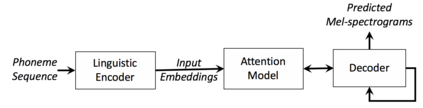
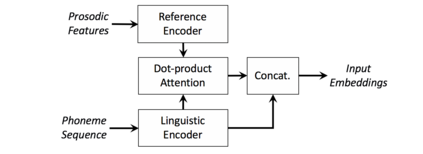
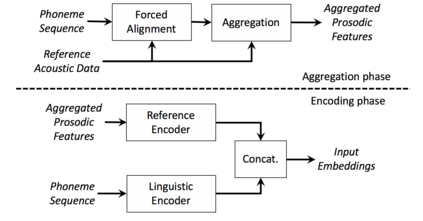
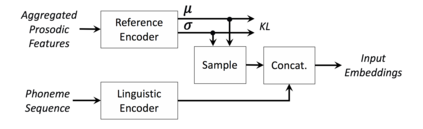
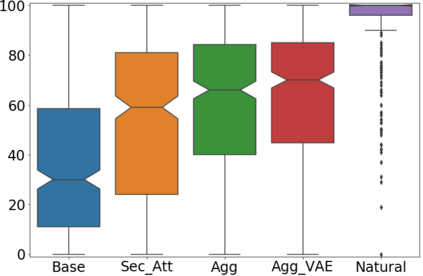
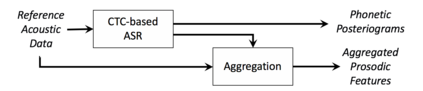
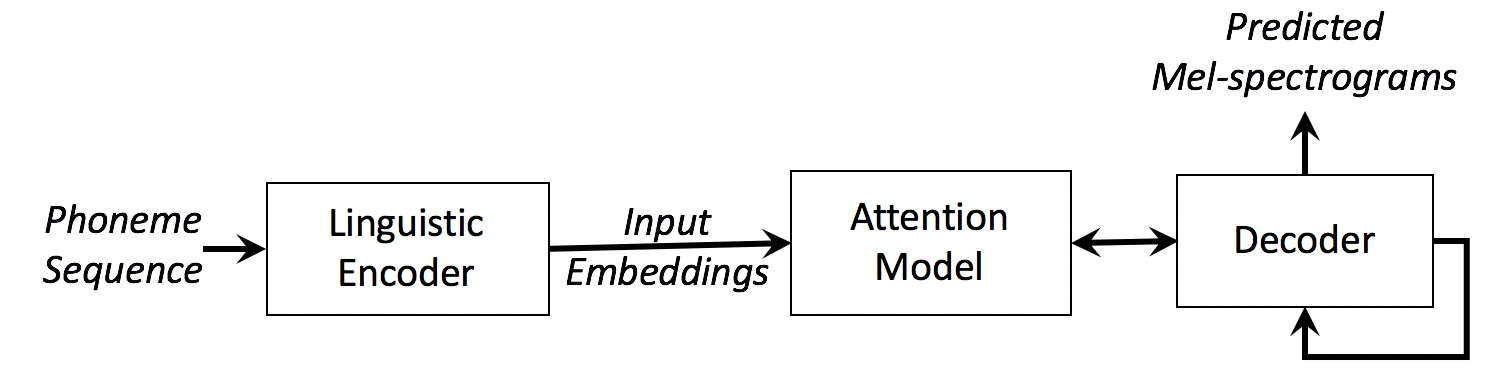
We present a neural text-to-speech system for fine-grained prosody transfer from one speaker to another. Conventional approaches for end-to-end prosody transfer typically use either fixed-dimensional or variable-length prosody embedding via a secondary attention to encode the reference signal. However, when trained on a single-speaker dataset, the conventional prosody transfer systems are not robust enough to speaker variability, especially in the case of a reference signal coming from an unseen speaker. Therefore, we propose decoupling of the reference signal alignment from the overall system. For this purpose, we pre-compute phoneme-level time stamps and use them to aggregate prosodic features per phoneme, injecting them into a sequence-to-sequence text-to-speech system. We incorporate a variational auto-encoder to further enhance the latent representation of prosody embeddings. We show that our proposed approach is significantly more stable and achieves reliable prosody transplantation from an unseen speaker. We also propose a solution to the use case in which the transcription of the reference signal is absent. We evaluate all our proposed methods using both objective and subjective listening tests.
翻译:我们提出了一个神经文本到声音系统,用于从一个发言者向另一个发言者进行微微分分辨假音传输。端到端分辨假音传输的常规方法通常使用固定的维度或多变的半衰期嵌入,通过对参考信号进行编码的二次关注进行嵌入。然而,在对单声传译数据集进行培训时,常规分解系统不够强大,不足以表达器变异性,特别是在一个隐蔽的发言者发出参考信号的情况下。因此,我们提议将参考信号与整个系统脱钩。为此,我们预先制作电话级时间戳,并将其用于每部电话的综合推进特征,将其注入一个顺序到顺序到顺序的文本到语音系统。我们采用了一个变式自动编码器,以进一步提高外观嵌入的潜伏性代表度。我们提出的方法非常稳定,并且从一个隐蔽的发言者那里可以实现可靠的分解。我们还提出了一种方法,用于使用一个既含有引用信号的转录录结果,又使用主观接收测试方法。我们提出的所有方法都进行了评估。