淘宝 at KDD 2020,提出M2GRL优化大规模推荐中的多任务多视角图表示学习

导读:今天分享一下阿里淘宝在KDD 2020的一篇关于超大规模推荐中的多任务多视图图表示学习优化工作,首次将多视图表示对齐应用在工业界超大规模推荐系统中,推荐一读。

论文:M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems
地址:https://arxiv.org/abs/2005.10110
摘要
将图表示学习与多视图数据(附加信息)相结合进行推荐是行业发展的趋势。现有的方法大多可以归类为多视图表示融合:他们首先构建一个图,然后将多视图数据集成到图中每个节点的一个紧凑表示中。然而,这些方法在工程和算法方面会带来一些问题:
多视图数据在工业界是丰富的,信息量大,可能超过单个向量节点的容量;
由于多视图数据往往来自不同的分布,可能会引入归纳偏差。
在本文中,我们使用一种多视图表示对齐方法来解决这个问题。特别地,我们提出了一个多任务多视图图表示学习框架(M2GRL)来学习大规模推荐系统的多视图图的节点表示。M2GRL为每个单视图数据构造一个图,从多个图中学习多个单独的表示,并对跨视图关系进行对齐。M2GRL选择多任务学习范式,共同学习视图内表示和跨视图关系。此外,M2GRL利用同方差不确定性自适应调整训练任务的权重损失。我们在淘宝上部署了M2GRL,并在570亿个例子上训练它。根据离线指标和在线A/B测试,M2GRL的效果显著优于当前SOTA的算法。淘宝多样性推荐的进一步探索表明了利用M2GRL所产生的多种表示的有效性,本文认为这对于不同侧重点的行业推荐任务是一个很有前景的方向。
背景
近年来基于图的推荐算法在学术界通过学习图数据的结构信息显著提升了预测效果,但是在工业界仍然有很多的挑战去构建一个可扩展的图算法来超过其他工业界算法。其中一个比较重要的问题是如何将附加信息side information引入到图表示学习中,譬如item价格、用户画像等。本文中使用“多视图数据”来代替“side information”的说法,是因为认为这在工业界是一种更通用更合理的叫法,也同时包含user-item交互数据。
