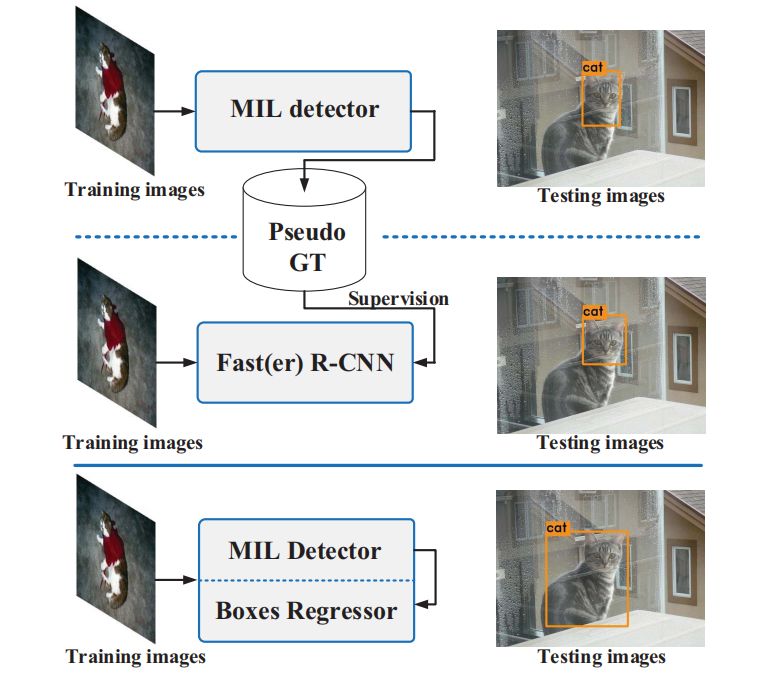
ICCV 2019 | 精确的端到端的弱监督目标检测网络

论文发于:ICCV 2019 论文标题:Towards Precise End-to-end Weakly Supervised Object DetectionNetwork 论文地址:https://arxiv.org/abs/1911.12148
1. 研究背景

