

论文题目:Sample-Efficient Human Evaluation of Large Language Models via Maximum Discrepancy Competition
本文作者:冯科华(浙江大学)、丁科炎(浙江大学)、马柯德(香港城市大学)、王志华(香港城市大学)、张强(浙江大学)、陈华钧(浙江大学)
发表会议:ACL 2025
论文链接:https://arxiv.org/pdf/2404.08008
代码链接:https://github.com/weiji-Feng/MAD-Eval
欢迎转载,转载请注明出处****

一、引言
随着大型语言模型(LLMs)的快速发展,对它们进行可靠评估面临两大挑战:客观指标往往无法准确反映人类对自然语言的感知,而全面的人工标注又成本过高。针对这一问题,本文提出了一种基于最大差异竞争(Maximum Discrepancy Competition, MAD)的样本高效人工评估方法。
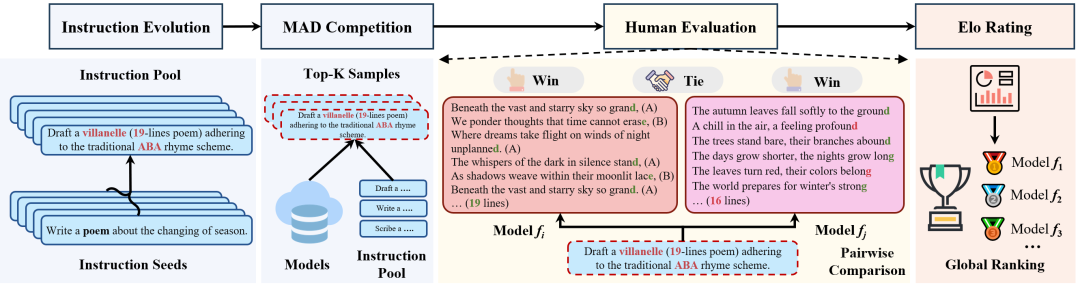
该方法自动从大规模指令集合中选择一小组的输入指令,以最大化LLM响应之间的语义差异,然后由人类评估者进行三选一强制选择比较,并通过Elo评分系统将结果整合为全局排名。我们在科学知识理解、数学推理、创意写作和代码生成四个核心任务上对八种广泛使用的LLM进行了评估,实验结果表明,该方法能够通过少量MAD选择的指令恢复"黄金标准"模型排名,揭示各LLM的优缺点,并为未来LLM发展提供有价值的见解。 二、方法
设 表示一个收集自各种实用自然语言处理任务的大型未标记(即没有准确答案)的指令池。我们希望比较 个竞争的LLM,表示为 ,其中每个模型 对任意输入 产生输出 。人类评估者在环境 中能够可靠地判断同一输入的两个响应的相对质量。在严格限制人类标注数量的条件下,我们的目标是基于少量精心选择的比较,产生 中LLM的明确全局排名。
1. 最大差异竞争原理
首先考虑比较两个LLM 和 的简单情况。根据最大差异(MAD)竞争原理,我们寻找指令: 其中 表示量化两个响应语义差异的距离度量。对 与 的比较分析可产生三种结果:
-
:大多数人类评估者偏好 ,使其成为明显赢家。所选 成为 的反例,对排名两模型的相对性能具有高度信息价值。
-
:相反, 占优,表明评估者明显偏好 。 作为 的反例,最大程度区分两个模型。
-
