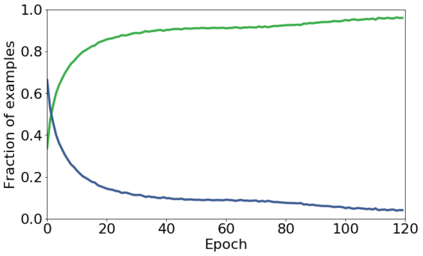
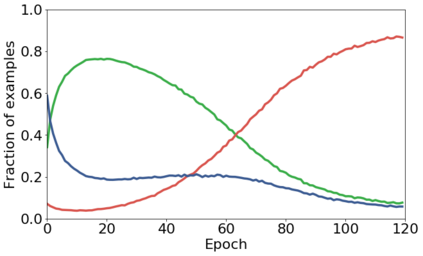
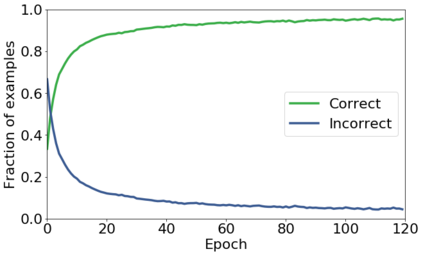
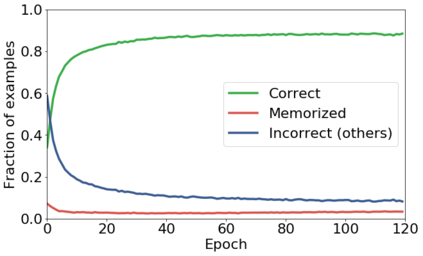
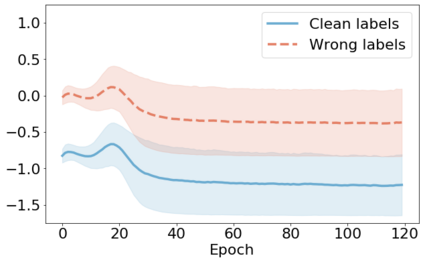
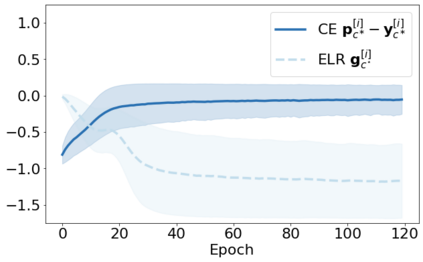
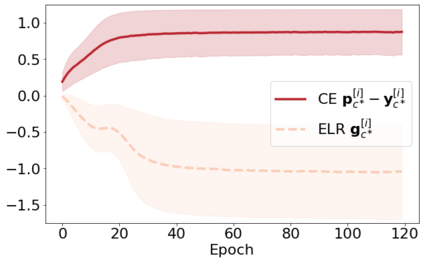
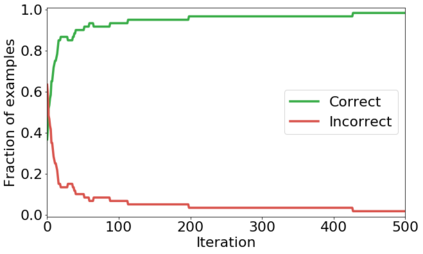
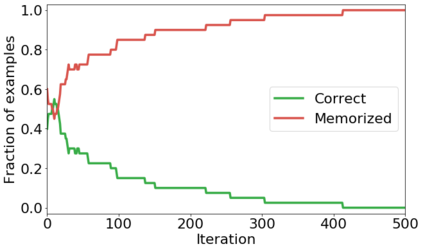
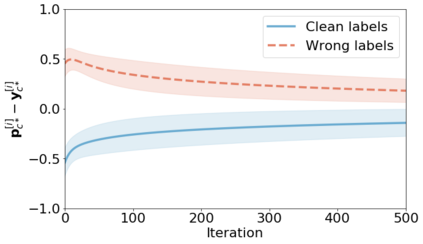
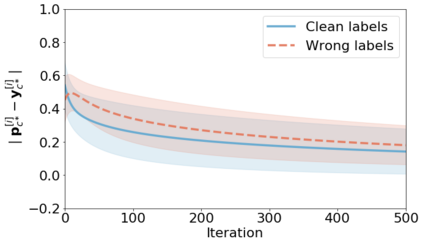
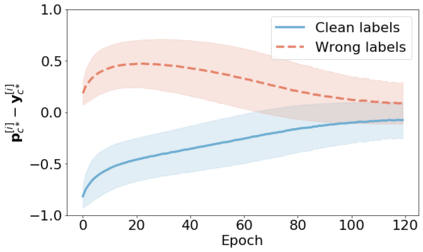
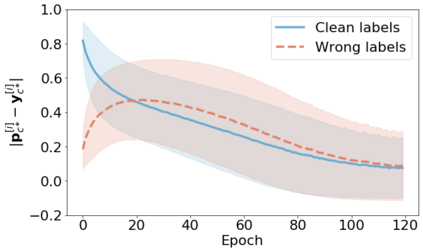
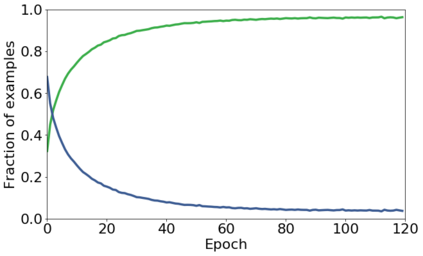
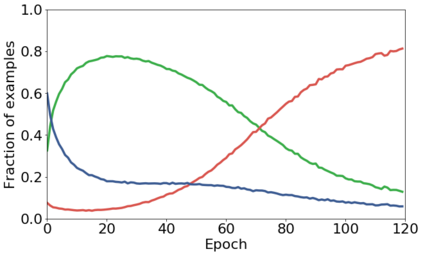
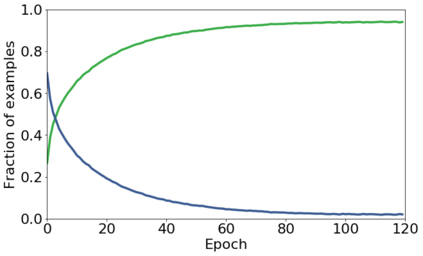
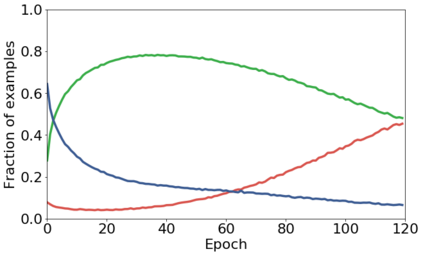
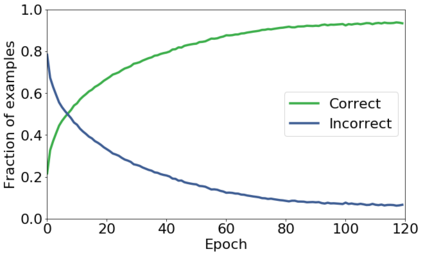
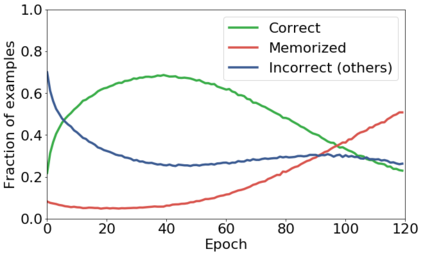
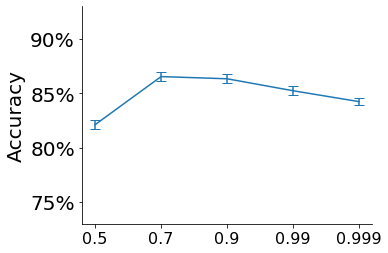
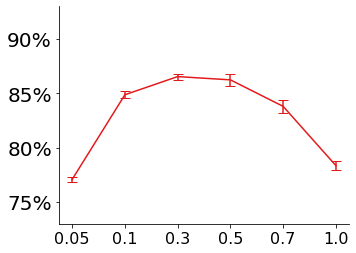
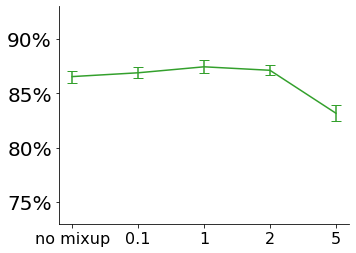
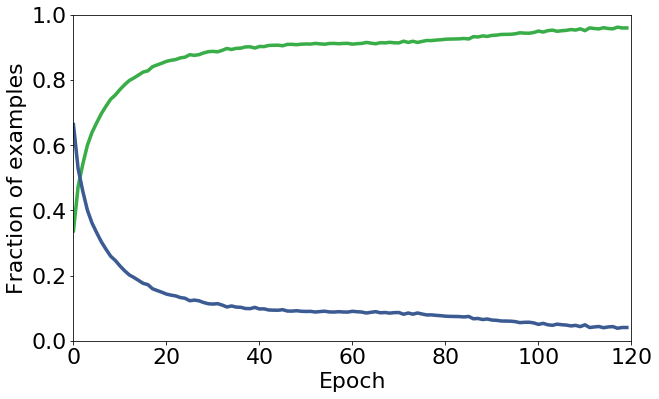