2. 相关工作
3. 方法
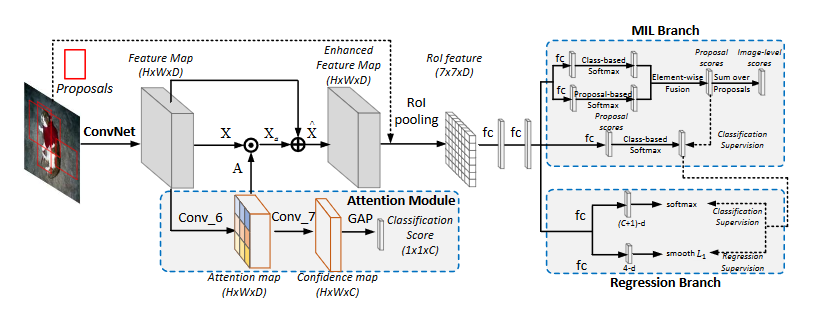
3.1 引导注意力模块
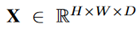 ,注意力模块将其作为输入,然后通过一个1*1卷积层输出一个空间归一化的注意力权重图
,注意力模块将其作为输入,然后通过一个1*1卷积层输出一个空间归一化的注意力权重图
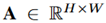 ,然后将注意力权重图和相乘获得
,然后将注意力权重图和相乘获得
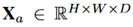 。然后
。然后
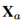 被加到
被加到
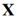 上获得增强后的特征图
上获得增强后的特征图
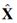 。然后被送入后续模块中。注意力权重图
。然后被送入后续模块中。注意力权重图
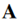 类似于空间归一化以增强相关区域并抑制不相关区域。
类似于空间归一化以增强相关区域并抑制不相关区域。
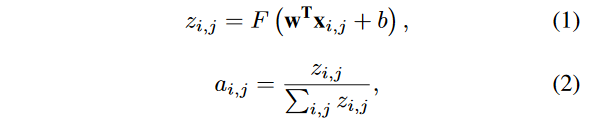
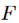 是非线性函数,
是非线性函数,
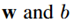 是注意力模块的1*1卷积的参数。增强后的特征图可以用下面的公式计算:
是注意力模块的1*1卷积的参数。增强后的特征图可以用下面的公式计算:
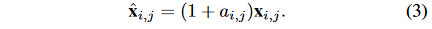
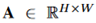 变成
变成
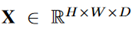 。公式可以重写为:
。公式可以重写为:
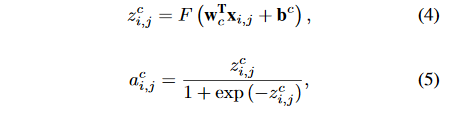
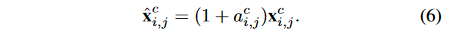
3.2 MIL分支
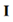 ,其中标签表示为:
,其中标签表示为:
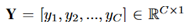 ,
,
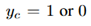 代表类别为c的目标是否出现了。对于输入图像,建议框集合
代表类别为c的目标是否出现了。对于输入图像,建议框集合
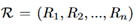 是Selective Search方法产生的。
是Selective Search方法产生的。
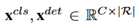 。其中
。其中
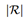 代表建议框的总数,
代表建议框的总数,
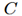 代表图像的类别总数。这两个矩阵通过尺寸不同的soft-max层传递,输出是形状相同的两个矩阵:
代表图像的类别总数。这两个矩阵通过尺寸不同的soft-max层传递,输出是形状相同的两个矩阵:
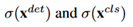 。
。
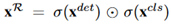 。
。
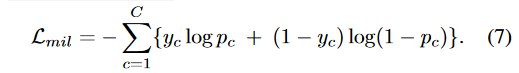
3.3 多任务分支
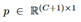 ,总共有
,总共有
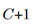 个类别是在全连接后面接soft-max层计算而来。
个类别是在全连接后面接soft-max层计算而来。
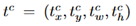 ,这里的c表示某个类别。由于从3.2节介绍的MIL分支获得了实例标注,因此现在每个ROI都有一个GT边界标注框。使用所有标注的ROI进行多任务分类和回归,损失如下:
,这里的c表示某个类别。由于从3.2节介绍的MIL分支获得了实例标注,因此现在每个ROI都有一个GT边界标注框。使用所有标注的ROI进行多任务分类和回归,损失如下:
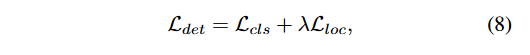
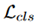 分类损失,
分类损失,
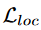 是回归损失。
是回归损失。
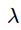 控制两个损失的平衡,对于
控制两个损失的平衡,对于
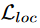 ,使用Smooth L1损失,对于
,使用Smooth L1损失,对于
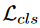 ,因为伪标注信息带有噪声,所以我们为每一个ROI增加一个权重系数,公式如下:
,因为伪标注信息带有噪声,所以我们为每一个ROI增加一个权重系数,公式如下:
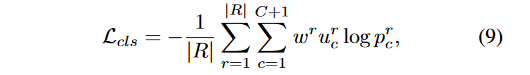
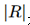 是建议框的个数,权重
是建议框的个数,权重
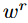 是精细化分类器时使用特定方式计算的。因此整个网络的损失函数可以用下式表示:
是精细化分类器时使用特定方式计算的。因此整个网络的损失函数可以用下式表示:
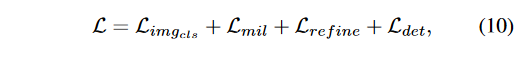
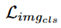 是GAM的多标签分类损失,
是GAM的多标签分类损失,
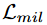 是WSDDN的多标签分类损失,
是WSDDN的多标签分类损失,
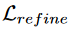 是精细化分类器的损失,
是精细化分类器的损失,
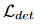 是检测分支的损失。
是检测分支的损失。
4. 实验


