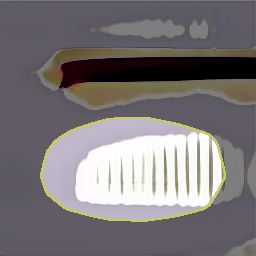
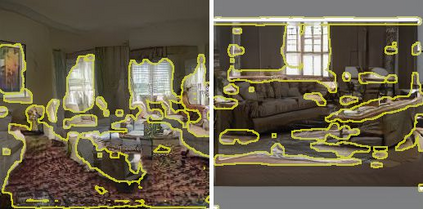
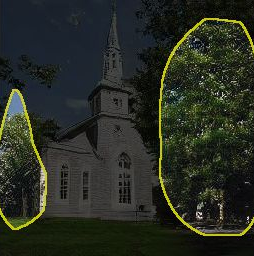Generative Adversarial Networks (GANs) have recently achieved impressive results for many real-world applications, and many GAN variants have emerged with improvements in sample quality and training stability. However, they have not been well visualized or understood. How does a GAN represent our visual world internally? What causes the artifacts in GAN results? How do architectural choices affect GAN learning? Answering such questions could enable us to develop new insights and better models. In this work, we present an analytic framework to visualize and understand GANs at the unit-, object-, and scene-level. We first identify a group of interpretable units that are closely related to object concepts using a segmentation-based network dissection method. Then, we quantify the causal effect of interpretable units by measuring the ability of interventions to control objects in the output. We examine the contextual relationship between these units and their surroundings by inserting the discovered object concepts into new images. We show several practical applications enabled by our framework, from comparing internal representations across different layers, models, and datasets, to improving GANs by locating and removing artifact-causing units, to interactively manipulating objects in a scene. We provide open source interpretation tools to help researchers and practitioners better understand their GAN models.
翻译:生成的Adversarial 网络(GANs)最近在许多现实世界应用中取得了令人印象深刻的成果,许多GAN变量随着样本质量和训练稳定性的提高而出现。 但是,这些变量还没有被很好地想象或理解。 一个GAN如何代表我们的内部视觉世界? GAN 的结果是什么原因? 建筑选择如何影响GAN 的学习? 回答这些问题可以使我们开发新的洞察力和更好的模型。 在这项工作中,我们提出了一个分析框架,以便在单位、对象和场景一级将GAN进行视觉化和理解。我们首先确定一组可解释的单位,这些单位与使用分解网络解法的物体概念密切相关。 然后,我们量化可解释单位的因果关系,通过测量控制输出对象的物体的干预能力,我们通过将发现的物体概念插入新的图像来检查这些单位及其周围之间的关联关系。 我们展示了我们的框架所促成的一些实际应用,从比较不同层次、模型和数据集的内部表现,到改进GAN的GAN,通过定位和删除其解释工具来提供更好的分析工具。