【论文推荐】最新七篇图像分割相关论文—Attention U-Net、对抗结构匹配损失、卷积CRFs、对抗样本、弱监督分割
【导读】专知内容组推出近期七篇图像分割(Image Segmentation)相关文章,为大家进行介绍,欢迎查看!
1.Attention U-Net: Learning Where to Look for the Pancreas(Attention U-Net:学习在哪里寻找胰腺)
作者:Ozan Oktay,Jo Schlemper,Loic Le Folgoc,Matthew Lee,Mattias Heinrich,Kazunari Misawa,Kensaku Mori,Steven McDonagh,Nils Y Hammerla,Bernhard Kainz,Ben Glocker,Daniel Rueckert
Accepted to published in MIDL'18
机构:University of Luebeck,Nagoya University
摘要:We propose a novel attention gate (AG) model for medical imaging that automatically learns to focus on target structures of varying shapes and sizes. Models trained with AGs implicitly learn to suppress irrelevant regions in an input image while highlighting salient features useful for a specific task. This enables us to eliminate the necessity of using explicit external tissue/organ localisation modules of cascaded convolutional neural networks (CNNs). AGs can be easily integrated into standard CNN architectures such as the U-Net model with minimal computational overhead while increasing the model sensitivity and prediction accuracy. The proposed Attention U-Net architecture is evaluated on two large CT abdominal datasets for multi-class image segmentation. Experimental results show that AGs consistently improve the prediction performance of U-Net across different datasets and training sizes while preserving computational efficiency. The code for the proposed architecture is publicly available.

期刊:arXiv, 2018年5月21日
网址:
http://www.zhuanzhi.ai/document/c26e8950c5e25001223cd971d127f713
2.Adversarial Structure Matching Loss for Image Segmentation(对抗结构匹配损失的图像分割)
作者:Jyh-Jing Hwang,Tsung-Wei Ke,Jianbo Shi,Stella X. Yu
机构:University of Pennsylvania
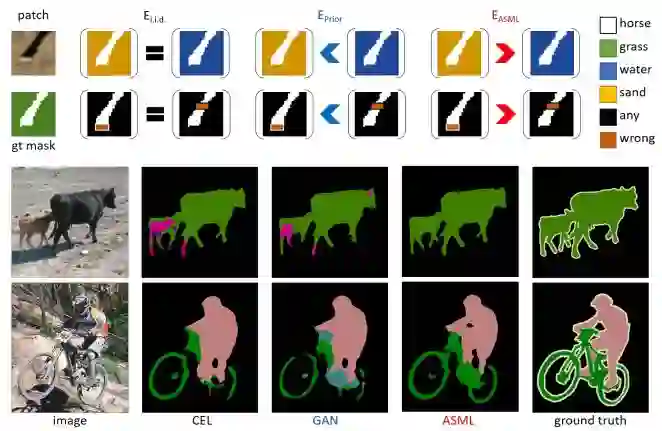
摘要:The per-pixel cross-entropy loss (CEL) has been widely used in structured output prediction tasks as a spatial extension of generic image classification. However, its i.i.d. assumption neglects the structural regularity present in natural images. Various attempts have been made to incorporate structural reasoning mostly through structure priors in a cooperative way where co-occuring patterns are encouraged. We, on the other hand, approach this problem from an opposing angle and propose a new framework for training such structured prediction networks via an adversarial process, in which we train a structure analyzer that provides the supervisory signals, the adversarial structure matching loss (ASML). The structure analyzer is trained to maximize ASML, or to exaggerate recurring structural mistakes usually among co-occurring patterns. On the contrary, the structured output prediction network is trained to reduce those mistakes and is thus enabled to distinguish fine-grained structures. As a result, training structured output prediction networks using ASML reduces contextual confusion among objects and improves boundary localization. We demonstrate that ASML outperforms its counterpart CEL especially in context and boundary aspects on figure-ground segmentation and semantic segmentation tasks with various base architectures, such as FCN, U-Net, DeepLab, and PSPNet.
