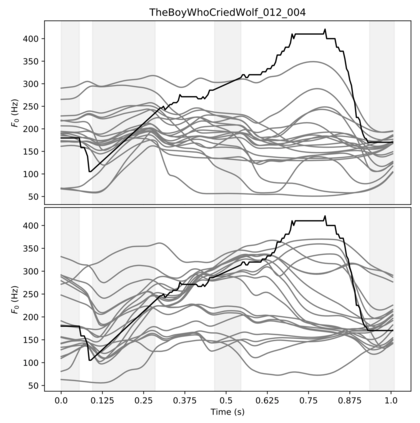
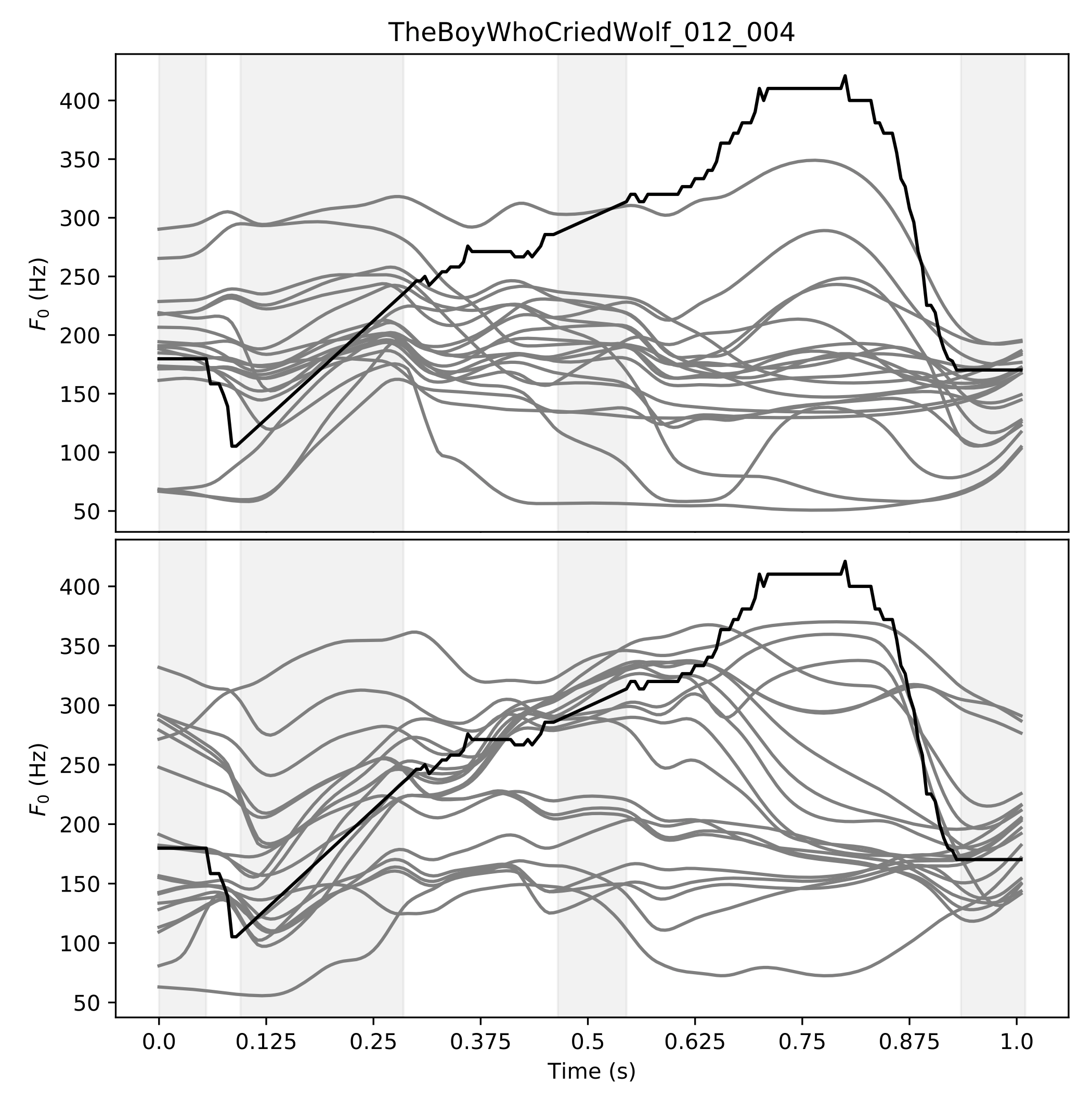
In English, prosody adds a broad range of information to segment sequences, from information structure (e.g. contrast) to stylistic variation (e.g. expression of emotion). However, when learning to control prosody in text-to-speech voices, it is not clear what exactly the control is modifying. Existing research on discrete representation learning for prosody has demonstrated high naturalness, but no analysis has been performed on what these representations capture, or if they can generate meaningfully-distinct variants of an utterance. We present a phrase-level variational autoencoder with a multi-modal prior, using the mode centres as "intonation codes". Our evaluation establishes which intonation codes are perceptually distinct, finding that the intonation codes from our multi-modal latent model were significantly more distinct than a baseline using k-means clustering. We carry out a follow-up qualitative study to determine what information the codes are carrying. Most commonly, listeners commented on the intonation codes having a statement or question style. However, many other affect-related styles were also reported, including: emotional, uncertain, surprised, sarcastic, passive aggressive, and upset.
翻译:在英语中,偏移增加了从信息结构(例如对比)到立体变异(例如情感表达)等信息序列中一系列广泛的信息。然而,当学习控制文本到语音的流体变化时,还不清楚究竟在修改什么控制。关于脱散代言学习的现有的研究显示了高度自然性,但没有对这些表达方式所捕捉的内容或它们能够产生有意义的表达式变异进行分析。我们用模式中心作为“启动代码”来介绍一个多模式前的词级变异自动编码。我们的评估确定了哪些进化代号在概念上是截然不同的,发现我们多模式潜在模型的进化代号比使用K means集群的基线明显不同。我们进行了后续的质量研究,以确定这些代号正在产生什么信息。最常见的是,听众们用声明或问题风格来评论进化代号。然而,许多其他与影响有关的风格也被报道,包括:情感、不稳定性、惊讶和不安定性。