Google at KDD 2020,提出MoSE框架显式建模用户行为序列提升多任务学习效果

导读:今天分享一下Google在KDD 2020的一篇关于多目标优化的工作,在MMoE[2]多任务框架基础上引入LSTM显式建模用户行为序列提升多任务学习效果,推荐一读。

论文:Multitask Mixture of Sequential Experts for User Activity Streams
地址:https://research.google/pubs/pub49274/
摘要
工业级大规模推荐系统应用中经常需要同时优化多个目标,譬如用户满意度与参与度,因此多任务学习应运而生。然而,当前推荐系统中大多数的多任务学习模型架构只考虑了非序列化的特征输入(譬如query与context),没有特别考虑用户行为序列的建模。显式地针对用户行为序列的建模会帮助多任务模型引入时序依赖,从而更准确的预测用户将来的行为。另外,用户行为序列可能会包含多种异构的数据源,譬如搜索日志、浏览日志等,由于不同类型的数据稀疏性等方面的特性会有较大区别,因此在一起建模学习时也需要谨慎处理。
本文主要研究了如何在多任务学习场景中针对用户行为序列进行建模,提出了一套新颖的模型框架MoSE(Mixture of Sequential Experts)。在当前最新的MMoE多任务学习框架中使用LSTM针对用户行为序列进行显式建模。同时,本文也通过离线实验以及GMail的线上实验证明了本文的有效性。
