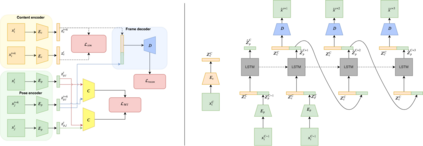
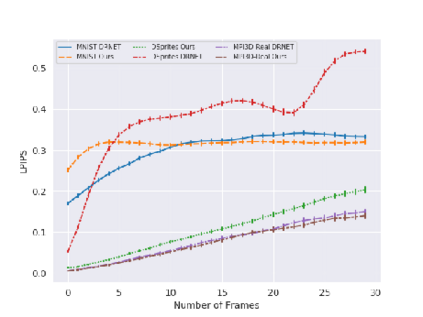
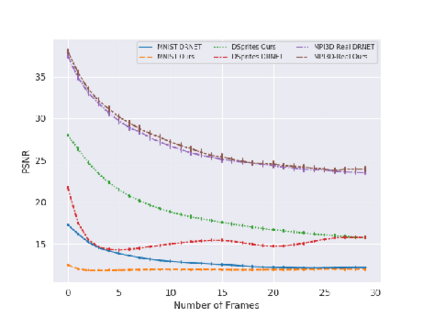
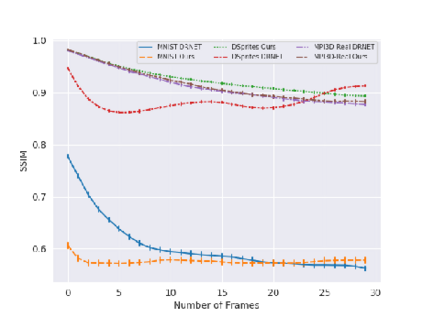
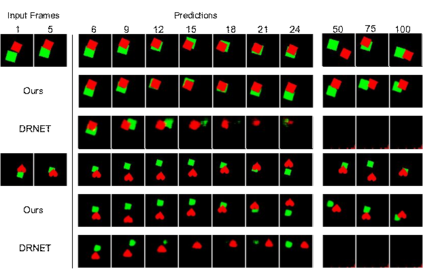
Video Prediction is an interesting and challenging task of predicting future frames from a given set context frames that belong to a video sequence. Video prediction models have found prospective applications in Maneuver Planning, Health care, Autonomous Navigation and Simulation. One of the major challenges in future frame generation is due to the high dimensional nature of visual data. In this work, we propose Mutual Information Predictive Auto-Encoder (MIPAE) framework, that reduces the task of predicting high dimensional video frames by factorising video representations into content and low dimensional pose latent variables that are easy to predict. A standard LSTM network is used to predict these low dimensional pose representations. Content and the predicted pose representations are decoded to generate future frames. Our approach leverages the temporal structure of the latent generative factors of a video and a novel mutual information loss to learn disentangled video representations. We also propose a metric based on mutual information gap (MIG) to quantitatively access the effectiveness of disentanglement on DSprites and MPI3D-real datasets. MIG scores corroborate with the visual superiority of frames predicted by MIPAE. We also compare our method quantitatively on evaluation metrics LPIPS, SSIM and PSNR.
翻译:视频预测是一项有趣的、具有挑战性的任务,即从属于视频序列的设定背景框架中预测未来框架。视频预测模型发现,在Maneuver规划、保健、自动导航和模拟中,未来框架生成过程中的潜在应用是高维的视觉数据造成的。在这项工作中,我们提议了相互信息预测自动摄像(MIPAE)框架,通过将视频显示纳入内容和低维构成易于预测的潜在变量,减少预测高维视频框架的任务。使用标准的 LSTM 网络来预测这些低维的显示表层。内容和预测的表示面被解码以生成未来框架。我们的方法利用视频潜在基因化因素的时间结构以及新颖的相互信息损失来学习分解的视频表述。我们还提议了一个基于共同信息差距的衡量标准,以量化的方式获取DSprite上的混乱和MPI3D的隐含变量的有效性。MIG的评分数与MIPIS预测的框架的直观优越性比,我们还比较了我们关于MIPIS的定量方法。