期刊:arXiv, 2018年5月19日
网址:
http://www.zhuanzhi.ai/document/8db4b0f0c25f65963d20b12e65998596
3.Convolutional CRFs for Semantic Segmentation(基于卷积CRFs的语义分割)
作者:Marvin T. T. Teichmann,Roberto Cipolla
机构:University of Cambridge
摘要:For the challenging semantic image segmentation task the most efficient models have traditionally combined the structured modelling capabilities of Conditional Random Fields (CRFs) with the feature extraction power of CNNs. In more recent works however, CRF post-processing has fallen out of favour. We argue that this is mainly due to the slow training and inference speeds of CRFs, as well as the difficulty of learning the internal CRF parameters. To overcome both issues we propose to add the assumption of conditional independence to the framework of fully-connected CRFs. This allows us to reformulate the inference in terms of convolutions, which can be implemented highly efficiently on GPUs. Doing so speeds up inference and training by a factor of more then 100. All parameters of the convolutional CRFs can easily be optimized using backpropagation. To facilitating further CRF research we make our implementation publicly available. Please visit: https://github.com/MarvinTeichmann/ConvCRF

期刊:arXiv, 2018年5月15日
网址:
http://www.zhuanzhi.ai/document/e7f8662d0632aba8ccb2e62dc95196bf
4.Deceiving End-to-End Deep Learning Malware Detectors using Adversarial Examples(使用对抗样本欺骗端到端深度学习的恶意软件检测器)
作者:Felix Kreuk,Assi Barak,Shir Aviv-Reuven,Moran Baruch,Benny Pinkas,Joseph Keshet
机构:Bar-Ilan University
摘要:In recent years, deep learning has shown performance breakthroughs in many applications, such as image detection, image segmentation, pose estimation, and speech recognition. However, this comes with a major concern: deep networks have been found to be vulnerable to adversarial examples. Adversarial examples are slightly modified inputs that are intentionally designed to cause a misclassification by the model. In the domains of images and speech, the modifications are so small that they are not seen or heard by humans, but nevertheless greatly affect the classification of the model. Deep learning models have been successfully applied to malware detection. In this domain, generating adversarial examples is not straightforward, as small modifications to the bytes of the file could lead to significant changes in its functionality and validity. We introduce a novel loss function for generating adversarial examples specifically tailored for discrete input sets, such as executable bytes. We modify malicious binaries so that they would be detected as benign, while preserving their original functionality, by injecting a small sequence of bytes (payload) in the binary file. We applied this approach to an end-to-end convolutional deep learning malware detection model and show a high rate of detection evasion. Moreover, we show that our generated payload is robust enough to be transferable within different locations of the same file and across different files, and that its entropy is low and similar to that of benign data sections.

期刊:arXiv, 2018年5月13日
网址:
http://www.zhuanzhi.ai/document/90e6333ddce0984d7036e906473bbbc9
5.Combo Loss: Handling Input and Output Imbalance in Multi-Organ Segmentation(Combo Loss:处理输入和输出不平衡的多器官分割)
作者:Saeid Asgari Taghanaki,Yefeng Zheng,S. Kevin Zhou,Bogdan Georgescu,Puneet Sharma,Daguang Xu,Dorin Comaniciu,Ghassan Hamarneh
机构:Simon Fraser University
摘要:Simultaneous segmentation of multiple organs from different medical imaging modalities is a crucial task as it can be utilized for computer-aided diagnosis, computer-assisted surgery, and therapy planning. Thanks to the recent advances in deep learning, several deep neural networks for medical image segmentation have been introduced successfully for this purpose. In this paper, we focus on learning a deep multi-organ segmentation network that labels voxels. In particular, we examine the critical choice of a loss function in order to handle the notorious imbalance problem that plagues both the input and output of a learning model. The input imbalance refers to the class-imbalance in the input training samples (i.e. small foreground objects embedded in an abundance of background voxels, as well as organs of varying sizes). The output imbalance refers to the imbalance between the false positives and false negatives of the inference model. We introduce a loss function that integrates a weighted cross-entropy with a Dice similarity coefficient to tackle both types of imbalance during training and inference. We evaluated the proposed loss function on three datasets of whole body PET scans with 5 target organs, MRI prostate scans, and ultrasound echocardigraphy images with a single target organ. We show that a simple network architecture with the proposed integrative loss function can outperform state-of-the-art methods and results of the competing methods can be improved when our proposed loss is used.
期刊:arXiv, 2018年5月12日
网址:
http://www.zhuanzhi.ai/document/58fd3a408110f1701c8f5a40dd3d07cb
6.Semi-Supervised Multi-Organ Segmentation via Deep Multi-Planar Co-Training(基于深度Multi-Planar 协同训练的半监督多器官分割)
作者:Yuyin Zhou,Yan Wang,Peng Tang,Wei Shen,Elliot K. Fishman,Alan L. Yuille
机构:Huazhong University of Science and Technology,Shanghai University,The Johns Hopkins University
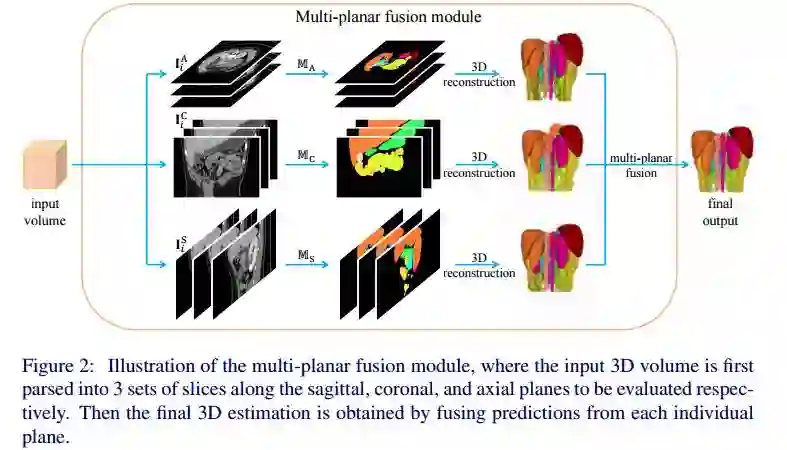
摘要:In multi-organ segmentation of abdominal CT scans, most existing fully supervised deep learning algorithms require lots of voxel-wise annotations, which are usually difficult, expensive, and slow to obtain. In comparison, massive unlabeled 3D CT volumes are usually easily accessible. Current mainstream works to address the semi-supervised biomedical image segmentation problem are mostly graph-based. By contrast, deep network based semi-supervised learning methods have not drawn much attention in this field. In this work, we propose Deep Multi-Planar Co-Training (DMPCT), whose contributions can be divided into two folds: 1) The deep model is learned in a co-training style which can mine consensus information from multiple planes like the sagittal, coronal, and axial planes; 2) Multi-planar fusion is applied to generate more reliable pseudo-labels, which alleviates the errors occurring in the pseudo-labels and thus can help to train better segmentation networks. Experiments are done on our newly collected large dataset with 100 unlabeled cases as well as 210 labeled cases where 16 anatomical structures are manually annotated by four radiologists and confirmed by a senior expert. The results suggest that DMPCT significantly outperforms the fully supervised method by more than 4% especially when only a small set of annotations is used.
期刊:arXiv, 2018年5月12日
网址:
http://www.zhuanzhi.ai/document/99237db7dd9c8105c0342a7367673e3d
7.Constrained-CNN losses for weakly supervised segmentation(基于约束- CNN losses 的弱监督分割)
作者:Hoel Kervadec,Jose Dolz,Meng Tang,Eric Granger,Yuri Boykov,Ismail Ben Ayed
Submitted to the 1st conference on Medical Image with Deep Learning (MIDL)
机构:University of Waterloo
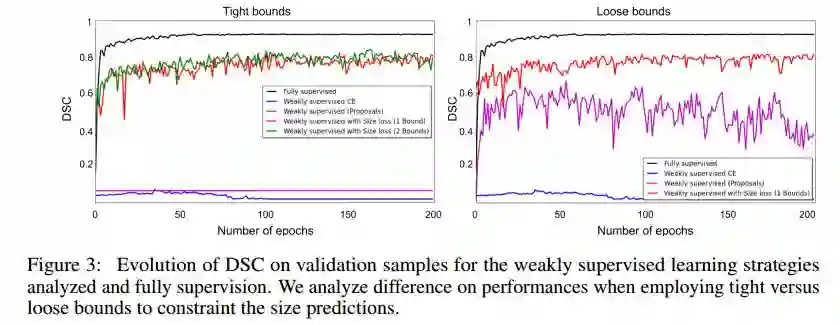
摘要:Weak supervision, e.g., in the form of partial labels or image tags, is currently attracting significant attention in CNN segmentation as it can mitigate the lack of full and laborious pixel/voxel annotations. Enforcing high-order (global) inequality constraints on the network output, for instance, on the size of the target region, can leverage unlabeled data, guiding training with domain-specific knowledge. Inequality constraints are very flexible because they do not assume exact prior knowledge. However,constrained Lagrangian dual optimization has been largely avoided in deep networks, mainly for computational tractability reasons.To the best of our knowledge, the method of Pathak et al. is the only prior work that addresses deep CNNs with linear constraints in weakly supervised segmentation. It uses the constraints to synthesize fully-labeled training masks (proposals)from weak labels, mimicking full supervision and facilitating dual optimization.We propose to introduce a differentiable term, which enforces inequality constraints directly in the loss function, avoiding expensive Lagrangian dual iterates and proposal generation. From constrained-optimization perspective, our simple approach is not optimal as there is no guarantee that the constraints are satisfied. However, surprisingly,it yields substantially better results than the proposal-based constrained CNNs, while reducing the computational demand for training.In the context of cardiac images, we reached a segmentation performance close to full supervision using a fraction (0.1%) of the full ground-truth labels and image-level tags.While our experiments focused on basic linear constraints such as the target-region size and image tags, our framework can be easily extended to other non-linear constraints.Therefore, it has the potential to close the gap between weakly and fully supervised learning in semantic image segmentation.
期刊:arXiv, 2018年5月12日
网址:
http://www.zhuanzhi.ai/document/3bb0669341fda7dc69021d0e4acdd228
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