背景
多任务学习在多个任务之间紧密关联时是有明显效果的。首先,它允许知识和数据在多个相关任务之间的迁移共享从而提升效果;其次,多任务学习通过引入推导偏差可以扮演正则项的角色,因此辅助任务可以用来提升主任务的泛化能力。
本文研究了多任务学习中针对用户行为序列数据进行建模的挑战:
数据稀疏性。用户行为可能是高度稀疏的,譬如购买行为相对于浏览行为来说就非常稀疏;
数据异构性。用户行为数据包含了多种来源或者类型的数据,譬如用户画像包含了性别信息,同时用户日志则包含了点击信息等;从这样的异构数据中学习共享的表示会由于内在的冲突从而比较困难;
复杂的多目标。多个目标之间时序上的联系,譬如点击和购买目标之间,可能会因为用户复杂的内在意图而变得更加复杂;
因此,本文提出了MoSE模型结构用来解决上述的挑战,主要是由当前MMoE多任务学习模型和LSTM的创新性结合。本文通过丰富的离线实验和GMail的实际线上实验验证了MoSE模型的有效性。
场景介绍
如下图所示,当用户在GMail搜索框搜索的时候,搜索结果中除了邮件外,如果Google Drive中有匹配的文件结果也会显示出来。尤其是GMail搜索开启了实时搜索功能,GMail的超大规模的搜索请求量对Google Drive来说是一个很重的负担。也许对某些用户来说,在GMail搜索结果查看Google Drive的结果并不是那么的实用;但是对另外一些用户来说却非常实用。
