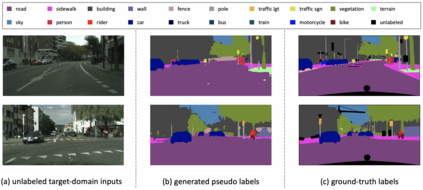
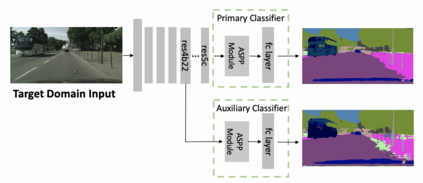
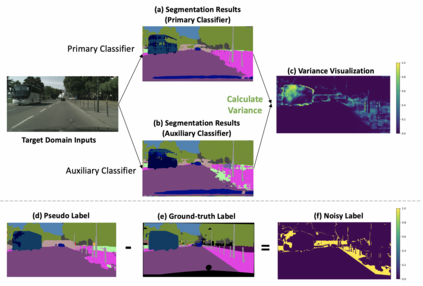
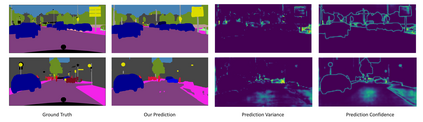
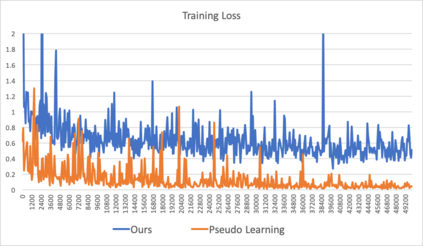
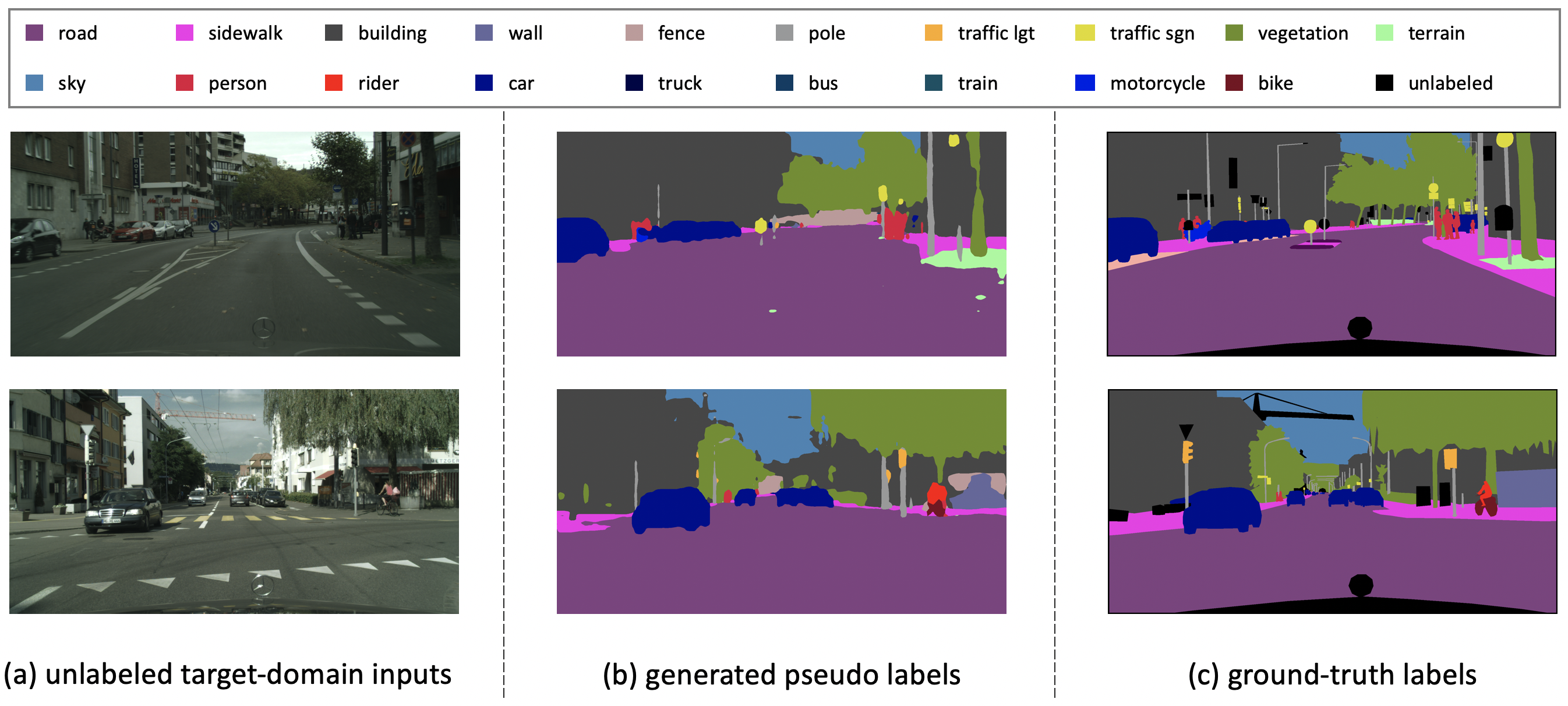
This paper focuses on the unsupervised domain adaptation of transferring the knowledge from the source domain to the target domain in the context of semantic segmentation. Existing approaches usually regard the pseudo label as the ground truth to fully exploit the unlabeled target-domain data. Yet the pseudo labels of the target-domain data are usually predicted by the model trained on the source domain. Thus, the generated labels inevitably contain the incorrect prediction due to the discrepancy between the training domain and the test domain, which could be transferred to the final adapted model and largely compromises the training process. To overcome the problem, this paper proposes to explicitly estimate the prediction uncertainty during training to rectify the pseudo label learning for unsupervised semantic segmentation adaptation. Given the input image, the model outputs the semantic segmentation prediction as well as the uncertainty of the prediction. Specifically, we model the uncertainty via the prediction variance and involve the uncertainty into the optimization objective. To verify the effectiveness of the proposed method, we evaluate the proposed method on two prevalent synthetic-to-real semantic segmentation benchmarks, i.e., GTA5 -> Cityscapes and SYNTHIA -> Cityscapes, as well as one cross-city benchmark, i.e., Cityscapes -> Oxford RobotCar. We demonstrate through extensive experiments that the proposed approach (1) dynamically sets different confidence thresholds according to the prediction variance, (2) rectifies the learning from noisy pseudo labels, and (3) achieves significant improvements over the conventional pseudo label learning and yields competitive performance on all three benchmarks.
翻译:本文侧重于将知识从源域转移到语义区段目标域的未经监督的领域适应性。 现有方法通常将假标签视为地面真理, 以充分利用未贴标签的目标域域数据。 然而目标域数据的假标签通常由源域培训的模型预测。 因此, 生成的标签必然包含不正确的预测, 原因是培训域与测试域之间的差异, 这可能会转移到最终调整的模型, 并在很大程度上损害培训进程。 为了克服问题, 本文建议明确估计培训期间的预测不确定性, 以纠正为不受监督的语义区段调整的假标签性能学习。 鉴于输入图像, 目标域域数据的伪标签标签标签标签标签标签标签通常由源域域域域培训培训的模型预测。 具体地说, 我们通过预测差异来模拟不确定性, 并将不确定性纳入优化目标。 为了核实拟议方法的有效性, 我们评估了两种常见的合成至真实的标签分级分类分级标准的拟议方法, 即: GTA5 - > 市级测试和SYANTA > 的模拟性性业绩学习, 从一个城市的跨级标。