
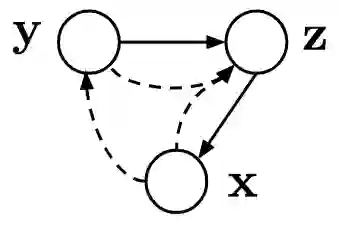
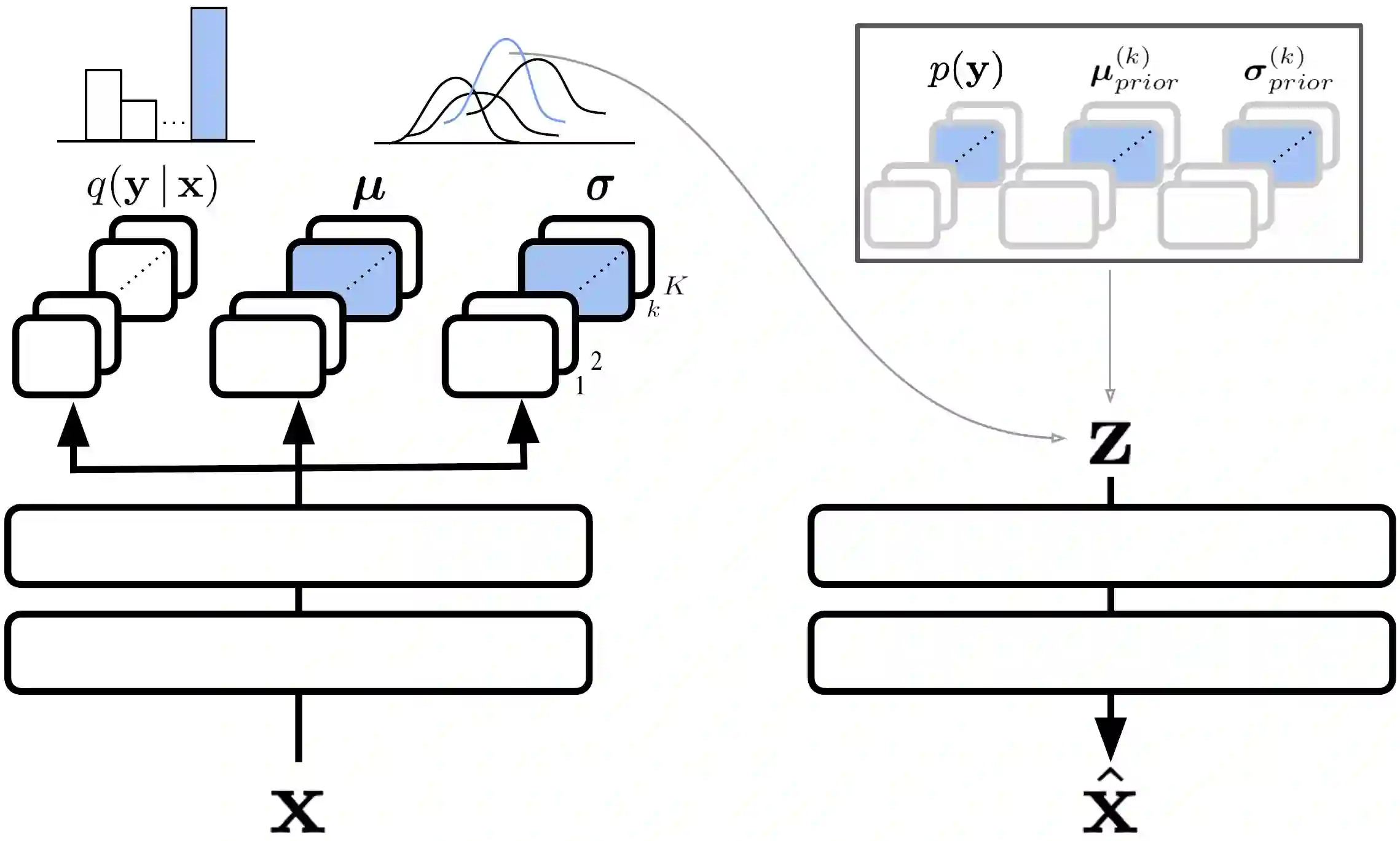
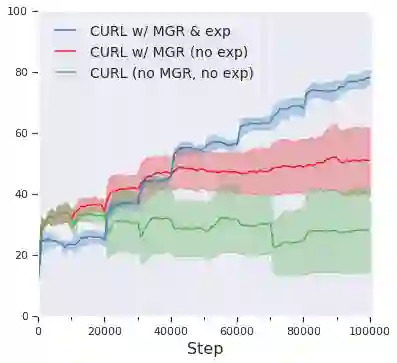
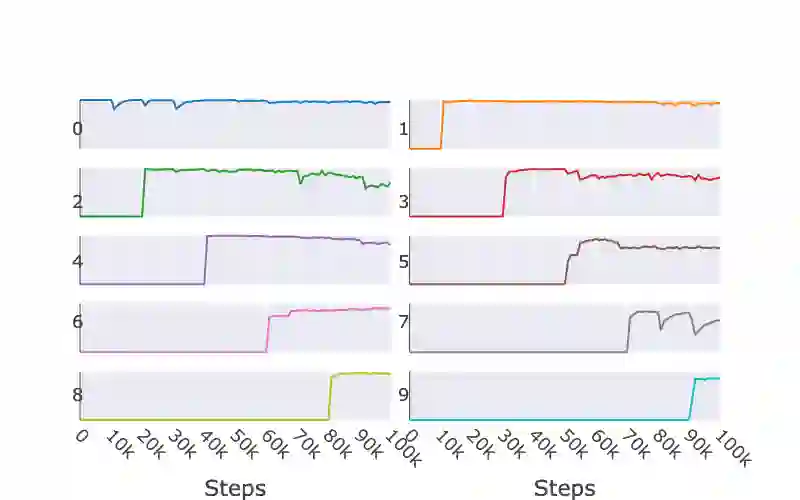
Continual learning aims to improve the ability of modern learning systems to deal with non-stationary distributions, typically by attempting to learn a series of tasks sequentially. Prior art in the field has largely considered supervised or reinforcement learning tasks, and often assumes full knowledge of task labels and boundaries. In this work, we propose an approach (CURL) to tackle a more general problem that we will refer to as unsupervised continual learning. The focus is on learning representations without any knowledge about task identity, and we explore scenarios when there are abrupt changes between tasks, smooth transitions from one task to another, or even when the data is shuffled. The proposed approach performs task inference directly