:评估者给两个响应相似评分,形成平局。平局分两种:
-
高评分平局:两个响应都获得高评价,表明每个模型能生成多样且令人满意的回答。
-
低评分平局:两个输出都得分较低,表明每个模型以不同方式失败。
仅选择响应相似度最低的 个指令可能产生狭窄的失败案例集。为鼓励更广泛探索模型行为,我们添加多样性项:选择第 个指令时,求解: 其中 是先前选择的指令集, 测量 与 任意元素的最大差异, 平衡差异与多样性。 对所有 对模型重复此程序并每对保留 个指令,我们构建MAD响应集: 其大小仅随 增长,与 无关。
2. 通过Elo评分实现全局排名
对于每个选定指令及其配对输出,人类评估者执行三选一强制选择任务,结果记为: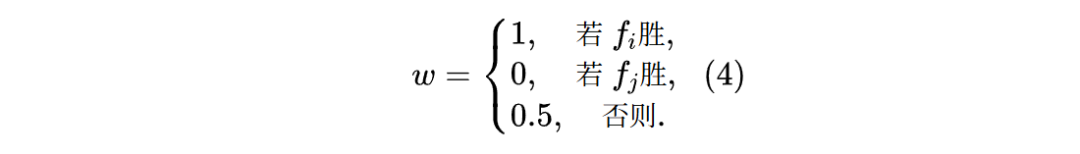
1. 实验设置
指令池构建:构建了跨多场景的大规模指令集,通过:(1) 确定评估场景,(2) 收集基准数据集中的指令种子,(3) 使用指令演化方法生成模拟真实人机交互的指令。评估四个能力层次:科学知识理解、数学推理、创意写作和代码生成。每个场景采样3K指令种子,经10次演化,最终获得每场景30K指令。 用于排名的LLM选择:选择了8个广泛认可的LLM,包括3个专有模型(GPT-3.5-Turbo、GPT-4-Turbo、Gemini-Pro)和5个开源模型(WizardLM-13B、Vicuna-13B、OpenChat-3.5、Qwen-14B-Chat、ChatGLM3-6B)。 相似度度量选择:采用计算嵌入向量余弦相似度的方法,使用OpenAI的text-embedding-ada-002模型。 人类偏好收集:使用三选一强制选择方法(即胜、负、平),参与者选择质量更优的回应。我们为每对比较的LLM选择10个差异最大化指令,总共280次()次比较,由13名STEM背景研究生评估。
2. 主要实验结论
**2.1. 总体排名
我们在表1中提供了总体和各场景的排名结果,揭示了几个有趣现象。
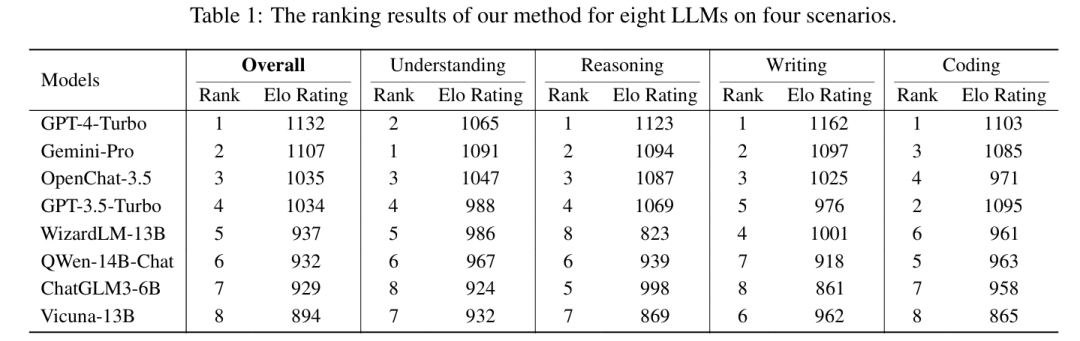
科学知识理解方面,专有LLM(GPT-4-Turbo、GPT-3.5-Turbo和Gemini-Pro)因精确全面的科学知识理解通常优于开源LLM。有趣的是,仅有70亿参数的OpenChat-3.5提供细致解释同时包含核心知识,获得多数人类评估者青睐,最终排名高于回应相对简洁的专有模型GPT-3.5-Turbo。