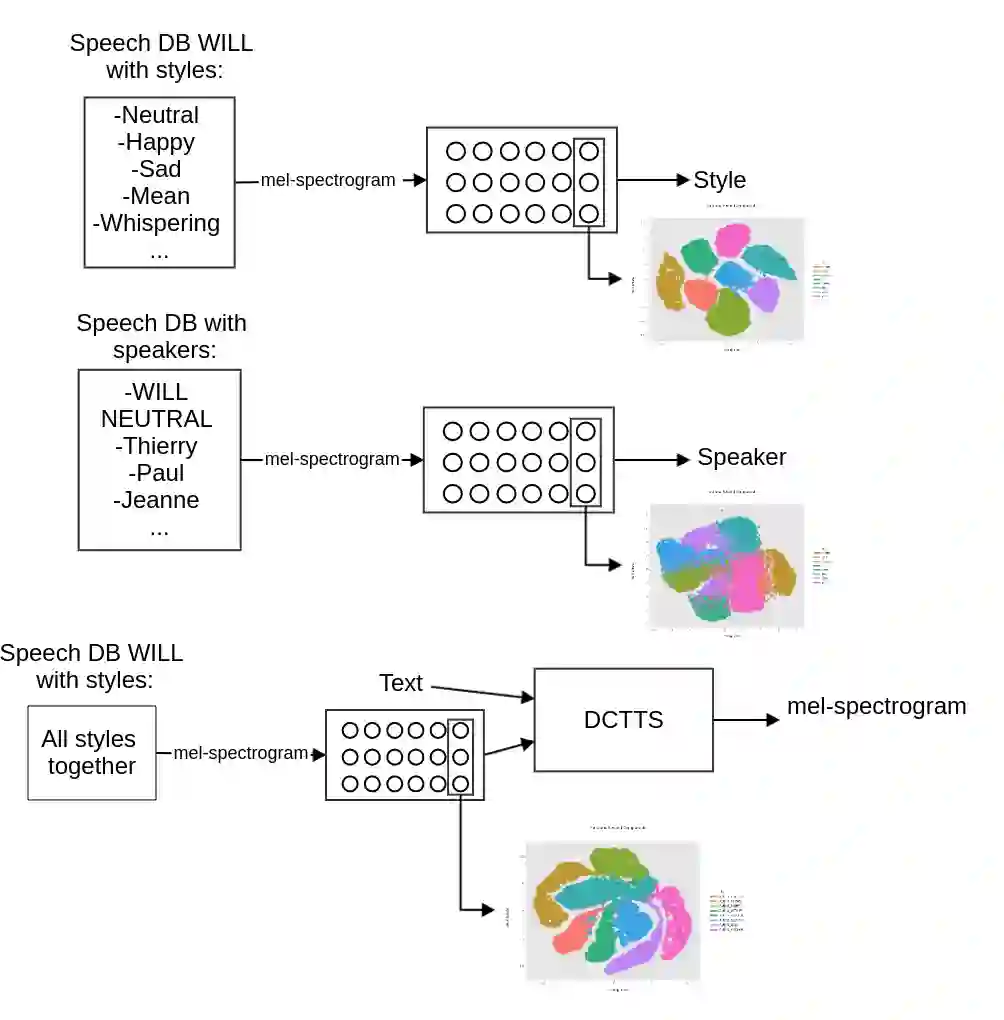
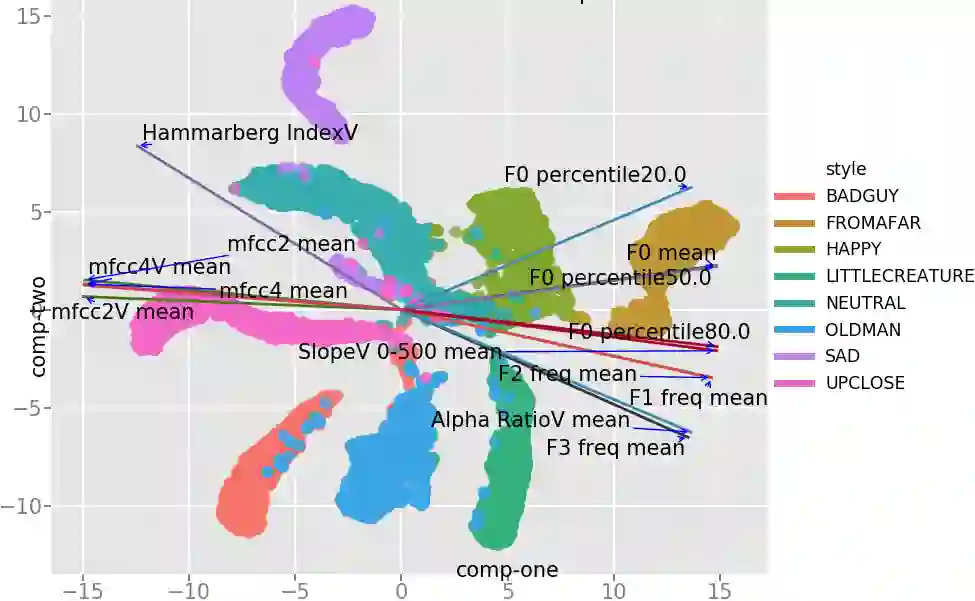
The field of Text-to-Speech has experienced huge improvements last years benefiting from deep learning techniques. Producing realistic speech becomes possible now. As a consequence, the research on the control of the expressiveness, allowing to generate speech in different styles or manners, has attracted increasing attention lately. Systems able to control style have been developed and show impressive results. However the control parameters often consist of latent variables and remain complex to interpret. In this paper, we analyze and compare different latent spaces and obtain an interpretation of their influence on expressive speech. This will enable the possibility to build controllable speech synthesis systems with an understandable behaviour.
翻译:多年来,通过深层次的学习技术,文本到语音领域有了巨大的改进。现在,可以提出现实的演讲。因此,关于控制表达力的研究,允许以不同风格或方式生成演讲,最近引起越来越多的关注。能够控制风格的系统已经开发出来,并显示出令人印象深刻的结果。但是,控制参数往往由潜在的变量组成,并且仍然很复杂,难以解释。在本文中,我们分析并比较不同的潜伏空间,并了解其对表达式演讲的影响。这将使人们有可能建立可控制的语言合成系统,并有可以理解的行为。