within the model, is able to dynamically expand to capture new concepts over its lifetime, and incorporates additional rehearsal-based techniques to deal with catastrophic forgetting. We demonstrate the efficacy of CURL in an unsupervised learning setting with MNIST and Omniglot, where the lack of labels ensures no information is leaked about the task. Further, we demonstrate strong performance compared to prior art in an i.i.d setting, or when adapting the technique to supervised tasks such as incremental class learning.
翻译:持续学习的目的是提高现代学习系统处理非固定分布的能力,通常通过尝试按顺序学习一系列任务。实地的先行艺术基本上考虑了受监督或强化的学习任务,并且往往对任务标签和界限拥有充分的知识。在这项工作中,我们建议一种方法(CURL)来解决一个我们称之为无人监督的持续学习的更普遍的问题。重点是学习表现,对任务特性没有任何了解,我们探索任务之间发生突然变化、任务之间顺利过渡或甚至数据被打乱时的各种情景。拟议方法直接在模型内进行任务推断,能够动态扩展,在一生中捕捉新概念,并纳入更多基于排练的技术,以处理灾难性的遗忘。我们展示了CURL在与MNIST和Omniglot的未经监督的学习环境中的功效,因为缺少标签,无法确保有关任务的信息被泄露。此外,我们展示了与i.d设置或将技术调整为受监督类的渐进式学习任务相比,我们表现得很强。
相关内容

Source: Apple - iOS 8