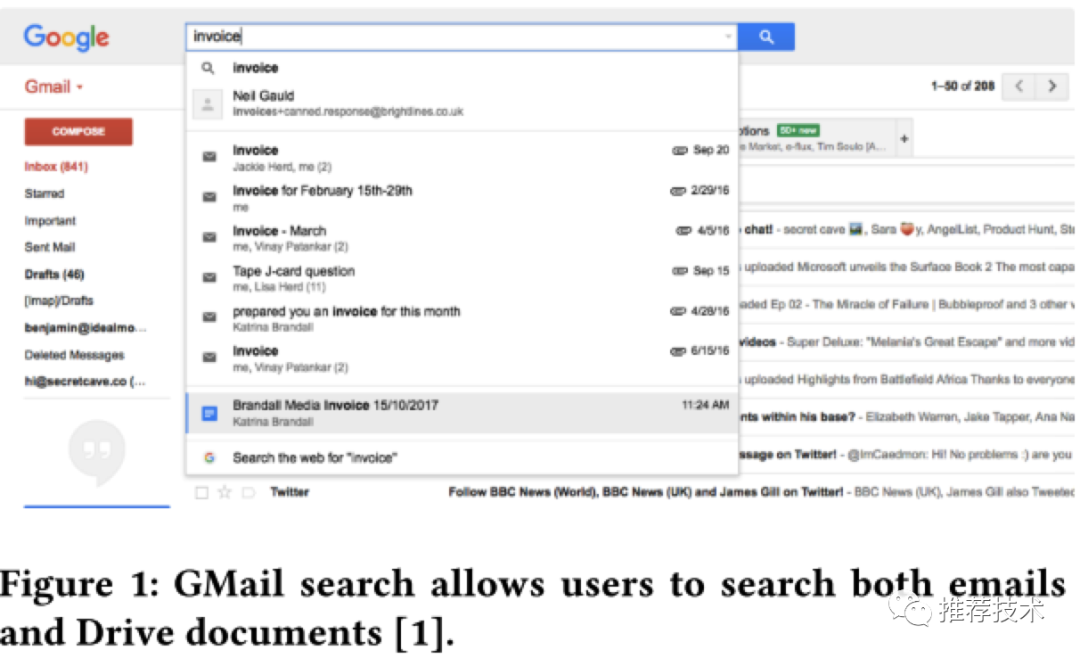
因此,我们需要机器学习的模型来学习是否针对特定的用户打开展示Drive搜索结果的功能。在实际场景中,我们按天来更新用户的这个特性开关。而且我们需要在G家的数据上针对这两个任务进行建模和预测:
Drive搜索结果点击的数量;
用户使用GMail搜索的按键次数;
前者任务是为了判断用户是否需要真实需要Drive搜索结果的特性;后者任务则是对请求搜索Drive文件资源消耗的大致估计。最终是否打开Drive搜索结果特性的开关,则是这两个任务之间的平衡。这两个任务针对用户行为序列的建模有不少的挑战:
需要的变量是高度稀疏的。譬如Drive搜索结果点击数量;
除了GMail的行为记录,我们需要同时使用Drive的行为记录;
这两个任务的目标是错综复杂的。标准的非序列多任务模型很难处理好上面的一些问题。
模型架构
多任务学习框架在用户行为序列场景下有着特定的挑战:首先用户行为数据是稀疏而且异构的;其次多个目标之间的时序联系是复杂的。因此,我们认为需要有特定的模块来针对不同方面的复杂数据进行建模。
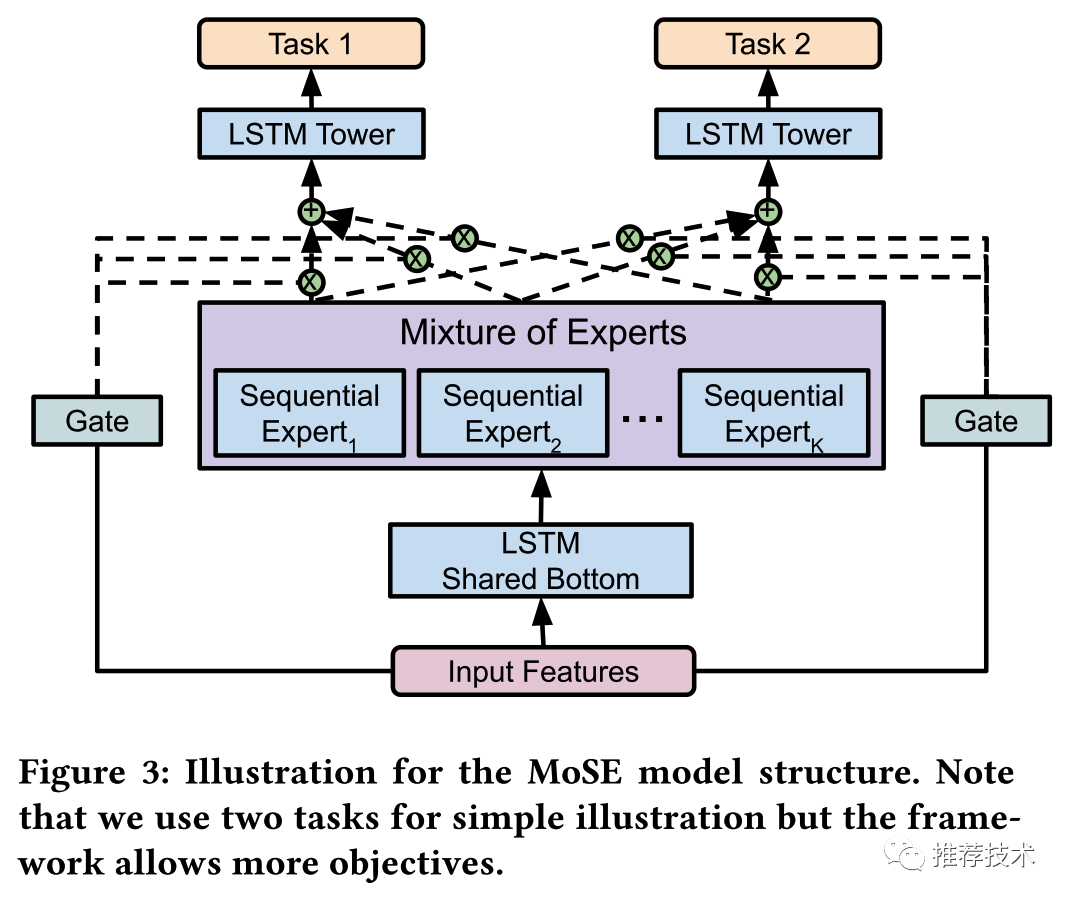
如下图所示,MoSE框架主要由以下的模块构成:
共享底层的LSTM模块在接入序列输入数据;
序列专家层,不同的专家网络用于建模每个任务的不同方面;
