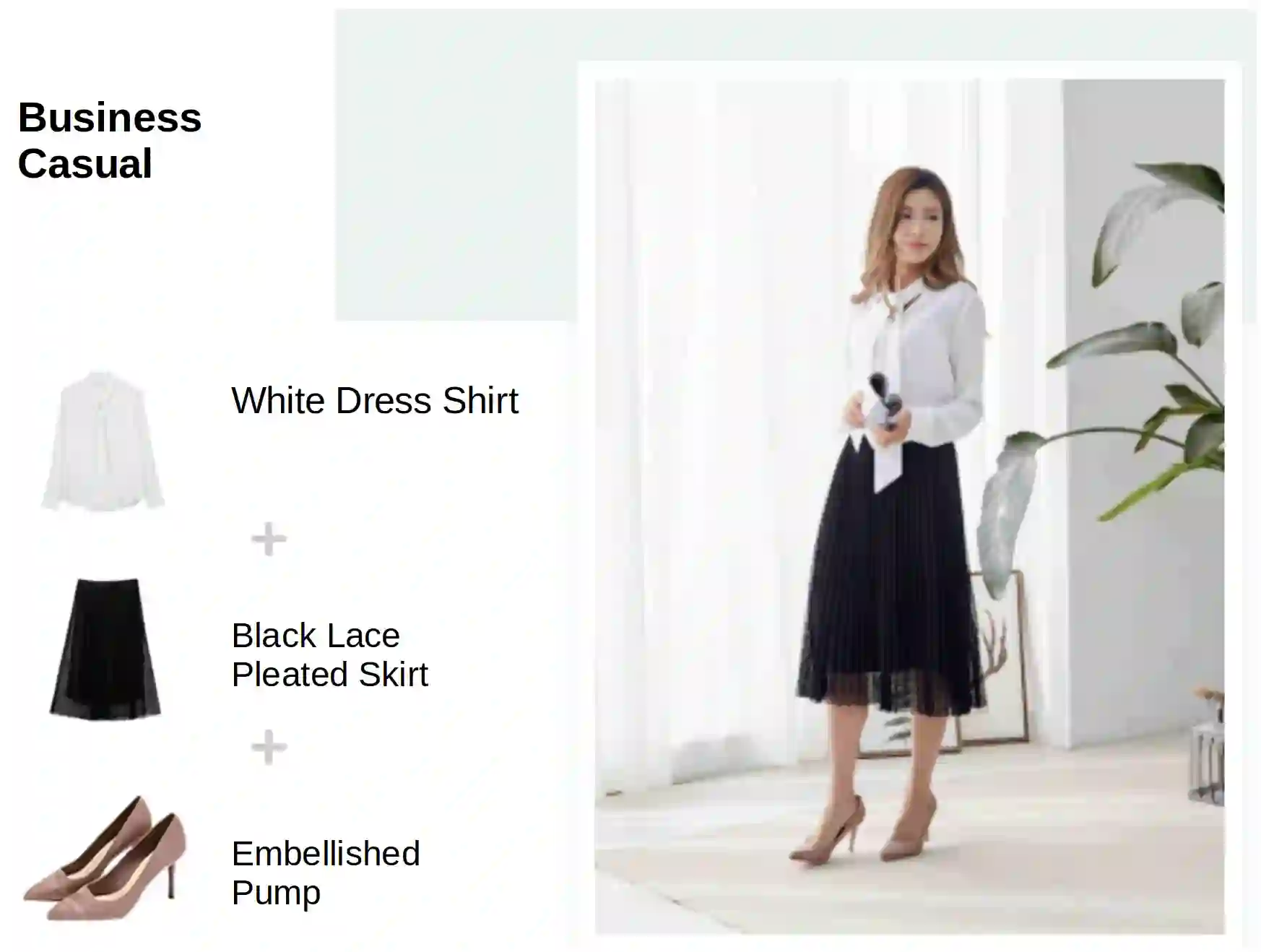
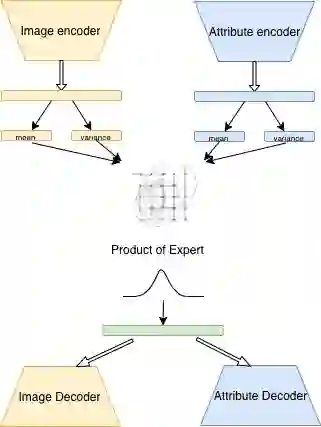
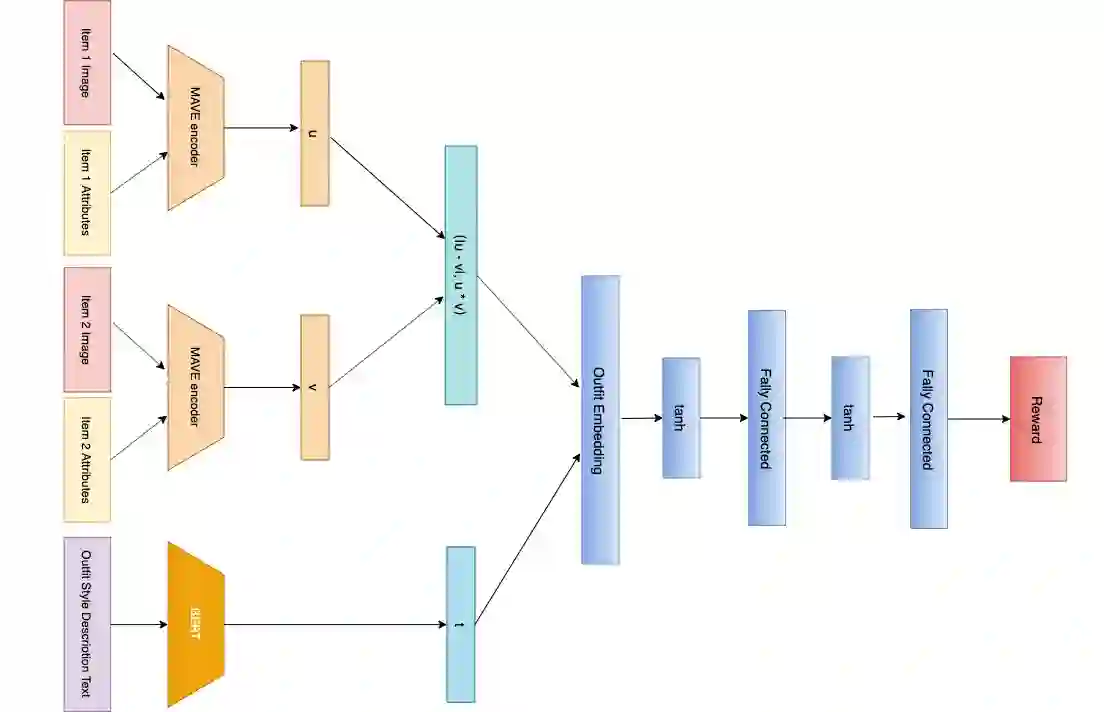
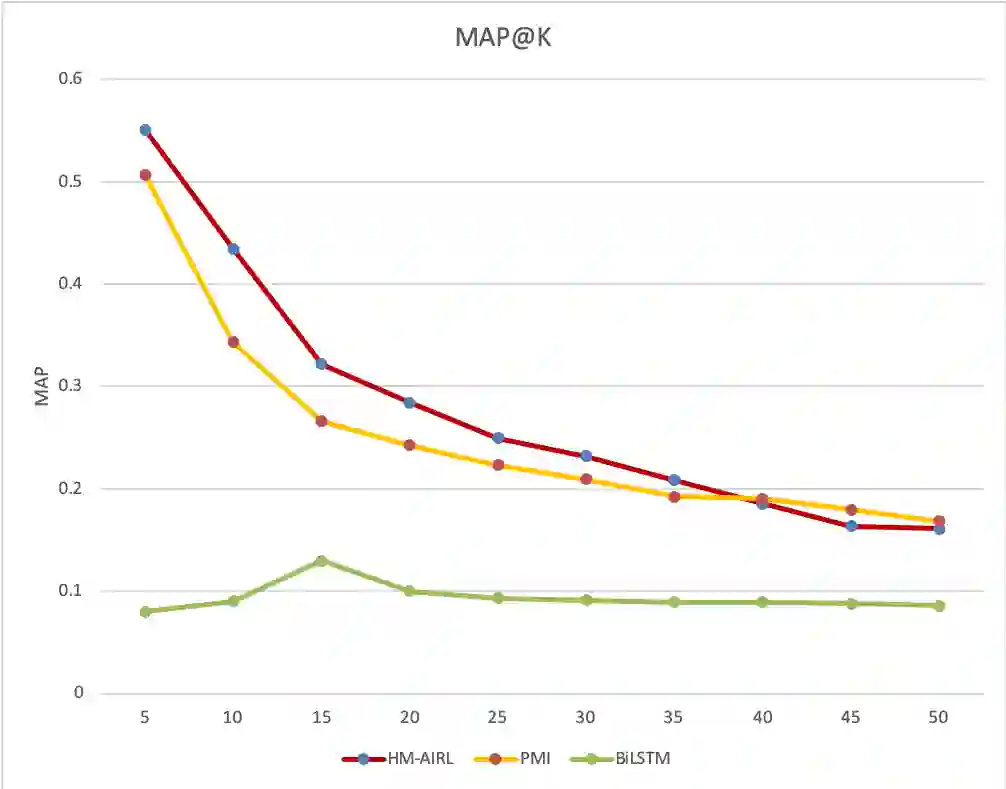
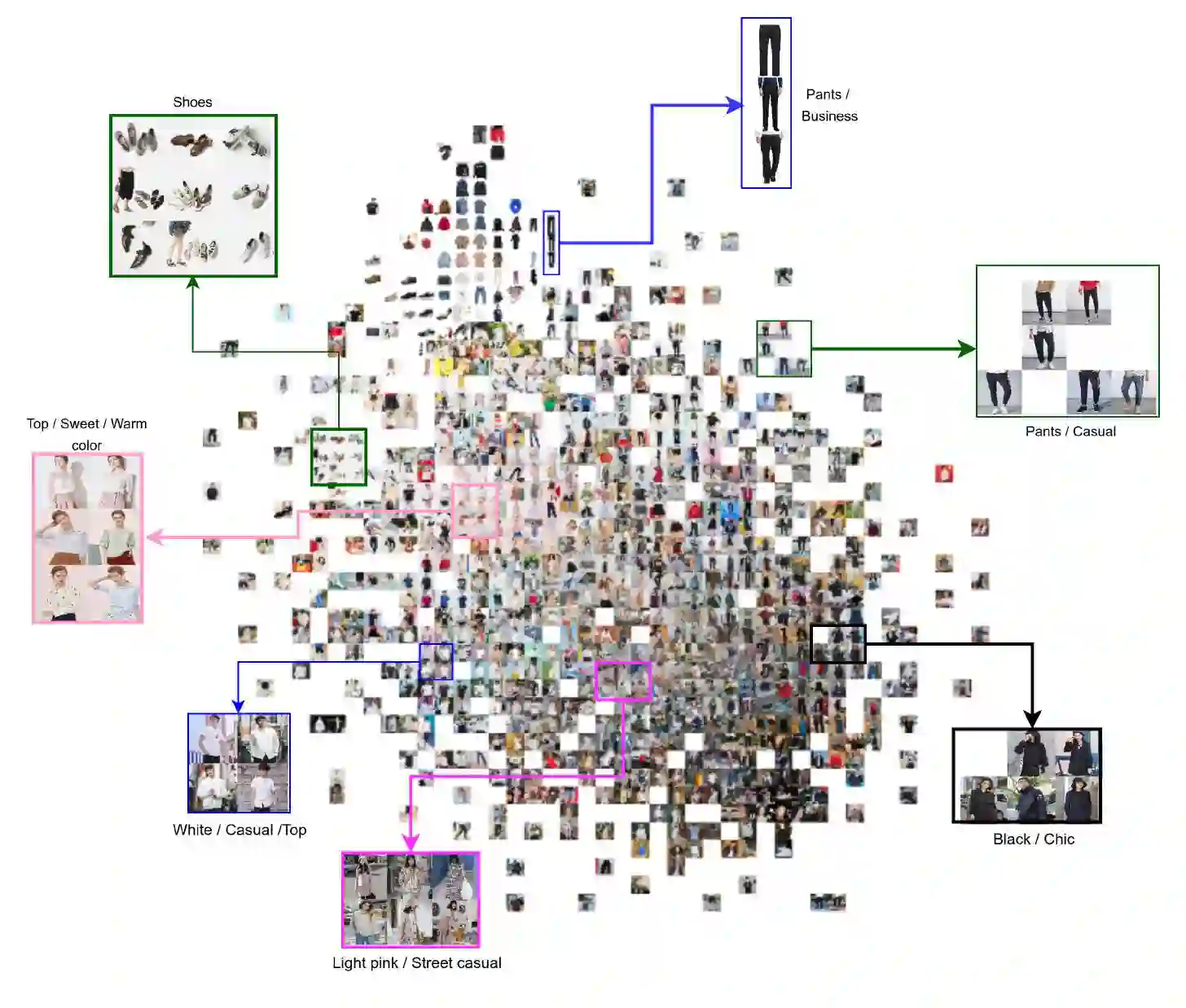
Fashion is a complex social phenomenon. People follow fashion styles from demonstrations by experts or fashion icons. However, for machine agent, learning to imitate fashion experts from demonstrations can be challenging, especially for complex styles in environments with high-dimensional, multimodal observations. Most existing research regarding fashion outfit composition utilizes