当前图表示学习中主要有两种方式来利用多视图数据:一种是将多视图数据当做item的属性喂给基于图算法的输入;另一种是使用多视图数据构造异构图然后使用图表示学习算法譬如metapath2vec等学习item embedding。这两种方式都可以归类为多视图表示融合,也就是将多视图数据集成到图中每个节点的一个紧凑表示中。但是这种方式会存在明显的局限性,如下图所示,根据用户行为序列可以构造三个单视图的图,shop-view、item-view以及category-view,他们三个都有各自的结构以及独有信息是被多视图表示融合方法所忽略的。
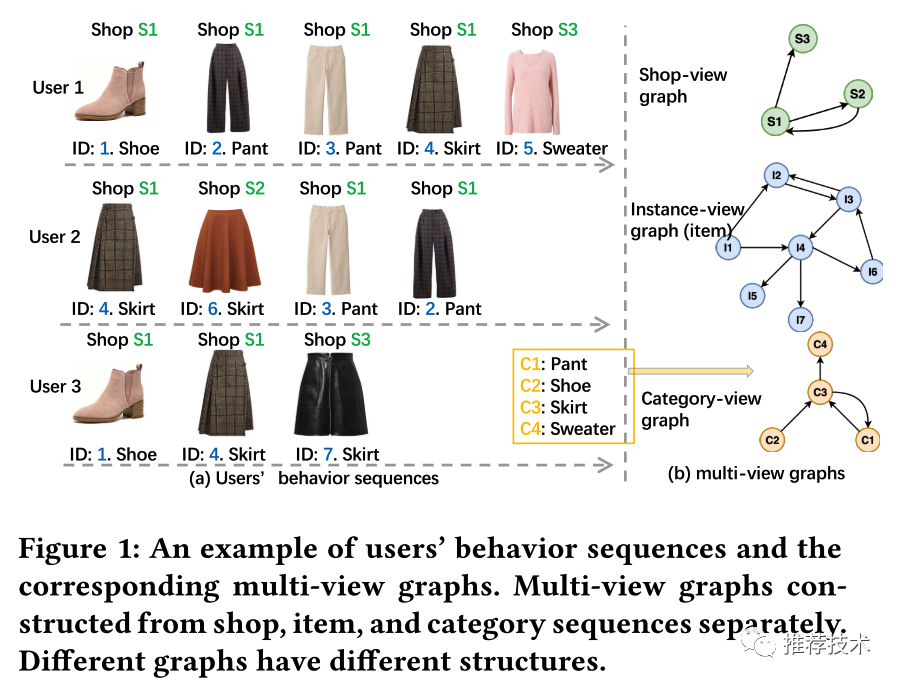
因此,本文提出了一个多任务多视图图表示学习框架(M2GRL)来学习大规模推荐系统的多视图图的节点表示。M2GRL包含两种类型的任务:视图内任务和视图间任务。视图内任务学习单个视图内的节点表示,视图间任务则针对不同视图的图关系进行建模。本文的主要贡献点:
提出一种全新的针对多视图数据的图表示学习框架M2GRL,首次将多视图表示对齐应用在工业界超大规模推荐系统中;
M2GRL是可扩展的,支持不限数量的视图、并且可以分布式处理数以十亿的样本数据;
离线与线上A/B实验验证了M2GRL达到了SOTA效果,并且在淘宝场景的多样性实验也验证了M2GRL学习到的多视图表示的有效性;
问题定义
本文的任务是在电商场景中如何学习高质量的item表示。根据item特征的分类,我们为item生成多种表示。具体来说,本文中使用了三种视图的数据:user-item互动数据视图;item分类数据视图;item所属shop数据视图。