其他开源模型如Vicuna-13B虽提供更长回应,但倾向于冗余解释。 数学推理方面,我们的排名结果与GSM8K数据集排行榜高度一致。通过分析MAD competition选出的response对,我们观察到两类差异:1) 不同的推理路径和 2) 相似推理思路中包含不同计算结果。WizardLM-13B表现相对较差,可能因其训练数据来自未针对数学推理优化的指令集。 创意写作方面,MAD竞争选出的大多数指令是无约束、开放式的自由写作提示。人类评估者更倾向于回应更长、细节更丰富的LLM。例如,ChatGLM3-6B平均生成221.2个词,而GPT-4-Turbo平均生成454.8个词。 代码生成与解释方面,人类评估者不仅评估代码正确性,还评估遵循指令能力(如行数限制、指定Python库使用等)。LLM在代码生成任务上比代码解释表现出更大差异。结果与HumanEval等代码基准一致,如GPT-4-Turbo(76.83)、GPT-3.5-Turbo(74.39)和Gemini Pro(59.76)在HumanEval上准确率高,也获得人类评估者最高偏好。
**2.2 与现有高效采样框架比较
我们将MAD竞争采样算法与五种基线进行比较:1) DiffUse采样框架,2) Anchor Points方法,3) KL散度,4) 基于交叉熵的采样算法,以及5) 随机采样。结果如表3所示。
**2.3 与现有排行榜比较
我们将总体排名结果与三种现有LLM排行榜进行比较:(1)基于人类评估的Chatbot Arena,(2)基于LLM评判的AlpacaEval-2.0,(3)基于标准指标的CompassRank。表2展示了各排行榜上LLM的相对排名。 Chatbot Arena作为一种劳动密集型众包方法,收集了跨多场景的大量人类偏好标注,并使用Elo评分系统对LLM进行排名,可视为人类评估方法的"黄金"标准。我们的排名结果与Chatbot Arena非常相似,仅Vicuna-13B的排名因场景数据比例不同而略有差异。值得注意的是,Chatbot Arena依赖大规模LLM对战和众多人类标注,而我们的方法自动选择少量信息丰富的样本进行人类标注,节省了时间和精力。
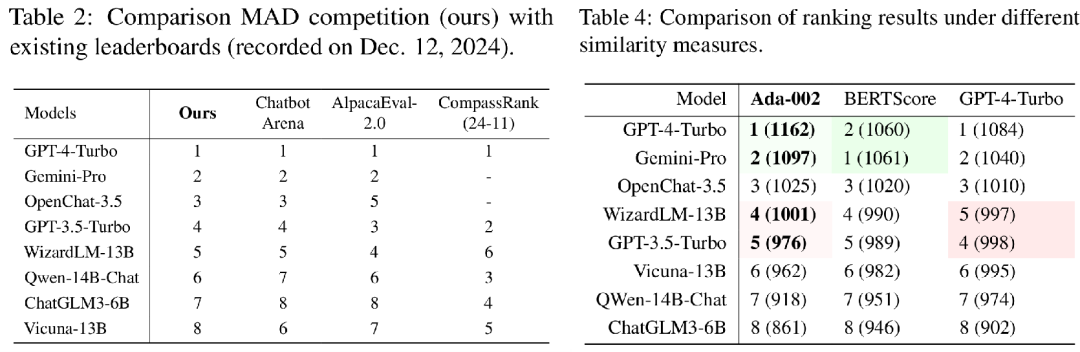
