局部消息,可以最大限度地实现该值的最大化,这使得使用Q-learning对值函数进行端到端的训练成为可能。使用深度神经网络对报酬函数进行近似,利用参数共享和低秩近似显著提高样本效率。我们证明了DCG可以解决捕食者-被捕食者的任务,这些任务突出了相对泛化的病态,同时也挑战了星际争霸2的微观管理任务。

地址:
https://arxiv.org/abs/1910.00091
8、数据隐私权,Certified Data Removal from Machine Learning Models(从机器学习模型中移除经过认证的数据)
Cornell University, New York, USA Facebook AI Research
作者:Chuan Guo, Tom Goldstein, Awni Hannun, Laurens van der Maaten
摘要:良好的数据管理需要根据数据所有者的要求删除数据。这就提出了这样一个问题:一个隐式地存储有关其训练数据的信息的训练过的机器学习模型是否应该以及如何受到这种删除请求的影响。有可能从机器学习模型中“删除”数据吗?我们通过定义认证删除来研究这个问题:一个非常有力的理论保证,从其中删除数据的模型不能与从一开始就没有观察到数据的模型区分开来。建立了线性分类器的认证去除机制,并对学习环境进行了实证研究。
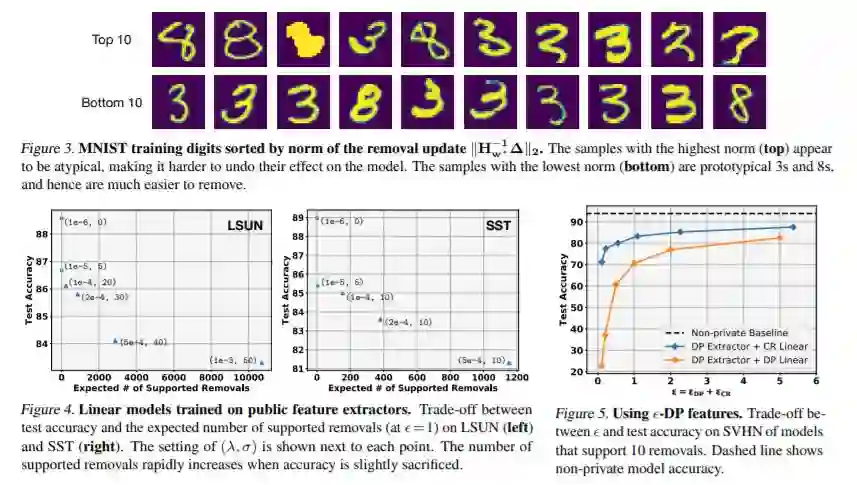
地址:
https://arxiv.org/abs/1911.03030
8篇论文专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ICML20” 就可以获取《最新8篇ICML2020投稿论文:自监督学习、联邦学习、图学习、数据隐私、语言模型、终身学习…》论文专知下载链接