图的构建:根据用户行为序列,首先分别为上述三种视图构造三个图(item图、分类图以及shop图)。以item图为例,如果在一个用户的行为序列中的两个item是相邻的,我们便认为两个item是相连的。分类图和shop图也是类似的构建思路。
节点序列采样:用于生成训练样本节点序列常见的方法是随机游走以及相应的变种。本文通过从用户行为序列中抽取session来生成训练样本,主要的步骤:
数据清理。我们注意到用户有的时候会点击一个item,然后迅速回退到前一个页面也就是说用户对之前点击的item并不感兴趣。因此我们将停留时间不超过2s的item进行移除;
Session的分拆与合并。有的时候用户的session可能长达几个小时(后台运行),我们通过记录用户打开和退出淘宝APP的时间对于空闲间隔时间超过一小时的session进行分拆,并且对于空闲间隔时间在30分钟内的session进行合并。
M2GRL总体框架
M2GRL包含两种类型的任务:视图内任务和视图间任务。视图内任务学习单个视图内的节点表示,视图间任务则针对不同视图的图关系进行建模。
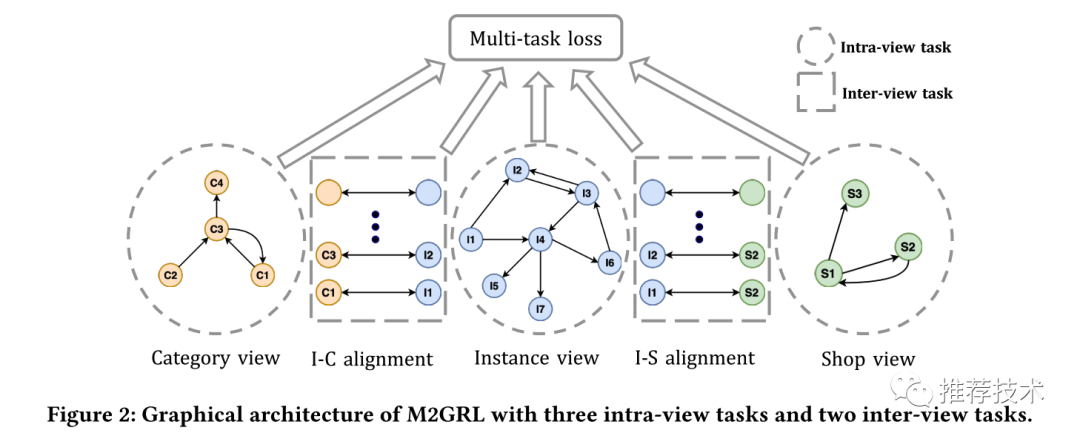
Intra-view表示学习
Intra-view任务可以认为是在同构图上的表示学习问题。相对来说,intra-view任务是条件独立的所以可以在不做太多改动的前提下应用最新的图表示学习方法。本文采用一种简单而有效的模型来学习节点embedding表示:负采样的skip-gram模型(SGNS)。首先采用上一节中提到的节点序列采样方式生成节点序列;然后应用Skip-gram模型来得到节点embedding表示。
Inter-view对齐
Inter-view任务的目标是对跨视图的关系进行建模,譬如instance-category(I-C对齐)、instance-shop(I-S对齐)。也就是说,如果item i拥有x的属性,那么我们定义在item i和x之间有一个跨视图的关系i - x。我们首先将两种不同类型的embedding通过一个变换矩阵W_ic映射到一个关系空间中,然后就可以得到一个inter-view任务的损失函数表示如下所示:
