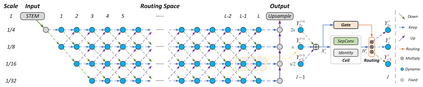
Recently, numerous handcrafted and searched networks have been applied for semantic segmentation. However, previous works intend to handle inputs with various scales in pre-defined static architectures, such as FCN, U-Net, and DeepLab series. This paper studies a conceptually new method to alleviate the scale variance in semantic representation, named dynamic routing. The proposed framework generates data-dependent routes, adapting to the scale distribution of each image. To this end, a differentiable gating function, called soft conditional gate, is proposed to select scale transform paths on the fly. In addition, the computational cost can be further reduced in an end-to-end manner by giving budget constraints to the gating function. We further relax the network level routing space to support multi-path propagations and skip-connections in each forward, bringing substantial network capacity. To demonstrate the superiority of the dynamic property, we compare with several static architectures, which can be modeled as special cases in the routing space. Extensive experiments are conducted on Cityscapes and PASCAL VOC 2012 to illustrate the effectiveness of the dynamic framework. Code is available at https://github.com/yanwei-li/DynamicRouting.
翻译:最近,许多手工艺和搜索的网络被应用于语义分解,然而,先前的工作打算处理预先界定的静态结构,如FCN、U-Net和DeepLab系列中各种规模的投入。本文研究一种概念上的新方法,以缓解语义表达方式上的规模差异,称为动态路由。拟议框架产生数据依赖路径,适应每个图像的大小分布。为此,提议在飞行上选择一个称为软有条件门的可区分格子功能。此外,计算成本还可以以最终到终端的方式进一步降低,办法是对定位功能给予预算限制。我们进一步放松网络水平的路径空间,以支持多方向传播和每个前方的跳过连接,带来巨大的网络能力。为显示动态属性的优越性,我们与若干静态结构进行比较,这些结构可以作为路线空间的特殊案例进行模拟。在城市景象和PASAL VOC进行广泛的实验,以展示动态框架的有效性。代码可在 http://weiyan/dominacyal.code 上查阅。