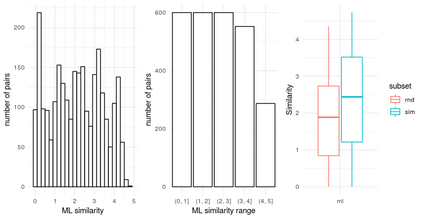
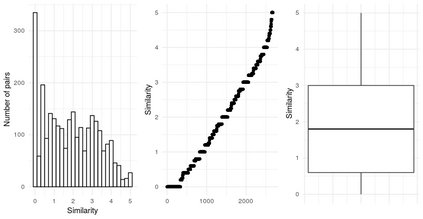
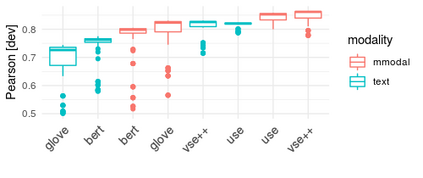
The combination of visual and textual representations has produced excellent results in tasks such as image captioning and visual question answering, but the inference capabilities of multimodal representations are largely untested. In the case of textual representations, inference tasks such as Textual Entailment and Semantic Textual Similarity have been often used to benchmark the quality of textual representations. The long term goal of our research is to devise multimodal representation techniques that improve current inference capabilities. We thus present a novel task, Visual Semantic Textual Similarity (vSTS), where such inference ability can be tested directly. Given two items comprised each by an image and its accompanying caption, vSTS systems need to assess the degree to which the captions in context are semantically equivalent to each other. Our experiments using simple multimodal representations show that the addition of image representations produces better inference, compared to text-only representations. The improvement is observed both when directly computing the similarity between the representations of the two items, and when learning a siamese network based on vSTS training data. Our work shows, for the first time, the successful contribution of visual information to textual inference, with ample room for benchmarking more complex multimodal representation options.
翻译:视觉和文字代表的结合在图像说明和视觉问题解答等任务中产生了极好的结果,但多式联运代表的推论能力在很大程度上尚未测试。在文字代表方面,常常使用文字零售和语义文字相似性等推论任务来衡量文字表述的质量。我们研究的长期目标是设计提高当前推断能力的多式联运代表技术。因此,我们提出了一个新颖的任务,即视觉语义相似性(VSTS),可以直接测试这种推论能力。鉴于由图像及其附带标题构成的两个项目,VSTS系统需要评估背景说明与对方相等的内涵程度。我们使用简单的多式联运代表的实验表明,增加图像表述会比仅文字表述更能产生更好的推导力。在直接计算两个项目的表述的相似性时,以及在学习基于VSTS培训数据的硅网络时,我们的工作首次显示,图像信息与图像文本的复杂比重性展示了比重的复杂比例。