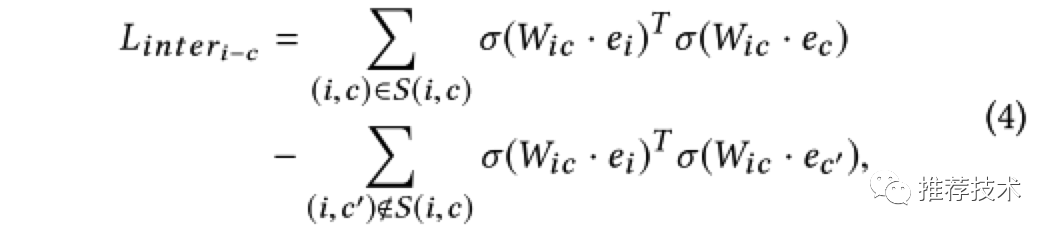
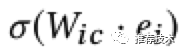
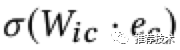
同方差不确定性
M2GRL框架关心的是如何在多个相关联的任务中学习到一个全局最优解。计算最终损失的一种简单而流行的方式是将多个任务的损失进行一个线性加权,如下图所示:
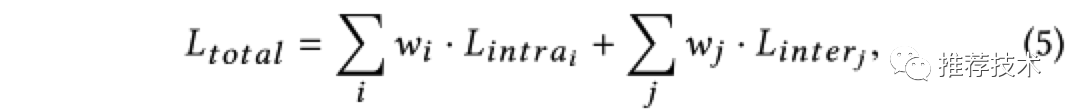
本文中引入同方差不确定性的思想[2]来解决多个任务损失函数的权重设置问题。我们通过最大化高斯似然任务相关的不确定性来推导出多任务的最终损失函数形式。首先定义多个任务的最终损失函数如下所示,其中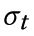
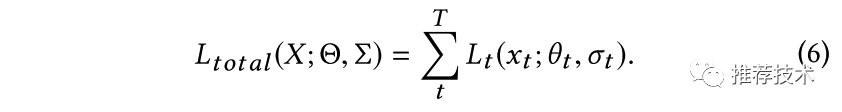
同时,定义多任务模型的最大似然函数为一个softmax函数形式:
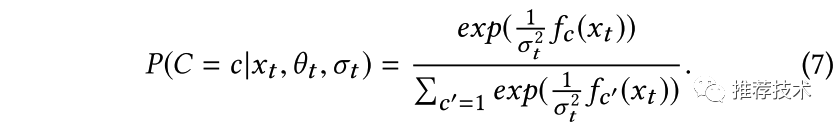
通过如下的公式推导,可以得到包含不确定性参数的损失函数的表示形式如下图(10)所示。可以看到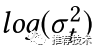
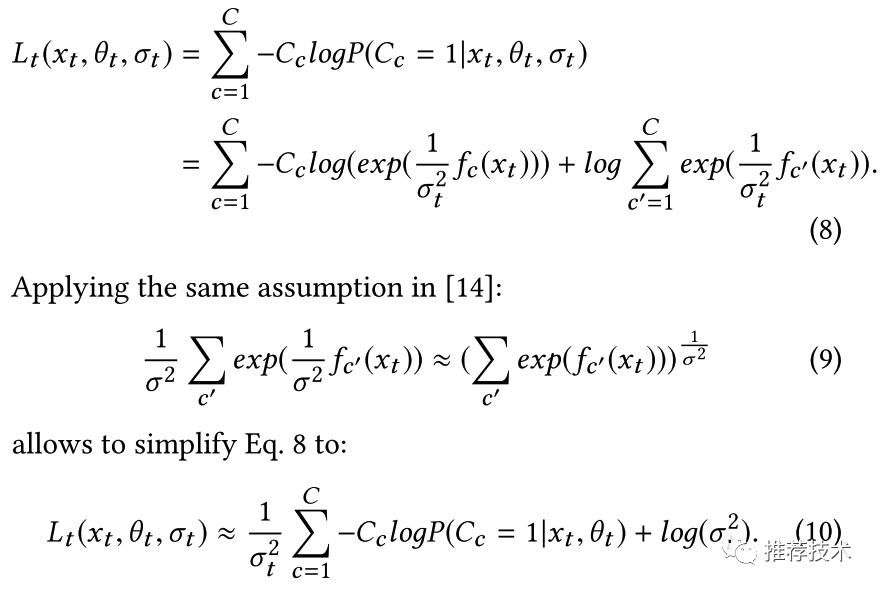
系统部署
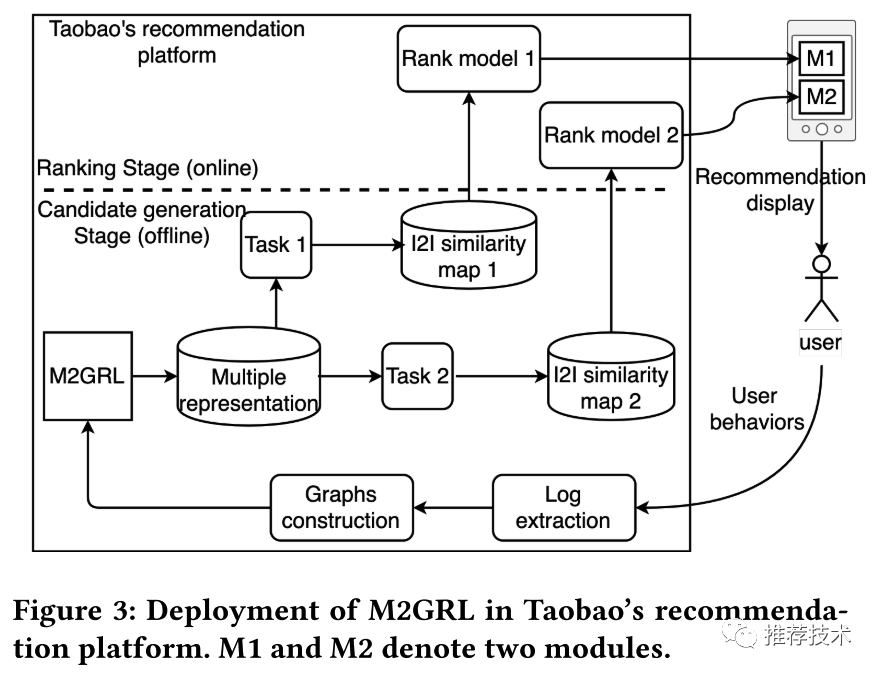
M2GRL框架在淘宝推荐平台的系统部署如下图所示,在召回阶段,首先产生多种单视图的图;然后M2GRL分布式并行地产生多种表示;然后将多种表示传递给下游召回策略返回候选集;最后通过排序模型选择最终展示给用户的候选集。
实验结果
离线实验
