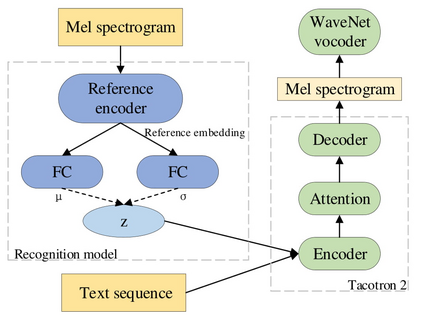
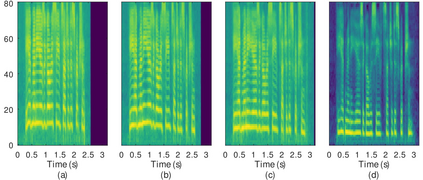
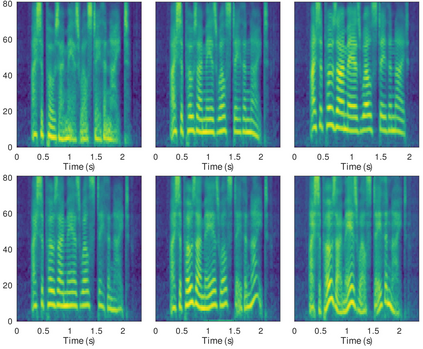
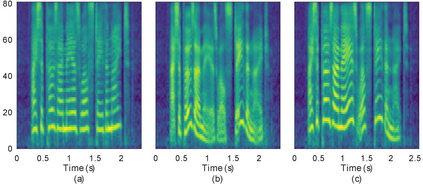
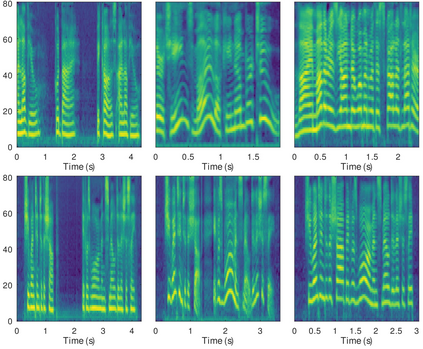
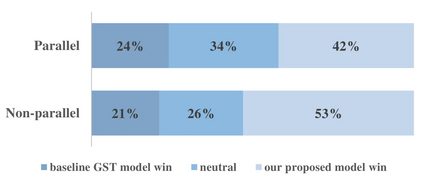
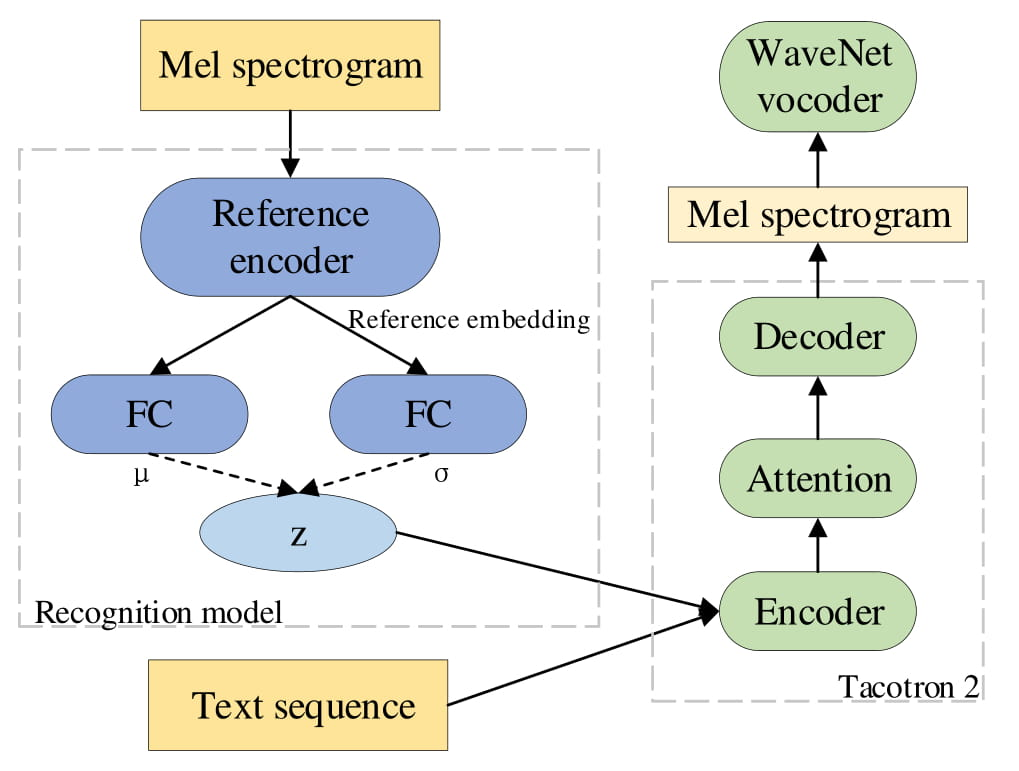
In this paper, we introduce the Variational Autoencoder (VAE) to an end-to-end speech synthesis model, to learn the latent representation of speaking styles in an unsupervised manner. The style representation learned through VAE shows good properties such as disentangling, scaling, and combination, which makes it easy for style control. Style transfer can be achieved in this framework by first inferring style representation through the recognition network of VAE, then feeding it into TTS network to guide the style in synthesizing speech. To avoid Kullback-Leibler (KL) divergence collapse in training, several techniques are adopted. Finally, the proposed model shows good performance of style control and outperforms Global Style Token (GST) model in ABX preference tests on style transfer.
翻译:在本文中,我们向一个端到端语音合成模型介绍“变式自动编码器”,以便以不受监督的方式学习语音风格的潜在表达方式。通过“变式自动编码器”所学的风格表达方式显示了良好的特性,例如脱钩、缩放和组合,这便于样式控制。在这个框架内,可以通过“变式自动编码器”的识别网络,首先推断样式表达方式,然后将其输入“TTS”网络,以引导合成语言的风格。为了避免“KL”在培训中出现“KL”差异,采用了几种技术。最后,拟议的模式展示了风格控制的良好性能,并在“ABX”风格转让测试中优于“GST”模式。