- 消融研究 **相似度测量方法的敏感性。**我们首先研究结果对不同语义相似度测量方法的敏感性。除了使用的text-embedding-ada-002外,我们还采用了BERTScore和LLM作为评判的方法。以写作场景为例,这三种度量方法得出的全局排名几乎一致(见表4)。这归因于MAD竞争选择能有效区分两个模型最大差异的指令,所有三种指标都能很好地近似这一点。
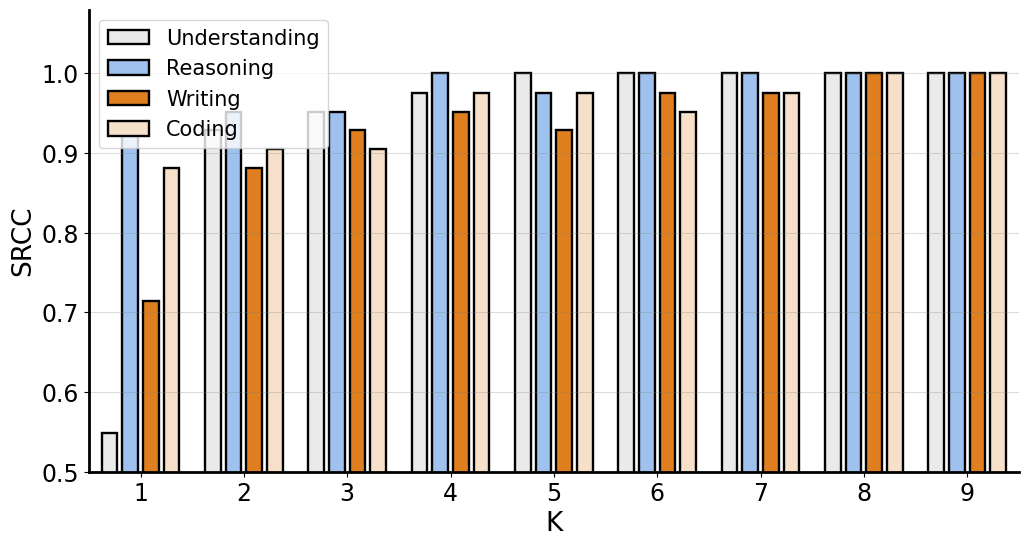
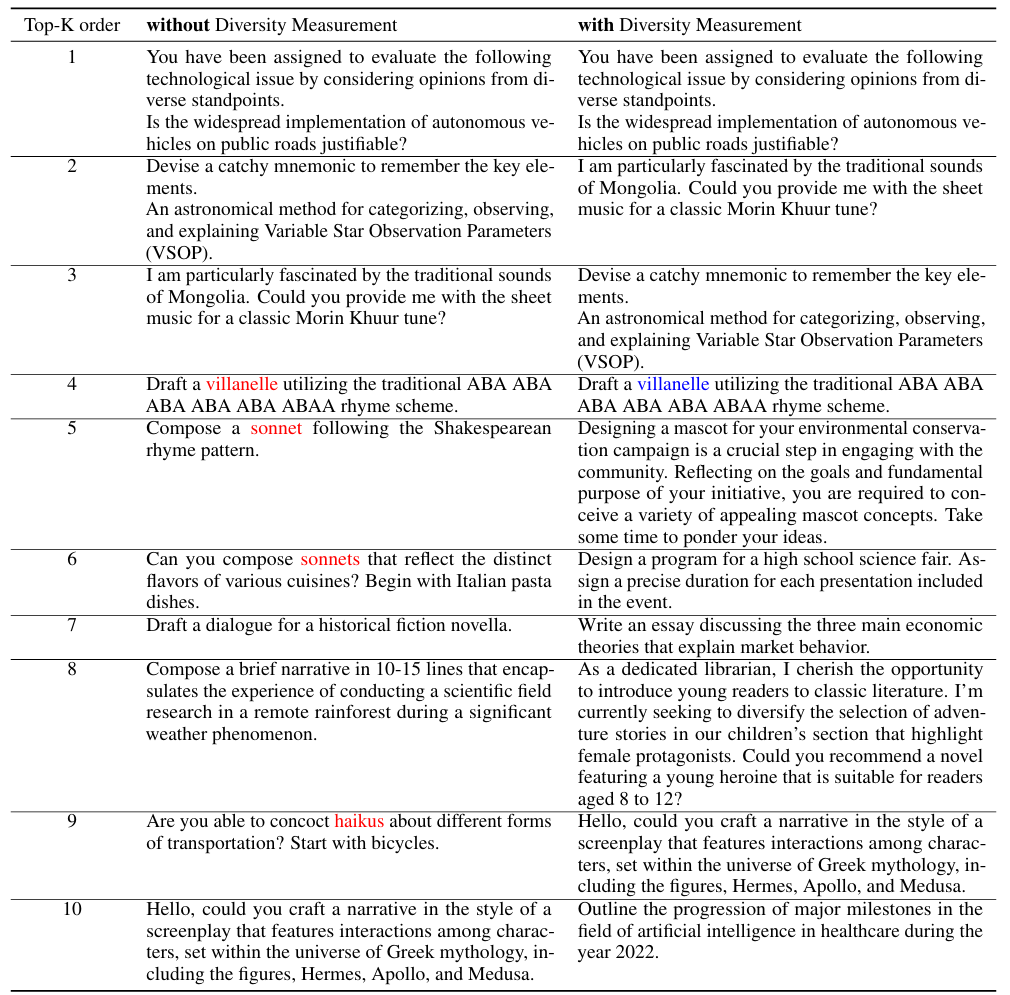
**采样指令数量的稳健性。**我们研究排名结果对人工判断的采样指令数量的稳健性。图2显示了默认top-10排名与其他top-排名之间的斯皮尔曼秩相关系数(SRCC)。所有场景的排名结果都表现出高度稳定性(时SRCC>0.95,时SRCC=1),证明了该方法的样本效率。虽然较大的值提高可靠性,但也增加成本。为平衡可靠性和效率,我们将默认设为10。值得一提的是,值可以灵活调整,并可能因竞争的LLM对而异。如果两个LLM性能相近,我们可以增加进行更多比较;如果性能差异显著,我们可以减少(甚至设为零)以最小化人力成本。这类似于Chatbot Arena中两个LLM之间的对战次数不固定。 **指令多样性度量的重要性。**我们还探讨了方程2中指令多样性度量的重要性()。下表展示了考虑多样性前后,MAD竞争在写作场景中选择的前10条指令。不考虑多样性时,四条指令与诗歌相关,导致场景和任务选择相对同质。考虑多样性后,每条指令几乎代表独特的任务和场景。我们认为场景多样性有利于探索更多类型的模型失败,从而提供更具指导意义的评估见解。
我们测试了。时,指令显示主题重叠和类似失败,限制了全面评估。时,主题多样性增加,但响应差异减少,增加了"平局",违反MAD原则。因此,选择以平衡多样性和差异化。 四、总结
本论文提出了一种样本高效的人工评估方法,通过最大差异竞争方法对大型语言模型(LLM)进行排名。我们强调,我们的方法不是手动策划带有人工标注的固定测试集,而是自动采样一小组信息丰富的指令来区分LLM的性能,从而显著减少人力劳动。此外,通过MAD竞争收集的反例数据不仅是评估前沿LLM的手段,还有助于训练更加健壮的模型(例如对抗训练)。同时,所提出的方法可以扩展到多模态LLM,其输入包括图像、音频和视频等多种类型的数据。在这种扩展中,我们需要在构建指令池时考虑其他模态,而不需要对其他程序进行重大修改。未来,我们将增加LLM的数量并通过纳入更多场景扩大评估范围,最终创建一个向公众开放的综合排行榜。