Gating网络,用于为不同的任务选择不同序列专家网络的输出;
Task塔网络;
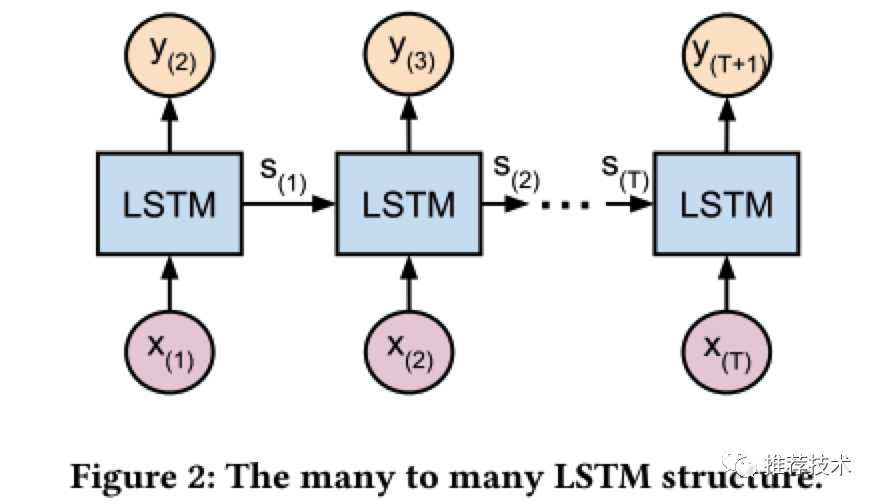
其中,我们应用LSTM进行多对多的序列学习如下图所示,也就是上图MoSE结构中的共享底层LSTM模块。
实验结果
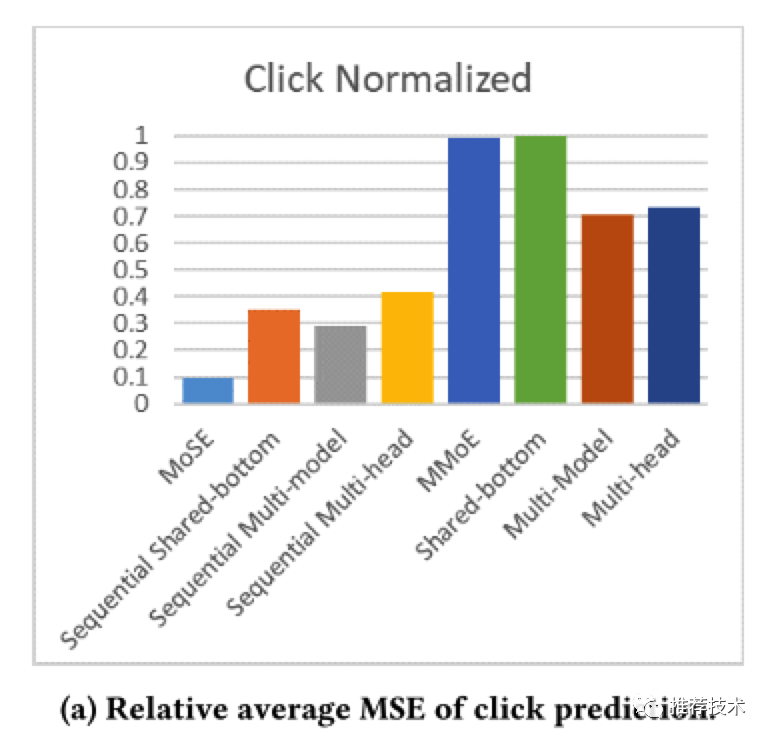
本文的实验同时在合成数据集以及G家数据集上进行了充足的实验,实验结果由于引入了用户行为序列的建模当然比当前的多种多任务学习baseline要更好。下图是在GMail场景数据集上的训练结果,可以看到MoSE的离线训练指标在多个任务上都表现更好。
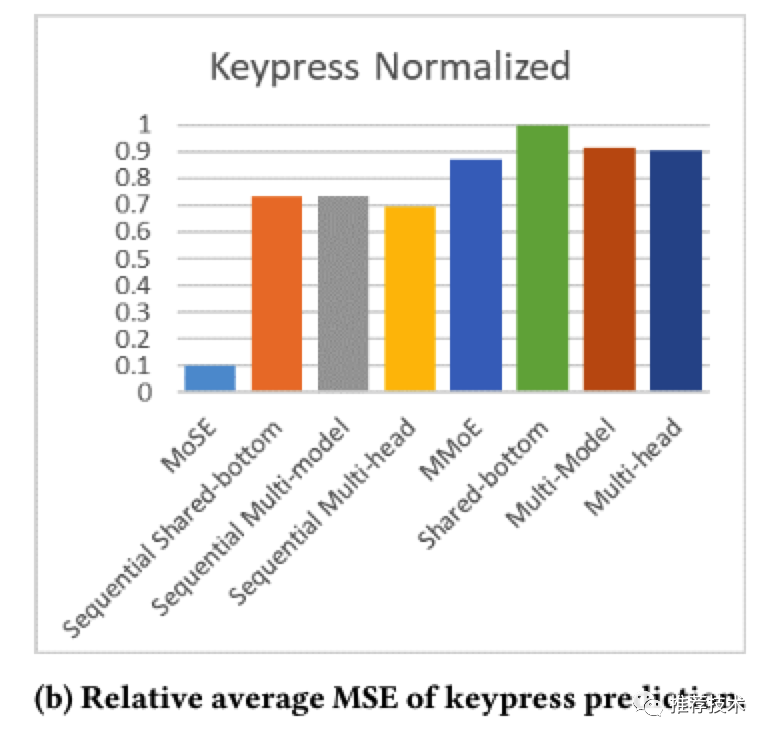
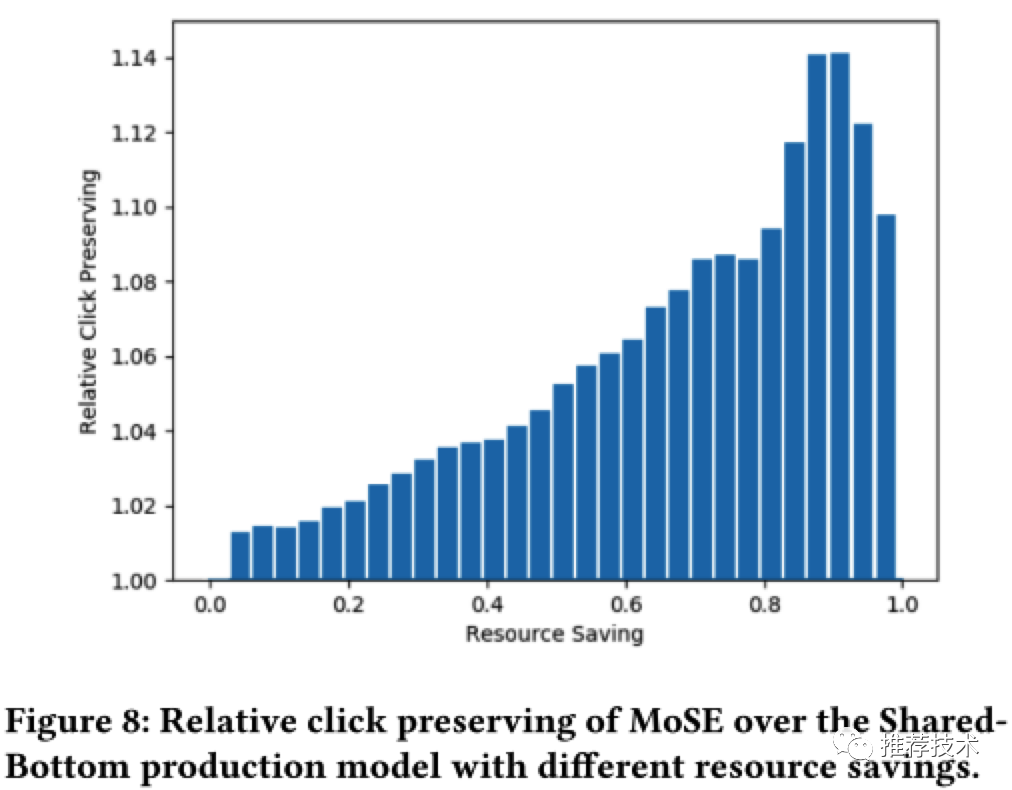
正如之前场景介绍所述,针对特定的用户最终是否打开Drive搜索结果特性的开关,更多是这两个任务之间的平衡。本文也研究了在不同的平衡点,对于Drive搜索结果点击量效果的影响如下图所示。
参考
Multitask Mixture of Sequential Experts for User Activity Streams
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