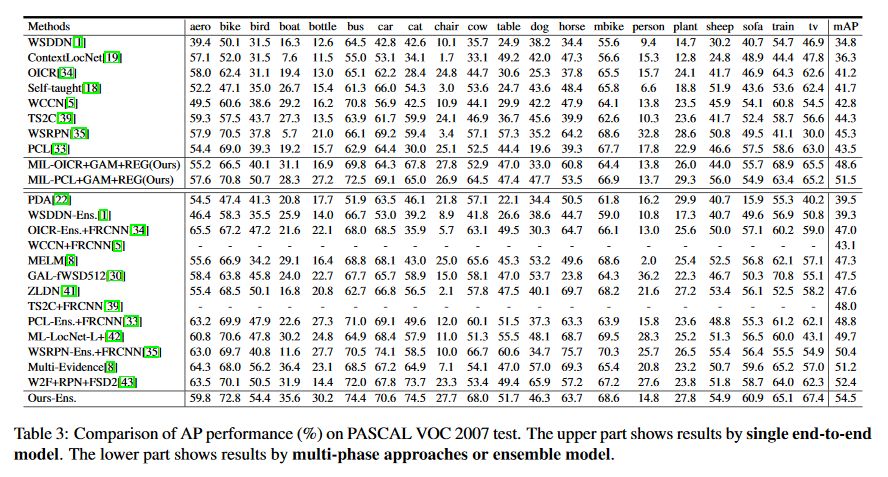
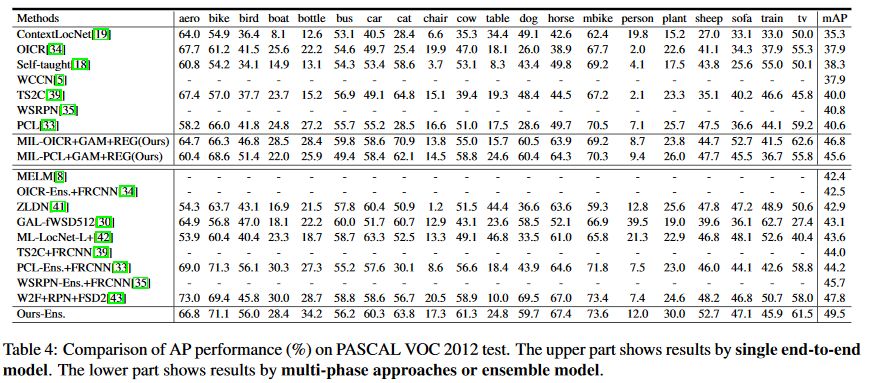
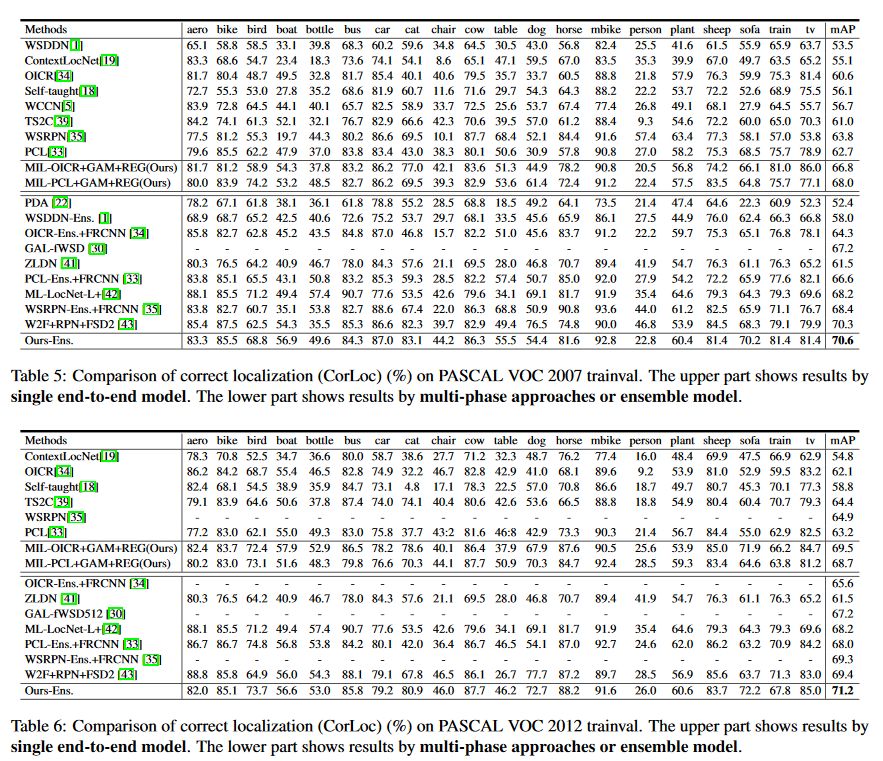

5. 对比和结论


 点击“
阅读
原文
”查看
用于语音识别的数据增强
点击“
阅读
原文
”查看
用于语音识别的数据增强
登录查看更多
相关内容
专知会员服务
39+阅读 · 2020年3月19日




相关VIP内容
专知会员服务
39+阅读 · 2020年3月19日
相关资讯