We propose a novel framework to perform classification via deep learning in the presence of noisy annotations. When trained on noisy labels, deep neural networks have been observed to first fit the training data with clean labels during an "early learning" phase, before eventually memorizing the examples with false labels. We prove that early learning and memorization are fundamental phenomena in high-dimensional classification tasks, even in simple linear models, and give a theoretical explanation in this setting. Motivated by these findings, we develop a new technique for noisy classification tasks, which exploits the progress of the early learning phase. In contrast with existing approaches, which use the model output during early learning to detect the examples with clean labels, and either ignore or attempt to correct the false labels, we take a different route and instead capitalize on early learning via regularization. There are two key elements to our approach. First, we leverage semi-supervised learning techniques to produce target probabilities based on the model outputs. Second, we design a regularization term that steers the model towards these targets, implicitly preventing memorization of the false labels. The resulting framework is shown to provide robustness to noisy annotations on several standard benchmarks and real-world datasets, where it achieves results comparable to the state of the art.
翻译:我们提议了一个新的框架,通过在噪音说明下进行深层次的学习进行分类。当在噪音标签上培训时,深神经网络被观察到在“早期学习”阶段首先将培训数据与清洁标签匹配起来,然后最终用假标签将例子记住。我们证明早期学习和记忆化是高层次分类任务中的基本现象,即使是简单的线性模型,并在这一背景下提供理论解释。我们受这些研究结果的激励,我们开发了一种噪音分类任务的新技术,利用早期学习阶段的进展。与现有的方法形成对比,后者在早期学习期间使用模型输出来用清洁标签来探测实例,或者忽略或试图纠正假标签,我们采取不同的路线,而通过正规化来利用早期学习。我们的方法有两个关键要素。首先,我们利用半超强的学习技术来产生基于模型输出结果的目标概率。第二,我们设计了一个正规化术语来引导模型走向这些目标,隐含防止错误标签的记忆化。与现有的方法不同,即早期学习时使用模型来用干净标签来检测实例,或者忽略或试图纠正错误标签的范例,我们采用不同的途径,而是通过正规化的方法,而利用早期学习方法来利用早期的早期学习过程。我们的方法有两种方法,用两种方法,从而提供可靠的标准,从而实现真实的标准,从而实现真实性的数据,从而实现真实性地展示,从而实现真实性地描述。