
主题: Learning Video Object Segmentation from Unlabeled Videos
摘要:
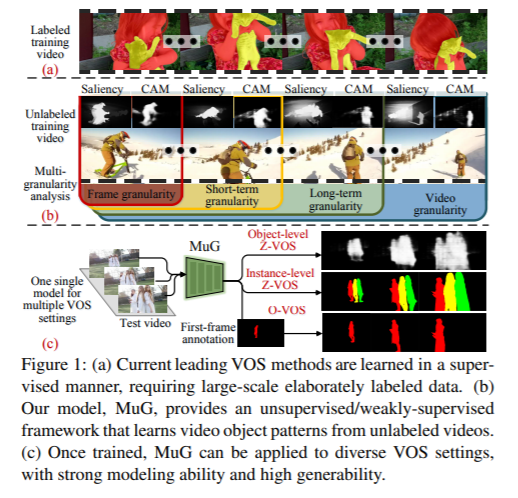
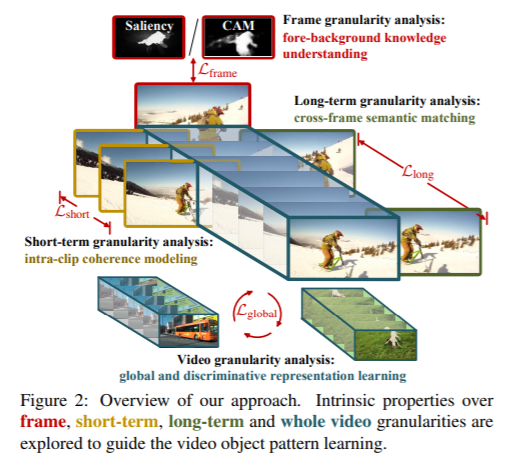
我们提出了一种新的视频对象分割方法(VOS),解决了从未标记的视频中学习对象模式的问题,而现有的方法大多依赖于大量的带注释的数据。我们引入了一个统一的无监督/弱监督学习框架,称为MuG,它全面地捕捉了VOS在多个粒度上的内在特性。我们的方法可以帮助提高对VOS中可视模式的理解,并显著减少注释负担。经过精心设计的体系结构和强大的表示学习能力,我们的学习模型可以应用于各种VOS设置,包括对象级零镜头VOS、实例级零镜头VOS和单镜头VOS。实验表明,在这些设置下,有良好的性能,以及利用无标记数据进一步提高分割精度的潜力。
成为VIP会员查看完整内容
相关内容

专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
36+阅读 · 2020年3月13日
专知会员服务
26+阅读 · 2020年2月16日
专知会员服务
85+阅读 · 2019年11月15日
Arxiv
3+阅读 · 2018年12月13日
Arxiv
7+阅读 · 2018年3月28日
Arxiv
3+阅读 · 2018年3月4日
Arxiv
6+阅读 · 2018年1月28日




相关VIP内容
专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
36+阅读 · 2020年3月13日
专知会员服务
26+阅读 · 2020年2月16日
专知会员服务
85+阅读 · 2019年11月15日
相关资讯