离线实验部分选取了两个数据集来评估效果。一个是收集淘宝App用户历史行为中三天内最热门的1000万item数据;另一个则是公开数据集Movielens 20M。对于前者数据集,本文按照前面章节描述的构建三个视图数据;对于后者公开数据集,将电影的tag当做相应的分类构建视图数据,由于没有shop相关信息视图所以后者只有两个视图。下面是和各种baseline相应的实验结果对比。
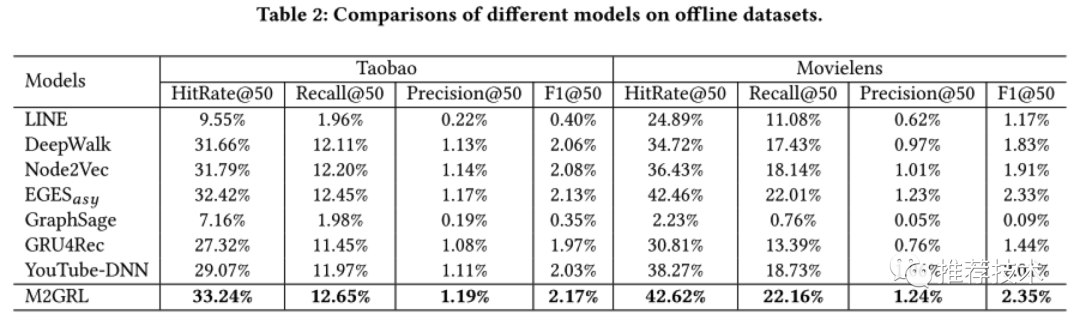
通过上述实验数据对比,我们可以得到:
EGES是最好的baseline,由于引入了额外的side information可以缓解稀疏问题,效果好于Node2Vec/ DeepWalk以及Line;
Node2Vec和DeepWalk的效果好于Line,因为Line只保存两跳的邻居节点信息;另外由于Node2Vec使用加权的随机游走策略因此在两个数据集上的表现都好于DeepWalk;
我们发现GraphSage的表现最差。一个主要的原因是item图是基于用户行为序列构建的,稠密而且噪音大;
GRU4Rec和Youtube-DNN方法都是基于序列的推荐方法,效果都差于基于随机游走的图方法;
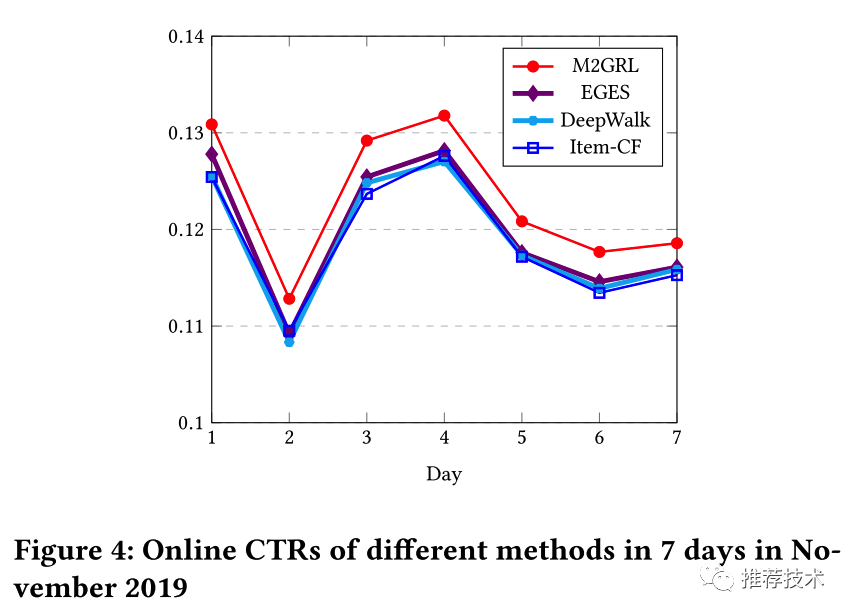
在线A/B实验
本文针对工业界主流算法譬如EGES、Item-CF和DeepWalk、以及M2GRL进行了在线的A/B实验对比。训练过程中采用包含1.5亿个item、总共570亿的样本数据进行训练。A/B实验结果如下图所示,平均来说M2GRL可以获得5.76%的明显提升。
参考
1. M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems
2. What uncertainties do we need in bayesian deep learning for computer vision?
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇

