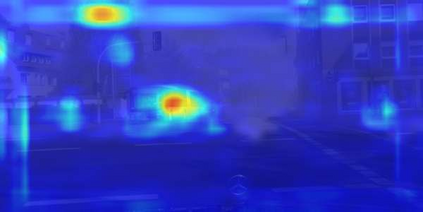
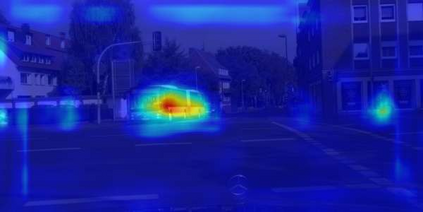
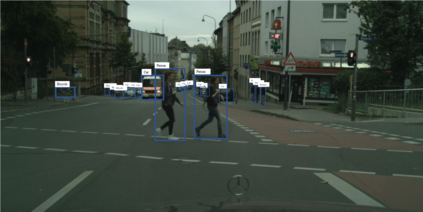
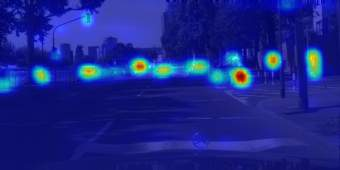
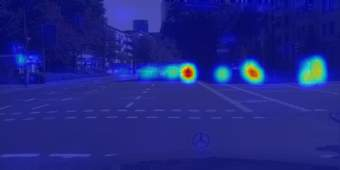
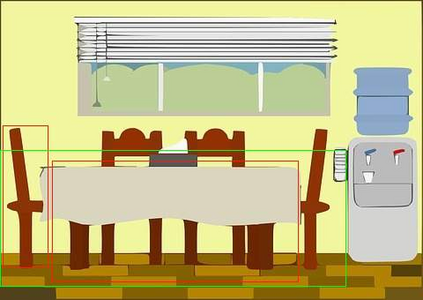
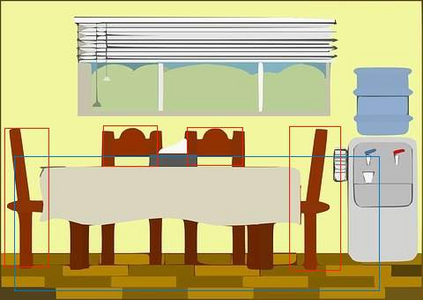
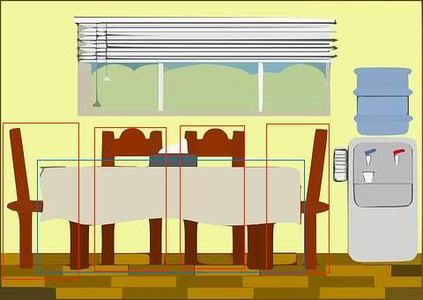
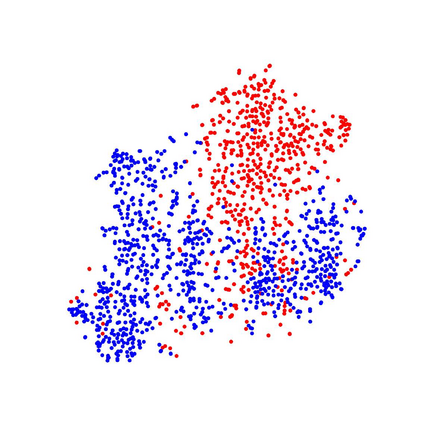
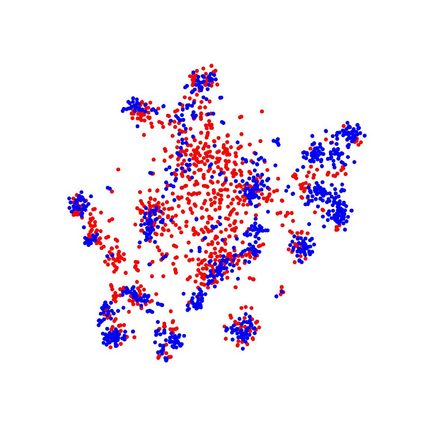
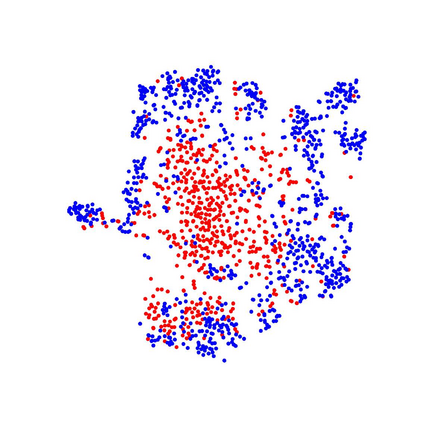
In this paper, we tackle the domain adaptive object detection problem, where the main challenge lies in significant domain gaps between source and target domains. Previous work seeks to plainly align image-level and instance-level shifts to eventually minimize the domain discrepancy. However, they still overlook to match crucial image regions and important instances across domains, which will strongly affect domain shift mitigation. In this work, we propose a simple but effective categorical regularization framework for alleviating this issue. It can be applied as a plug-and-play component on a series of Domain Adaptive Faster R-CNN methods which are prominent for dealing with domain adaptive detection. Specifically, by integrating an image-level multi-label classifier upon the detection backbone, we can obtain the sparse but crucial image regions corresponding to categorical information, thanks to the weakly localization ability of the classification manner. Meanwhile, at the instance level, we leverage the categorical consistency between image-level predictions (by the classifier) and instance-level predictions (by the detection head) as a regularization factor to automatically hunt for the hard aligned instances of target domains. Extensive experiments of various domain shift scenarios show that our method obtains a significant performance gain over original Domain Adaptive Faster R-CNN detectors. Furthermore, qualitative visualization and analyses can demonstrate the ability of our method for attending on the key regions/instances targeting on domain adaptation. Our code is open-source and available at \url{https://github.com/Megvii-Nanjing/CR-DA-DET}.
翻译:在本文中,我们解决了适应性对象探测领域问题,主要挑战在于源和目标领域之间的显著领域差距。以前的工作力求明确调整图像级别和实例级别的变化,最终将域差异降至最小。然而,这些变化仍然被忽略,以匹配关键图像区域和跨域的重要实例,这将极大地影响域转移减缓。在这项工作中,我们提出了一个简单而有效的绝对规范化框架,以缓解这一问题。它可以用作一系列Dealive适应性快速R-CNN方法的插接和播放部分,这是处理域适应性检测方面最突出的。具体地说,通过将图像级别多标签分类器纳入探测主干网,我们可以获得与绝对信息相对的稀少但至关重要的图像区域,因为分类方式的本地化能力薄弱。与此同时,在实例层面,我们利用图像级别预测(通过分类)和实例级预测(通过检测头)之间的绝对一致性作为自动查找目标领域硬一致性实例的固定化因素。对各种域网域变化情况进行广泛的实验,显示我们的方法在原始的域内域内进行显著的视觉分析,并显示我们用于原始的智能检索的系统。