【泡泡点云时空】用于点云识别的注意力形状上下文网络(CVPR2018-1)
泡泡点云时空,带你精读机器人顶级会议文章
标题:Attentional ShapeContextNet for Point Cloud Recognition
作者:Saining Xie, Sainan Liu, Zeyu Chen, Zhuowen Tu
来源:CVPR 2018
编译:李敏乐
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

我们解决了点云识别的问题。不像以前的方法,点云需要转换成体积/图像,或者在一个排序不变的集合中独立表示,我们通过将形状上下文的概念作为我们网络设计中的构建块来开发一个新的表示,由此产生的模型,称为ShapeContextNet。
ShapeContextNet由一个层次结构组成,模块不依赖于固定的网格,同时仍然享受与卷积神经网络相似的属性——能够捕获和传播对象部分信息。此外,我们从基于自注意力的模型中获得灵感,包括一个简单而有效的上下文建模机制——使上下文区域选择、特性聚合和特性转换过程完全自动化。
ShapeContextNet是一个端到端的模型,可以应用于一般的点云分类和分割问题。我们在许多基准数据集上获得了具有竞争力的结果。
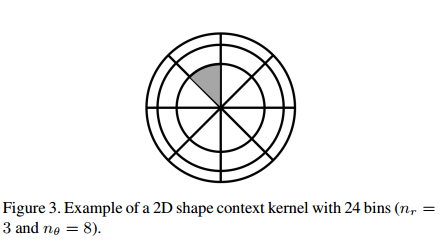
图3显示了我们方法中使用的基本2D形状上下文描述符,以某个点为中心,通过经线纬线将其周围区域划分成若干bin,统计落在每个bin中的点与中心点的关系,所有bin的信息作为特征向量可以表征中心点的邻域信息。(注意,我们使中心单元格更大,与原始单元略有不同形状背景3设计中中心单元相对较好小)。
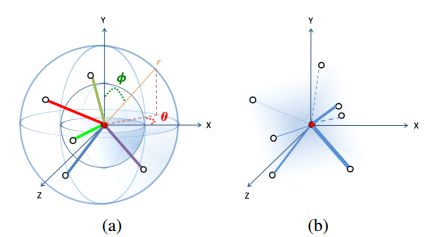
图2展示了ShapeContextNet模块和Attentional ShapeContextNet模块的区别。前者需要预设bin,bin的大小不同可以调节网络对不同区域的关注程度,而后者通过自主学习来达到这一目的。
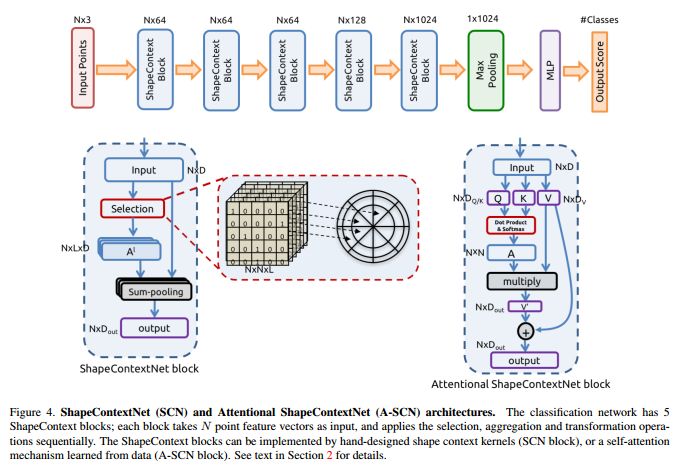
图4展示了网络框架以及ShapeContextNet模块和Attentional ShapeContextNet模块。此处采用了点积自注意力机制(dot-product self-attention)。

Abstract
We tackle the problem of point cloud recognition. Unlike previous approaches where a point cloud is either converted into a volume/image or represented independently in a permutation-invariant set, we develop a new representation by adopting the concept of shape context as the building block in our network design. The resulting model, called ShapeContextNet, consists of a hierarchy with modules not relying on a fixed grid while still enjoying properties similar to those in convolutional neural networks — being able to capture and propagate the object part information. In addition, we find inspiration from self-attention based models to include a simple yet effective contextual modeling mechanism — making the contextual region selection, the feature aggregation, and the feature transformation process fully automatic. ShapeContextNet is an end-to-end model that can be applied to the general point cloud classification and segmentation problems. We observe competitive results on a number of benchmark datasets.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com





