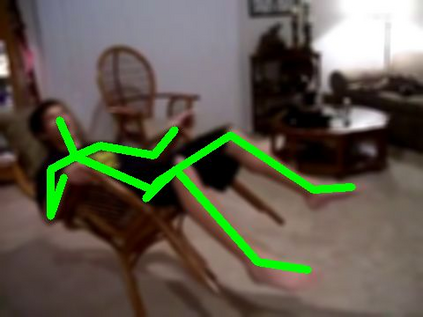
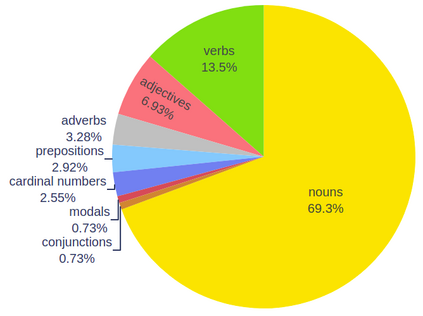
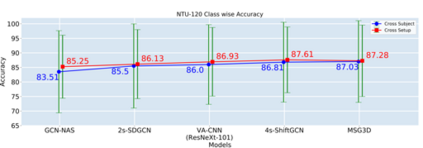
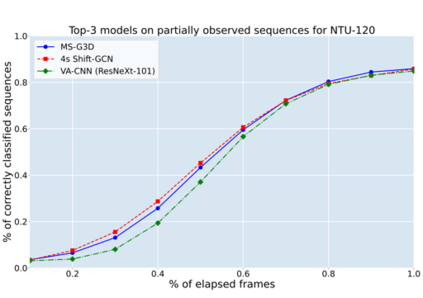
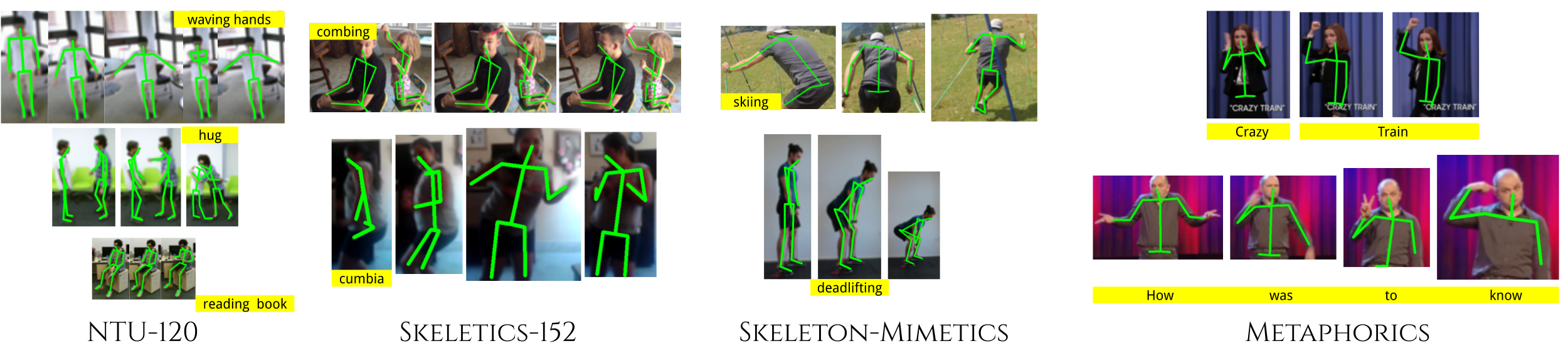
In this paper, we study current and upcoming frontiers across the landscape of skeleton-based human action recognition. To study skeleton-action recognition in the wild, we introduce Skeletics-152, a curated and 3-D pose-annotated subset of RGB videos sourced from Kinetics-700, a large-scale action dataset. We extend our study to include out-of-context actions by introducing Skeleton-Mimetics, a dataset derived from the recently introduced Mimetics dataset. We also introduce Metaphorics, a dataset with caption-style annotated YouTube videos of the popular social game Dumb Charades and interpretative dance performances. We benchmark state-of-the-art models on the NTU-120 dataset and provide multi-layered assessment of the results. The results from benchmarking the top performers of NTU-120 on the newly introduced datasets reveal the challenges and domain gap induced by actions in the wild. Overall, our work characterizes the strengths and limitations of existing approaches and datasets. Via the introduced datasets, our work enables new frontiers for human action recognition.
翻译:在本文中,我们研究基于骨骼的人类行动认知的地貌的当前和即将到来的边界。为了研究野生的骨架行动识别,我们引入了Sleetictics-152,一个由“动因-700”组成的大规模行动数据集,根据“动因-700”提供的RGB视频集集集集整理和3D“3-D”附加说明。我们扩展了我们的研究,通过引入由最近推出的“模拟数据集”产生的数据集,包括了“超脱脂行动”。我们还引入了“Memetics”数据集,这是一个带有流行的社会游戏“哑剧”和解释性舞蹈表演的注解的YouTube视频的插图式数据集。我们在NTU-120数据集上对最新版“NTU-120”的顶级表演者基准测试结果进行基准评估,揭示了野生行动带来的挑战和领域差距。总体而言,我们的工作体现了现有方法和数据集的优势和局限性。通过引入的数据集,我们的工作为人类行动提供了新的前沿。