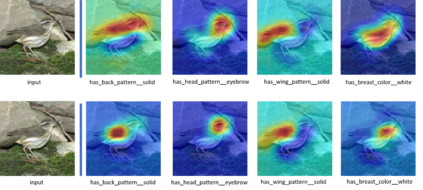
Zero-shot learning (ZSL) aims to discriminate images from unseen classes by exploiting relations to seen classes via their semantic descriptions. Some recent papers have shown the importance of localized features together with fine-tuning the feature extractor to obtain discriminative and transferable features. However, these methods require complex attention or part detection modules to perform explicit localization in the visual space. In contrast, in this paper we propose localizing representations in the semantic/attribute space, with a simple but effective pipeline where localization is implicit. Focusing on attribute representations, we show that our method obtains state-of-the-art performance on CUB and SUN datasets, and also achieves competitive results on AWA2 dataset, outperforming generally more complex methods with explicit localization in the visual space. Our method can be implemented easily, which can be used as a new baseline for zero shot learning.
翻译:零点学习(ZSL)的目的是通过语义描述将关系利用到视觉类中去,从而区分隐蔽类中的图像。最近的一些论文表明,地方性特征以及微调特征提取器对于获得区别性和可转移特征的重要性,然而,这些方法需要复杂的关注或部分检测模块,才能在视觉空间实现明确的定位。相比之下,我们在本文件中建议,在语义/归属空间中采用一个简单而有效的管道,其中隐含了本地化。我们注重属性表达,我们显示,我们的方法在CUB和SUN数据集上取得了最先进的性能,在AWA2数据集上也取得了竞争性的结果,在视觉空间中明显本地化,这些方法通常比比较复杂。我们的方法可以很容易地实施,可以用作零镜头学习的新基线。