supervised learning methods to mimic the behaviors of style icons. These methods suffer from distribution shift: because the agent greedily imitates some given outfit demonstrations, it can drift away from one style to another styles given subtle differences. In this work, we propose an adversarial inverse reinforcement learning formulation to recover reward functions based on hierarchical multimodal representation (HM-AIRL) during the imitation process. The hierarchical joint representation can more comprehensively model the expert composited outfit demonstrations to recover the reward function. We demonstrate that the proposed HM-AIRL model is able to recover reward functions that are robust to changes in multimodal observations, enabling us to learn policies under significant variation between different styles.
翻译:时装是一种复杂的社会现象。 人们从专家或时装图标的演示中遵循时装风格。 但是,对于机器代理人来说,学习模仿示威时装专家可能具有挑战性,特别是在具有高度、多式观测的环境中,对于复杂的时装专家来说尤其如此。关于时装构成的大多数现有研究都利用监督的学习方法来模仿时装图标的行为。这些方法受到分配变化的影响:由于代理人贪婪地模仿某些特定时装演示,由于微妙的差别,它可能从一种时装演示转移到另一种时装。在这项工作中,我们建议采用对抗性的反向强化学习公式,以便在模仿过程中根据等级多式代表制(HM-AIRL)恢复奖励功能。等级联合代表可以更全面地模拟专家综合服装演示以恢复奖励功能。我们证明拟议的HM-AIRL模型能够恢复对多式观测变化具有强大力的奖励功能,从而使我们能够在不同的模式下学习政策。